传媒教育网
标题: 数据新闻案例集锦 [打印本页]
作者: admin 时间: 2013-12-8 17:17
标题: 数据新闻案例集锦
大数据时代,新闻的线索和真实需要数据的帮助。我们开辟新的案例,旨在让大家了解数据与新闻的关系。
【案例】
苏州郎心铁
我的祖国。
◆◆
@好火药
看看你的窗外,等他们敛够财移完民,把这块土地一点点变成狼藉的地狱,你再说什么都晚了,只能看着你的孩子们去承受后果,看看窗外的世界,我们不要苟活…
收起|查看大圖|向左轉|向右轉
(3)|
轉發(10)
|
評論(6)
9分鐘前來自iPhone客户端
|
轉發(1)|
收藏|
評論
8分鐘前
來自新浪微博
作者: admin 时间: 2013-12-11 09:00
本帖最后由 admin 于 2013-12-11 09:03 编辑
【案例】
中国调查人体尺寸数据 包括5大类200多项(全文)

“中国成年人工效学基础参数调查”启动

“中国成年人工效学基础参数调查”启动
座椅要多高坐着才舒服?药盒上的字体多大看着才清晰?服装鞋帽的尺码号型该如何确定?这些与日常生活息息相关的设计,都有赖于人类工效学基础数据的采集分析。经科技部批准设立的、国家科技基础性工作专项“中国成年人工效学基础参数调查”工作日前启动,计划于2018年完成。这标志着人性化产品和环境设计所需的中国人体数据调查开始实施。本报特约请参与此次调查的专家,向公众讲解相关知识。
人类工效学就是根据人的心理、生理和身体结构等因素,研究人、机、环境相互间的合理关系,为产品和环境的人性化设计提供技术和数据支持,以营造安全、健康、舒适、高效的工作生活环境。
作为20世纪50年代迅速发展起来的一门新兴的边缘学科,人类工效学的基础参数主要由人体形态、人体力学和人体感知(视、听、触)等各类与消费品、服装、工具、设备和环境设计相关的人体特性参数组成,是从工业设计的角度对特定人群生理、心理特征整体状况的科学描述。
座椅要多高?把手安在哪儿?
人体数据与产品设计息息相关
人类工效学基础参数与工业设计和社会生产、生活息息相关,它的应用几乎涉及了人类活动的大部分领域。例如:座椅要多高,大多数人坐着才舒服?药盒上的字体多大,老人才能看清楚?服装号型中身高和腰围的比例是多少,才能适体?这些与日常生活息息相关的设计,都有赖于人类工效学基础数据的采集分析。
例如,汽车座椅设计需要坐高、腿长、脊柱弯曲等人体尺寸数据,冰箱把手设计需要手指长短、粗细等数据。地铁刷票机设计需要人群的身高、臂长等数据,地铁上的拉手要符合成年人够得着的高度。交通标识与显示器的设计适合人的视觉特性,紧急指示牌应摆在显眼的位置等等。
用中国人的数据才能设计和生产出适合中国人的产品。根据人类工效学基础参数调查数据,可以得出中国人某项指标分布特点,告诉设计师什么尺寸适合最多的中国人。例如,由于缺乏中国人头型数据,眼镜企业生产的眼镜中不适合中国人头型的比例就比较大,极易造成货品严重积压。
人群的工效学基础数据与人种、区域、文化、经济社会发展水平等因素密切相关,具有显著的地区和文化差异。中国人与欧美人无论是在人体形态上、力量上,还是感知特征上都有一定的差异。例如:亚洲人头型圆,欧洲人头型扁,如果根据欧洲人的头模设计头盔、眼镜等产品,安全和舒适效果会大打折扣。中国成年人的臂长比德国人的臂长要短6至8厘米,躯干长均比德国人短6至9厘米,以欧美人的人体特征数据设计的汽车,其驾驶椅坐高不适合中国人的人体特征,身材矮小的女性在驾驶汽车时,会感觉不合适,不是方向盘离得远,就是脚踏不上离合器,看不到仪表盘的实时情况,会造成极大安全隐患。
175厘米男士要买180厘米衣服
近30年无数据更新造成很多空白
我国最早的一次全国规模的人体测量工作是在1986至1987年,中国标准化研究院在全国16个省市,采用直尺、马丁测量仪等手工测量技术对22000多成年人(18至60岁)进行了人体测量,采集了包括身高、腰围、臀围、足长、体重、握力等73项工效学基础数据,在此基础上发布了我国成年人人体尺寸的系列国家标准,提供了我国成年人人体尺寸的基础数值。该标准已经成为服装、家具、汽车等许多行业领域技术标准的基础标准。
人体尺寸数据具有较强的时效性,一般每10年就需修订一次,而我国现有成年人人体尺寸数据采集于1986年,近30年来,我国人民生活水平有了质的飞跃,身体体型发生了巨大变化,现有的成年人人体数据已无法准确反映当前我国国民的身体状况。2009年,中国标准化研究院曾采集了3000份中国成年人三维人体尺寸,发现中国人尤其是35岁以上人群明显变胖,成年男子身高增加2厘米、腰围增加5厘米。依据1986年采集的中国人体尺寸数据设计的服装显然不能很好适合现代人体型,这就是为什么有些身高175厘米的男士购买180厘米的衣服似乎更合身一些,因为有的服装尺码标准参考的还是20多年前的人体尺寸数据。
目前,我国工效学基础参数数据缺失严重,我国成年人人体尺寸数据已严重滞后,力量、视觉、听觉等工效学基础参数数据基本空白,已严重影响到我国工效学研究和应用,以及工业设计水平的发展和人们生活质量的提高。
15秒钟几个动作搞定尺寸
人体扫描技术大大降低调查难度
本次工效学基础数据调查工作,将以18至75岁的中国成年人为对象,将全国区域划分为6个区,每个区内抽取4至6个测量点,在全国范围内测量和调查2万多个样本(人)。
与1986年的调查相比,此次调查除了人体尺寸参数从74项增加到120多项外,还将测量人体肌肉力量、视觉敏感度、声音敏感度、指端触觉等新项目,甚至还新增了腹厚的测量,这将为椅子和沙发的设计者提供更细致的数据。
本次人体测量将采用国际最先进的三维人体扫描技术,相比于传统的手工人体测量手段,具有许多技术优点。例如,三维人体扫描现场测量速度快,效率高,强度低,精度易控。传统手工测量耗时长,往往需要一支庞大的测量队伍。每名测量员一天中上下起立多达上百次,极易因疲劳而影响精度。而三维人体测量系统一次扫描时间不超过15秒,人体尺寸提取工作由计算机自动完成,人员培训相对简单。三维人体扫描能够提供完整的人体三维数据,可提供各种身体曲面、截面的特征,可直接用于产品的三维数字化设计,而手工测量只能获得一维人体尺寸。三维扫描人体数据再利用性高,手工测量结束后不可能加测新的数据项,而三维人体测量则由于保存了被测者完整的人体三维扫描图像,随时可以调出原始数据,测量新的项目。
我们的调查数据,会告诉产品设计者中国人某项指标分布特点,告诉设计师什么尺寸适合最多的中国人。比如,企业知道成年男子的腰围增加了,皮带打眼儿的位置就会变化,衬衫的胸围和腰围的比例也会发生变化;同样,西裤在设计时,在腰围和臀围的尺码设计上也会更为合理。此次调查工作完成后,将会提供中国人的基础数据,甚至细致到“女性打开冰箱门需要使用的力量参数”。
延伸阅读
调查人体数据包括5大类200多项
以此次调查来说,每个被试者将被采集和测量包括形态、力学、视觉、听觉、触觉5大类共200多项的人体工效学基础数据。
形态参数—人在静止状态下,对人体形态进行的各种测量得到的人体结构参数。人体测量姿势主要有立姿和坐姿,包括身高、眼高、腰围等立姿测量项目,坐高、坐深、膝高等坐姿测量项目,以及头面部、手部和足部尺寸等。人体尺寸数据是产品外形和空间布局设计的基本技术依据。
力学参数—人体各类动力学和运动学参数,主要包括人体关节活动度(颈、肩、肘、髋、腕、膝、踝、手指等的活动角度)、不同操作姿势和角度下的推力、拉力、提力、蹬踏力、握力、捏力、拉力、按压力、拧力等。人体力学参数是设计机械设备的操纵系统所必需的基础数据。
视觉参数—人机界面设计所需的视觉特性参数,主要包括视距、视敏度、视野等。视觉参数可为显示器、图形符号的设计提供依据。
听觉参数—人体对声音信号的听觉感知特性参数,主要包括声音信号的声压级和频率,以及听力阈值等,听觉参数是音响、广播等听觉显示器和建筑物声学设计的基础参数。
触觉参数—皮肤受到机械刺激而引起的感觉特性参数,包括触觉的空间感知阈值和字符感知阈值等,触觉参数将为操控器等的设计提供数据依据。
(作者为中国标准化研究院研究员)
http://news.163.com/13/1211/02/9FPHT56M00014AED_all.html#p1
作者: admin 时间: 2013-12-11 09:18
【案例】
阅读提示:这份近期在委内瑞拉举行的数据新闻训练营的报告(全英)供大家参考。已上传。报告详细介绍了一些数据新闻报道思路及实例、数据新闻常用的工具等等。这篇报道也说明数据新闻在发展中国家的应用更有必要呀!
Paving the way for data journalism in a divided Venezuela
12/6/13 by Miguel Paz
In a country split by political polarization, what role can journalism and the use of data play in improving the quality of debate in the public interest?
file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/ksohtml/wps_clip_image-20147.pngThis is an important question in Venezuela, a country in which President Nicolás Maduro claims to speak to the late President Hugo Chavez’s spirit through a "little bird" and has created a Ministry of Ultimate Bliss.
Meanwhile, the most extreme opposition party burns Cuban flags and labels the president a new “Pinochet.”
Data journalism can play an important role there. It can provide new technological capabilities to journalists, programmers and designers, providing greater support for the facts and redefining how people in news work both collectively and individually.
Those were my takeaways from the recent and first-ever
Data Journalism Bootcamp in Venezuela in Caracas. About 100 professionals, chosen from 250 applicants, attended the three-day camp002E
Widespread interest in the event can be explained by the need of applicants and participants to accelerate their skills and technological capabilities in using data and to integrate interdisciplinary work methodologies into their daily routines.
Key tools for web scraping, open data and interactive storytelling
There was also a mini hackathon. Attendees proposed projects and became familiar, for the first time in their professional lives, with rapid prototyping techniques, visual thinking and tech entrepreneurship concepts like elevator pitches, minimum viable products and agile work organization. The 40 ideas proposed reflect the interest in using data to bring transparency to many of the current complexities in Venezuela. (You can check them all out on the event's
dashboard.) Of these, 10 projects were brought to life, using tools like:
·
JavaScript visualization libraries
Miso and
RawElections, baseball and more
Among the noteworthy projects were
"Camino al 8D," a chart and comparative timeline of ratings and mayors elected in Venezuelan elections from 2000 to the present. This project, created ahead of Venezuela’s municipal elections December 8, used a public database to plot the curves of growth and decrease in the number of votes for the official party versus the opposition party.
Another successful project, focused on baseball, the national sport of Venezuela, was
"Chamos Peloteros" from the programming team of
Cadena Capriles media group. The project extracted a database of information about Venezuelan players in minor league baseball in the United States and explored their demographic characteristics, such as average age, place of origin in Venezuela, signing bonus amount and the positions they play.
Thanks to the practice they received at the bootcamp, Cadena Capriles chief web developer Asdrubal Chirinos
said, his team won the Venezuelan version of
America’s Datafest and will advance to the global competition. (Review the pitch
here.)
There were those who used the Bootcamp to organize large databases, such as the thousands of unionized journalists at the country’s College of Journalists. Others used featured tools to perform basic prototypes that they’ll continue using in their jobs, to reveal patterns and connections in subjects like the influence of the Monsanto Corporation in Latin America; radiation therapy; the Bolivarian Armed Forces and Venezuelan migration.
The heart of the boot camp, according to the results of a survey sent to participants (in which the majority indicated that the activity "Exceeded their expectations”) was learning to work in interdisciplinary teams, learning new tools and developing an understanding of how to use large data sets to investigate and tell news stories, under the journalism aphorism, "If your mother tells you she loves you, check it out."
Opinion versus facts
During the present moment in the political life of Venezuela, "truth" seems to be the first victim of polarization. This polarization has permeated many areas of debate and analysis with concepts such as
"economic war." Into this atmosphere, the boot camp has served to promote and emphasize research techniques based on empirical verification of data and the practice of quality journalism.
Who is telling the truth? How do we check? What distinguishes the truth of an opinion coming from the highest echelons of power or a statement dressed in fact collected from gossiping opponents? How do we deal with opinions stated as fact and insist upon hard and verifiable data? These were open questions discussed during the meeting. This was especially true on the third day of the meeting, when a smaller group of professionals from the world of investigative journalism analyzed the legal limitations to the free exercise of journalism and learned in detail how to use Poderopedia to map the connections of the political and business elite in Venezuela.
Based on the interest we’ve encountered in the platform in Venezuela, we plan to
launch a Poderopedia chapter in the country in the coming months.
Finding stories buried in government PDFs
Another great outcome of the bootcamp was an investigation into the companies authorized by the Venezuelan government to exchange bolivars to dollars in order to buy products for import into Venezuela.
Journalists in Venezuela frequently consult the government's documents on how many bolivars a company has been allowed to exchange to dollars by CADIVI (Venezuelan Foreign Exchange Administration Commission, which is responsible for exchange control). But no one had yet taken a comprehensive look at which are the top 20 companies authorized to accept dollars and exactly how much money they are receiving.
Using what he learned at the boot camp, journalist Cesar Batiz took a hard copy of the file and turned it into a searchable database. With the help of María Esther Vidal, a professor at Simón Bolívar University, he made a ranking of the list of companies approved by the CADIVI to exchange bolivars to dollars over the limit permitted by the authorities. The investigation, published in the newspaper Últimas Noticias, highlighted the case of Tiendas Daka, a retail company the government has accused of illegally marking up the prices of imported appliances.
The investigation revealed the names of the company’s owners, information about its operations in Panama, as well as its electoral [official] address in Venezuela. The company was also among the top 20 companies that received U.S. dollars.
Thanks to the tools Batiz acquired at the boot camp, an important economic story is being told and new ways of getting answers from data are being used to reveal potential corruption to the Venezuelan public. I look forward to hearing about and sharing how other journalists are using their new skills in the months to come.
Miguel Paz is a Chilean journalist and founder and CEO of Poderopedia, a data journalism website that highlights links among Chile’s business and political elites. Read about his Knight Fellowship here. This post was originally written in Spanish and translated into English by Jessica Weiss.
Image of the IPYS bootcamp courtesy of Miguel Paz.
作者: admin 时间: 2013-12-11 11:47
【案例】
李靖云
这个才叫“以人为本”。//@高明勇: 人在哪里,公共服务就可以据此跟随到哪里,而非让流动人口为了一个个证件而来回折腾。
◆◆
@新京报评论
【@高明勇
:异地办生育证,难在缺“数据”吗?】流动人口办准生证难,这些年舆论诟病不少,如果真要拖到7年后才“有望实现”,那就太久了。这个老大难问题,为什么久拖不决,真的是缺乏“数据”吗?一个能够真正融合所有必要公民信息的“一卡通”,正是政府应该提供的一项基本公共服务。
收起|查看大圖|向左轉|向右轉
|
轉發(6)
|
評論(6)
今天 10:06來自皮皮时光机
|
轉發|
收藏|
評論
16分鐘前
來自新浪微博
作者: admin 时间: 2013-12-16 12:57
【案例】
转载自《视听界》
栾轶玫:大数据重塑媒介生态
2013年12月16日 11:252
一、大数据的本质
首先,大数据显然不是能存放于电脑、手机、硬盘里的数据,它数据量巨大,已经不是以我们所熟知的G和T为单位来衡量,而是以P(1000个T),E(一百万个T)或Z(10亿个T)为计量单位,它需要更大的存储方式,比如云存储和其他大的存锗层来安放。
其次,大数据显然不是一堆数据的堆积,而是数据与数据之间存在着某种关联,发现并利用这种关联可以产生价值;正如《大数据时代》一书的作者舍恩伯格所强调的,最重要的是人们可以很大程童上从对因果关系的追求中解脱出来,转而将注意力放在相关关系的发现和使用上。只要发现两个数据之间存在相关性,就可能创造巨大的经济或社会效益,
第三,大数据是一种社会状态,其牵涉面很广,在物理、生物、金融、环境生态、军事、通讯、自动控制等各个领域都有相关应用。物联网、云计算、移动互联网、车联网、手机、平板电脑、PC以及遍布地球各个角落的各种各样的传感器,无一不是交据来源或承载方式。随着互联网,特别是近年来移动互联网的繁荣,大数据在这个领域的作用越来越凸显。原因有三:其一,网络行为数据激增;其二,网络内容从单一的文字走向多媒体,使数据总量不断增长;其三,多屏多终端模式增加了用户对网络的使用次数与时长,大量数据因此增长且沉积。备行各业数据都呈现出一种指数爆发增长状态,大数据成为这个社会最为显著的标签。
第四,大数据是一种基于开放性的数据互通互联,以及在其基础之上的价值发现。信息孤岛、数据阻隔,都不利于大数据多用途的价值发现。
二、大数据应用的三个层面
大数据应用以“数据回报”为导向,通过对数据的收集、管理、分析、直用,最终获得经济收入、口碑回报与事业良性发喂等价值效用。
1.数据收集
大数据运用的关键在于谁拥有数据。《纸牌屋》之所以能够通过大数据的精准制作而取得成功,前提是其投资方Netflix自身雄厚的数据资源。它拥有2700万名美国订阅用户、3300万名全球订阅用户,掌握这些用户的年龄、性别、居住地、使用服务终端、用户每天/每周的观看时间等数据。这使得它可以轻松利用大数据建模,对用户评分、观看记录、用户好友推荐等信息进行深度挖掘,甚至可以通过收集观众按下暂停或快进的数据,从而找出用户喜欢的视频风格、内容风格、导演和演员等等,这些关键数据是其成功的第一步。
对于传统媒体而言,获得数据的渠道可以是自己的网站、在其他平台上的APP、机顶盒等,博客、微博、微信中的内容,情绪符号、各类投票、链接、图像、视频、评论、文本文件、加关注、粉丝等信息及关系图谱,它们隐藏着有价数据。只要在纵向上有一定的时间积累,在横向上有较丰富的记录细节,通过多个源头对同一个对象进行各类数据采集并且有机整合,就可能产生大价值。
2.数据管理
大数据的关键并不止于数据量的大小,而在于对数据的分析与应用能力。数据应用的前提是对数据进行高效管理。
数据分类目前数据类型主要有:1.交易数据;2.行为数据(兴趣数据等);3.关系数据;4.位置数据;5.用户生产的内容UGC(包括信息、评论)等,将这些数据分门别类地收集,并在其中学会倾听用户需求,理解用户行为,从中发掘细分市场的机会,以此应对“技术+用户+品牌”的媒体新时代。
打通数据随着新技术不断发展,多屏观看、跨屏互动已成为趋势,但现实却是各部门间组织结构的割裂情形使得数据呈现离散与孤立状态。在数据分析时,对同一用户在不同终端的使用数据并没有串联起来整体分析,分析的结果必然与现实有很大的偏差。因此打通数据,数据自由流动,发挥多重效能,是数据管理很重要的方三:以腾讯视频为例,他们利云端收藏和云端播放,加上多平台可使用统一的ID号码,使得用户收看行为成为一种不被打断的连续状态,用户无论采取手机、TV、Pad、PC登陆,都可以通过云端收藏延续前面的收看行为。在方便用户的同时,这对于数据集而言也是一个连续性获得。此外,腾讯视频还给其媒资库的各类视频都打上“内同标签”及“用户行为标签”,并根据智能推算法推荐最匹配的内容给最对的用户
开放数据大数据之所以能产生价值,在于数据的关联性,通过对关联数据的分析,挖掘其中蕴含的潜在价值。鼓励的数据很难产生这样的效能,因此,开放数据是数据管理的一种先进理念。任何一个机构都不可能自己进行所有的分析和运用,开放是利己利他。比如Facebook和Twitter就带头开放数据给第三方公司,他们的开放不是无偿的,希望从开放中收益。
3.数据应用
新媒体的本质就是数据分析,数据是客观的,但分析应用却是主管的,如何平和二者的关系,是数据应用的一个关键。
大数据的应用延续着“信息——知识——智慧”三个层面:第一层面是“信息”,当一个个数据被赋予背景,它就成了“信息”;第二个层面是“知识”,当从一个个数据分析中提炼出规律,它就成了“知识”;第三个层面是“智慧”,当借助分析工具与当下的社会心理以及其他子系统背景,从数据中获得研判与预测的能力,这就是“智慧”。
在大数据时代,媒体和门户网站可充分利用大数据与关系链,为用户提供量身打造的新闻资讯,以及良好的体验。比如,优酷和土豆合并后,其搜索平台可挖掘并推算出4亿多视频用户的浏览行为;浙报集团去年投资数据分析项目,开辟社交网络数据深度挖掘的新战场;搜狐正着手将旗下数据资产全面打通整合,搭建基于云计算的大数据平台,以期获取每月9亿多人次的用户数据资产,一场关于数据的圈地运动正在展开。大数据有哪些具体应用呢?
为内容购买提供数据支持。以腾讯视频为例,他们通过数据分析来购买内容,依此购买的《隋唐演义》今年一季度独家播出播放量超过6个亿,独家剧《宝贝》播放量超过3个亿。大数据为内容购买提供了精准的指向。
为用户提供信息图谱。新版腾讯微博利用大数据技术,将用户的微博进行整合、重组,将具有相同、相近信息的微博配以热门标签,用户通过进入标签,可看到这个热门事件发展脉络以及未来专向的一个清晰的信息图谱,减少获取信息的时间成本。
解决媒体与用户的关系问题:大数据是网络时代对网络用户行为的一个数据积累。这些数据一方面反映用户的兴趣偏好,从而有利于媒体制作出用户满意的产品;另一方面,数据对用户满意度也非常重要的影响。大数据有助于媒体更好地了解用户,从而更好地处理媒体与用户之间的关系。以谷歌的“电影票房预测模型”为例,它通过数据建立了与用户的关联,通过分析用户对电影相关内容的搜索量,能够提前一个月预测电影上映首周的票房收入,准确度高达94%。
三、大数据的媒体作为
媒体业是信息产业,在大数据时代拥有先天优势。麦肯锡全球研究所曾对美国17个行业拥有的数据量做了估算,离散式制造业居首位,拥有966PB数据总量;美国政府居第二位,拥有848PB的数据总量;传播与媒体上居第三位,共有715PB数据量。可见,媒体在大数据时代是有数毛优势的。因此,媒体应有强烈的数据意识,善于收集数据、分析数据、使用数据,通过对海量专复杂的数字资料进行收集、整理,久而提升媒体的预测与研判能力。
媒体能利用大数据做些什么?
1.洞察用户
面对互联网海量信息,基于抽样调查+人口学特征的“小样本模式”不再具有导航性,用户是“谁”已经不重要,重要的是“用户什么时候需要什么东西”,即用户的“兴趣偏好”及“传播时机”等信息更重要,而这一切来源于大数据及对它的挖掘。
大数据构成中有不少数据来源于用户的网络行为、网络表达、网络情绪,这些数据之间有高度的相关性,通过对他们的分析就能清晰地描述出你的“用户”是什么样的,他们的“兴 趣图谱”是什么,“行动路线”又是怎样的。挖掘用户的行为习惯和喜好,并在这些数据背后找到用户的“兴趣配方”,从而制造出相应的产品并提供相应的服务。
因为有大数据,Facebook、Twitter这类社交媒体远比报业、广电等传统媒体更了解他们的用户。因此,传统媒体可以通过与他们的合作,借助大数据更好地理解用户偏好及行为;也可以像英国第四台那样开发自己的注册系统,利用大数据研究自己的用户。这个注册系统目前有700万注册用户,其中三分之一为16—24岁的青年用户。与以往观众调查、听众来信不同,大数据拓展了媒体对于其用户了解的广度、深度及关联度。
2.协作式新闻
大数据使调查性报道有了更多可用的资源,一条调查性报道的出笼越来越凸显“协作式新闻报道”的流程及风格。报道中有来自用户贡献的UGC内容,有专业记者采写的报道,有数搪分析师从大数据系统发现的线索、关系图谱、发展趋势等,有责任编辑负责新闻报道
最后的呈现,有专门的新媒体运营者来实施这条报道在各个平台上的推送,以掀起社会影响力。因为大数据,新闻生产流程将会发生大的变化。新闻不再是单兵作战,协作式新闻将成为主流生产模式。
3.广告精准投放
大数据的多维度与实时性为广告精准投放提供了可能。例如,《经济学家》建立了自己的数据库,包括用户的注册信息、国家、投递地址、邮件地址、打开邮箱频率等,为实现移动端的广告订制与目标推送建立了可能。广告的精准投放将会改变广告业整体的媒介购买偏好及广告投放配比,越来越多的广告将被投放到社交媒体,这对广电等依靠广告而生的传统媒体将产生深远影响。
4.舆论分析与研判
现阶段,新闻媒体可以用大数据做什么?1.讲故事;2.来分析各种评论;3.降低信息过载(即大数据可以提供相关背景资料,让人们获得的不仅是一条条信息,而是围绕这条信息形成的知识图谱,这有利于降低用户获取知识的成本;4.进行舆论分析。以“阿拉伯
之春”为例,通过大数据的深度挖掘,可以了解多少人和哪些人正,在从温和立场变得更为激进,并“算出”谁可能会采取对某些人有害的行动。这正是大数据的舆论分析及事态预判能力。然而,舆论引导在大数据时代却变得更困难,因为信息越来越透明化且结构化,且这种结构化是非人工的,由算法得来的,虽然在设置变量等因素时可能有能动性与操控空间,但整体而言,这种非人工的结构化信息,部分消解了先前人工化组织的“议程设置”等引导舆论的方式。
四、大数据重塑媒介生态
目前全球互联网用户已经达到25亿,手机用户超过64亿,基于网络信息技术的新媒体已经成为当今世界最活跃和最重要的发展领域。大量的数据将被刨造出来:据IDC估计,到2020年,数据量将由2012年的2.7ZB猛增到35ZB。我国已拥有5.78亿互联网用户和11亿多手机用户,以大数据、云计算为代表的新兴业态将不断呈现,无疑,这些都将重塑媒介生态。
1.理念
首先,树立用户理念,认识到大数据是帮助媒体建立起与用户关联的重要支撑,通过大数据,媒体会更加理解用户及其需求,这从根本上转变了媒体“传者本位”的旧面貌。其次,认识到大数据是媒体的“新石油”,但是它的价值不止于数据本身,而在于数据带来的意义。
目前,80%不断增长的大数据,包括文字、3D照片、邮件信息等内容都还处在未被组织化与结构化的状态中,是无意义的。如何将这些数据组织化与结构化是一个重大命题。第三,先前媒体是“分发(传播)驱动”,现在媒体变为“数据驱动”,在“数据驱动”这一媒体新动力中,解决人们信息冗余、知识缺乏也是一个重要方面。此外,“开放”是媒体迎接大数据时代的最佳选择。孤立的数据缺少价值,而任何组织都不可能处理所有的数据,因此,借用第三方数据、引入第三方力量、向第三方开放数据,都可避免自己变成“信息孤岛”,增加多触点及外部通路是大数据时代媒体的生存之道。
2.平台
大数据时代,平台为王。对传统媒体来说,数据量的快速增长,需要在带宽和存储设备等基础设施方面加大投入,对当前的报道形式和运行体系进行全面改造,建立媒体机构自己的基于大数据技术的智能平台,但这需要决策者相当的胆识与相应的资本支持。对于大多数 传统媒体而言,大数据时代,受众数据缺乏是困中之困。读者数据的缺乏催生了一些传统媒体的平台变革。创办于1 887年,旗下拥有1 5家日报、36家周报、29家电视台以及数百种杂志的美国赫斯特传媒集团,去年11月收购了Sp∞ky C0。l Lat)S的社交游戏公司,将游 戏作为其内容产业延伸及读者数据获得的全新平台。浙江日报报业集团于去年底斥资32亿收购了网络用户集聚平台——边锋浩方网络平台,这个平台上有五六百款的游戏,活跃用户达2()(]0多万,最高在线人数150万。浙报集团通过这个平台,建立数据分析系统,深人筛 选捕捉用户行为、习惯、偏好和需求,挖掘数据资源,以弥补传统媒体读者数据不足的缺陷。
3.人才
大数据时代,除了平台等硬件要跟上之外,数据挖掘与深度分析的专业人员更不可缺。据麦肯锡全球研究所报告指出,美国需要150万精通数据的经理人员,以及14万到19万深度数据分析方面的专家。数据加工能力匮乏、缺乏专门的数据分析方法及高端专业人才,是很多媒体应对大数据时代的重要挑战。研究机构预测:未来七成以上传统采编将转岗,媒体将实现整体结构转换,数字分析人员将占到总比例的五分之一。如果媒,本人才跟不上,即使数据平台搭建好了,对于数据的开发与发析也会因人才不足而难以发生效喟。因此,传统媒体在大数据时代一方面要搭建数据平台,另一方面也要培养数据分析人才。美国《赫芬顿邮报》的在线媒体团队中,除了传统的记者、编辑以外.还设置了用户体验设计师、流量编辑、产品经理等互联网公司的常规职位。
4.广告
大数据改变了媒体投放比。以前广告主在广告投放时经常会遇到“我们应该在哪个媒体投放”、“需要投放多少广告”、“应当如何分配广告费”、“用户看到广告有无共鸣、有无行动”等问题,这些在大数据时代都可以通过数据分析看到结果。大数据使广告的精准投放成为可能,社交媒体因大数据而受到广告主的青睐。先前对在线媒体的评估方法主要是搜索、广告位的转化率等,这些方式都只能得到客户的行为结果,而对于品牌建立的有效性、长久性仍然缺乏真实体认。但大数据改变了这一切,伴随着语义分析软件、语言处理软件、机器
认知软件、集群分析软件等,大数据可以揭示出在线市场行为的真实结果。大数据让社交媒体的价值被重新定位,广告主因此也会重新评估自己在社交媒体及传统媒体上的投人配比,这对依靠广告而生的传统广电而言无疑是大挑战。
大数据改变了广告形态。用户获取广告的通路越来越多,但用户分配给每个广告上的时间却越来越少,在这一情形下,让自己的广告长得不像广告,将广告融于信息与内容中,将会增大广告被关注的可能性,腾讯目前做的基于信息流的广告就是这种新形态。此外,还有一些基于位置信息的广告也应运而生。比如,大数据可以通过用户手机的品牌、手机所在位置、移动路线、手机中安装的APP类型来判断亏习的基本特征,并依据算法分析用户的兴趣偏好,从而适时、适位地向用户推送相应广告,这种推送甚至可以依据地域定向、性别定向、场景定向来投放。这了解用户需求的广告,投放效果必然优于先前的非精准的广告投放。
5.新闻生产与呈现
美国哥伦比亚新闻学院Tow数字新闻中心去年12月发发布的研究报告指出:新技术带来新闻生产流程的变化,截稿期与新闻形态不再严格限定,地理因素对于新闻信息收集、生产、消费而言不再重要,社会活动与数据的信息流提供了新的未经过滤的素材。而新闻生产也越来越呈现出“内容动态化”与“内容在线”的新特质。
大数据怎样改变了新闻的生产与呈现呢?
首先.记者可以通过计算机辅助采访丰富自己的报道。在大数据时代,除了政府、机构、企业等公开发布的数据外,媒体、网站拥有的用户数据、用户生产的内容,也是新闻从业人员重要的数据资源。那些公开或隐蔽的数据,都为记者发现新闻选题、拓展新闻深度提供了重要线索。
其次,“算法新闻与机器写作”将成为新闻新形态。美国IT杂志《连线》记者史蒂芬列维发表文章,称未来计算机可代替人生产90%左右的新闻。文章引用了一家名为Narrative的公司的例子。这是一家拥有大约30名员工的美国公司,它们运用Narrative Science算法,大约每30秒就能够撰写出一篇新闻报道。这种计算机撰写的新闻稿可以是关于美国篮球比赛的消息。
第三,在新闻生产的采访、编辑、播出的全过程中都可以不断调整甚至重置以符合用户的新需求。这与过去封闭式、一次成型的内容生产方式全然不同,它更强调吸引用户关注、参与并且分享新闻生产。
此外,大数据时代也改变了新闻呈现。信息图表在新闻呈现中扮演着越来越重要的作用。根据道格-纽瑟姆(Doug Newsom)的概括,作为视觉化工具的信息图表包括:图表(chart)、图解(diagram)、图形(graph)、表格(table)、地图(map)和列表(1ist)等。信息图表不仅是对文字报道的扩充与延伸,也被当作独立的新闻形式,它为用户提供了一个信息图谱,将新闻事件的关联、背景、数据、分析、评论以图谱形式呈现,有助于用户视觉化地了解信息全貌。
6.机构
大数据时代的数据分析基本单位是个人用户,收集的是单一个体全面、完整、动态、实时的网络行为,并在此基础上归纳出的“群体行为”与“社会心理”。负责大数据的“数据管理与分析”部门,应该位于媒体的核心地位,整体把握媒介产品开发、媒体运营以及媒体商业模式,这就要求对现有的组织架构进行重组,“一个媒体一个团队”的传统架构将被“内容采集部门、平台维护部门、广电内容制作部门、新媒体制作部门”四大分类取代。具体而言,“内容采集部门”负责所有内容的收集及提供,包括新闻记者采写的内容、UGC内容、背景资料、各类评论及图表等;“平台维护部门”主要负责大数据平台的维护,包括call center这样的用户反馈数据收集、数据库、媒资库、广电云以及来自第三方平台的有用数据的获取、管理与应用等;“广电内容制作部门”主要是从“内容采集部门”与“平台维护部门”获取自己所需的线索、数据、新闻内容,制怍成相直的广播产品或电视产品,并在相应平台推送;“新媒体制作部门”则主要将其他部门提供的内容制作成适合网络平台、移动平台、数字平台等新媒体各平台传播的相应产品,并且利用微博、微信等多平台、多屏幕进行推广。
与“云计算”、“物联网”前些年被热炒的情形一样,“大数据”也成了人们口边的热词。值得警醒的是,大数据并不是收集的数据越多就越好,而是用一种高性价比的方式看到以前不曾看到的事物的颗粒度与细节,并能够用更加快速、准确的方式来处理数据、做出研判与预测,这一点对于每一个企图在大数据时代建功立业却囿于数据缺乏的媒体而言,至关重要。(摘自:《视听界》作者:栾轶玫)
原文地址: http://www.ahradio.com.cn/jmyfzx ... /09/002871899.shtml
作者: admin 时间: 2013-12-20 14:21
【案例】
广州房价两家官方机构数据:一个大涨一个大跌
2013-12-20 03:21:30 来源: 新华网 有5175人参与分享到
新快报讯 12月18日,国家统计局和广州市国土房管局分别公布了11月广州房价统计数据,前者数据显示,广州房价同比涨达20.9%,环比上涨0.8%;而后者则称,广州房价环比大降10.6%,当月成交均价同比下降7.1%。
同一城市的房价统计,为何出现截然不同的结果?新快报记者求证得知,两个官方机构统计口径不同是导致数据打架现象产生的主因。并且,由于广州官方的统计数据将增城、从化纳入统计范围,使得房价被大幅拉低。
基础数据均来自阳光家缘
国家统计局数据显示,11月广州新建商品住宅的价格环比上涨0.8%,同比上涨20.9%,同比涨幅位居上海北京深圳之后,全国第四。今年1-11月,广州房价均表现为同比上涨,并多次领涨全国,从9月份开始连续三个月涨幅超过20%。
而广州市国土房管局公布的数据几乎每个月和国家统计的数据都有差别,只是11月的差异显得尤其大。其数据显示,11月广州十区二市的房价为11468元/平方米,环比下降10.6%,同比下降7.14%,这也是广州官方统计的今年来唯一一次同比下降。
就数据打架一事,新快报记者采访了国家统计局广州调查队的相关负责人。该负责人表示,两者的原始数据出处一致,只是统计口径不同,导致数据出入较大。
两者的数据都出自阳光家缘。国家统计局广州调查队相关负责人介绍,国家统计局的数据是由国家统计局在各地的调查队直接提供,然后由国家统计局统一计算。"70个大中城市的新建住宅销售价格、面积、金额等资料直接采用当地房地产管理部门的网签数据"。
房价平均数VS价格指数
该负责人解释,由于广州市国土房管局数据反映的是均价,而国家统计局反映的是价格指数,两者在统计口径上并不相同。
首先是统计范围。按照国家统计局的方式,住宅销售价格的调查范围为70个大中城市的市辖区,不包括县。落到广州,即十区,不包括增城、从化。而广州市国土房管局的价格则包括了后两者,其价格远比十区要低。
另外,统计方法也不一样。
据介绍,广州市国土房管局的房价数据是平均数,即用成交总价除以成交总面积得出成交均价;而统计局的价格指数采用的是"同质可比"的方法,抽取同一楼盘不同时间段的数据,通过加权的方法得出数据。
"如果说那栋楼卖完了,我们会找'同质'的楼再继续。例如原来纳入统计的是天河某南向10层左右的房屋,那接下来我们选择的也是这种类型的屋子。"该负责人表示,虽然两者反映的都是真实数据,但相比而言,价格指数反映的情况可能更贴近民众的感受。
增城从化纳入统计范围业界:调控任务无难度
新快报讯在今年初,广州市相关部门公布今年房价调控目标是"不超过全市年度城市居民人均可支配收入实际增幅",根据估算,预计幅度将在7.5%-8%之间。而今年1-9月份,广州市国土房管局对外输出的官方房价数据均不包含增城从化。数据显示,9个月以来广州十区的均价均保持10%以上的增幅,第一季度涨势尤其惊人。
12月13日,广州市国土房管局才将10月份的房价数据对外公布,并且出乎意料地将增城从化计入了统计范围,即便如此,数据仍然显示同比上涨了12.8%。实际上,在今年12月初的广州市政府领导新闻发布会上,广州市副市长陈如桂就公开表示,截止至今年10月份,广州市十区均价为15200元/平方米,同比增长12.8%。但是若按照广州十区二市的统计,那么全市的均价为13100元/平方米,同比增长8%,已经接近完成调控目标。
就在众人议论广州今年房价调控目标完成有难度时,增城从化现身"救驾"的做法令得这个看似难以完成的任务又变得柳暗花明。11月,该局继续沿用了10月份的统计方式,数据显示同比下降7.1%,是今年来首次同比下降。
因此,有业内人士认为,若采用广州十区二市的房价数据,今年房价调控目标实现几乎无难度。
■专家观点
算平均数没什么实用价值
并不能改变房价过高的状况
新快报讯暨南大学管理学院教授胡刚说,广州的统计方法是算术平均法,将总成交房价除以总成交面积,算出单位房价;而国家统计局则是指数计算法,追踪同一物业不同时期的价格变化进行加权计算得出房价数据。
据分析,将平均房价几万元的中心区和几千元的郊区合在一起计算平均数,这种统计对于判断房地产市场"没什么实用价值";而国家统计局的统计方法比较科学,更能体现房地产市场的变化。
专家指出,采用指数算法,只要房价上涨,统计结果一定上涨;而采用算术平均法,只要政府控制中心区高价住宅的成交,房价数据可能出现"结构性下降"。
今年4月,广州出台政策,由政府对住房价格进行"指导","高于政府指导价的住宅不得销售",下半年,一些开发商表示,中心区的高价住宅很难拿到预售证,而郊区的低价住宅则容易拿到预售证。
业内人士指出,变换统计方法,并不能改变房价过高的状况。如此统计,有"忽悠"之嫌。 (据新华社电)
数据打架容易产生误导
新快报讯“数据互相矛盾,很容易产生误导。”中国房地产数据研究院执行院长陈晟认为,当前房地产成交均价“数据打架”的矛盾,不仅让政府难以有效判断,而且会让一些喜欢“以数据说话”的人扰乱市场预期。
暨南大学管理学院教授胡刚指出,统计数据自相矛盾的问题,不仅体现在房地产领域。“统计数据的权威性来自统计的真实性,关系到政府公信力,因此不能当成儿戏。”专家建议,地方政府发布房价数据,应该根据城市的区域、房屋的类型等分别发布数据,让公众真实感受到房地产市场的变化,使房价数据更具参考价值,避免因为数据矛盾引发市场误判。
而对于将增城、从化计入广州统计范围的做法,知名房地产专家韩世同直指“非常不妥”,有故意拉低均价的意图,就算最后完成了调控目标也没有意义,“甚至这种做法应该被问责”。 (据新华社电)
广州房价统计数据 月份 同比涨幅 环比涨幅 (国家统计局)
1涨 13.6%涨 4.7%
2涨 15.1%涨 8.2%
3涨 34.9%涨 11.2%
4涨 18.4%涨 13.7%
5涨 11.7%涨 15.5%
6涨 11.2%涨 16.5%
7涨 10.7%涨 17.4%
8涨 17%涨 19%
9涨 12%涨 20.2%
10涨 12.8%涨 20.7%
11降 7.1%涨 20.9%
广州房价统计数据 月份 同比涨幅 环比涨幅 (广州市国土房管局)
1涨 2.9%涨 2%
2涨 2.2%涨 3.1%
3涨 3.2%涨 2.5%
4降 2.6%涨 2.1%
5降 5.9%涨 1.5%
6降 0.9%涨 1%
7涨 3.8%涨 1.1%
8降 1.8%涨 1.7%
9降 3.1%涨 1.4%
10降 2.9%涨 0.9%
11降 10.6%涨 0.8%
■有此案例
政府下令网签限价开发商“砍价”应对
原价2.3万元,分为1.9万元部分网签,4千元部分给现金
记者调查发现,广州一些楼盘与年初相比上涨30%以上,如海珠区一处二手房,去年买入、今年卖出,房价已经从两万元出头上涨到三万元以上。
广州市购房者毛女士对记者说,不久前她看上白云区一处130平方米的住宅,约定成交价格是每平方米2.3万元,但开发商11月底突然打来电话,政府紧急下了通知,成交价不能高于1.9万元,否则不能网签。
所以毛女士必须签每平方米1.9万元的“合同”供国土房管局备案计入房价统计,但多出来的每平方米4000元差价必须提前交现款。这样一来,毛女士首付相当于多出了50多万元,无法筹措这笔巨款,结果只好放弃了这套住房。
“政府光想着完成调控目标,开发商一分钱也不少赚,最后还是我们这些刚需埋单。”毛女士如是说。 (据新华社电)
(原标题:巧用统计方法是为调控房价?)
http://news.163.com/13/1220/03/9GGP8S680001124J.html
作者: admin 时间: 2013-12-29 16:39
【案例】
Times Announces Changes in Washington
By CHRISTINE HAUGHNEYPublished: November 20, 2013
The New York Times on Wednesday announced a reorganization of its Washington bureau, including the elevation of Carolyn Ryan to bureau chief and the start of two new ventures.
Enlarge This Image

Carolyn Ryan, 48, was named Washington bureau chief for The New York Times.
In a memo to the staff, Jill Abramson, the executive editor, said that Ms. Ryan, currently the top political editor, would succeed David Leonhardt, who will head up one of the new initiatives, in a role that combines data with analytical reporting.
Ms. Ryan, 48, was named to her most recent post in May after serving as metro editor since January 2011. Before that she was the metro desk’s political editor and helped oversee the coverage of Gov. Eliot Spitzer’s involvement with a high-end prostitution ring; that coverage won a Pulitzer Prize in 2009 for breaking news reporting. She joined The Times in 2007 from The Boston Globe, where she was deputy managing editor for local news.
In her new role as bureau chief, Ms. Ryan will continue to oversee a team of reporters in New York, along with the Washington bureau.
Mr. Leonhardt, 40, will become managing editor of a new venture that Ms. Abramson said would “be at the nexus of data and news” across a range of subjects, including economics, politics, policy, education and sports. Mr. Leonhardt’s new team is expected to include “reporters, graphics editors, economists, historians and political scientists.”
Before becoming Washington bureau chief in September 2011, Mr. Leonhardt wrote the Economic Scene column for The Times and was awarded the Pulitzer Prize for commentary in 2011. Mr. Leonhardt joined The Times in 1999 after working at BusinessWeek and The Washington Post.
The Times is also introducing an early-morning news tip sheet, a digital product about the day’s happenings in Washington that will be supervised by Carl Hulse, currently a deputy in the Washington bureau. The tip sheet is expected to resemble the New York Today report, which provides a roundup of news and events in the New York metropolitan area.
According to the memo, the Washington report will “harvest the best tweets of bureau reporters and aggregate other elements from the Washington news report.” Mr. Hulse will also continue to write for The Times as chief Washington correspondent.
Mr. Hulse, 59, was previously the chief congressional correspondent for The Times. Mr. Hulse joined The Times in 1986 after working for The Sun-Sentinel in Fort Lauderdale, Fla.
According to the memo, “existing and new staff” will work on both new ventures. The new positions will be effective on Dec. 15.
This article has been revised to reflect the following correction:
Correction: November 20, 2013
An earlier version of this article misstated the name of the column David Leonhardt wrote before becoming the Washington bureau chief. It is the Economic Scene column, not Economic Sense.
http://www.nytimes.com/2013/11/21/business/media/times-announces-changes-in-washington-bureau.html?_r=0
作者: admin 时间: 2014-1-1 17:31
【案例】
@吴显庆教授
居民收入持续跑输GDP,国家和企业从国民收入中拿得过多,居民拿得过少,使居民收入增速下降。 我国居民收入占国民收入比重1995年为67.3%,2007年为57.5%,2008年后下降更严重。近5年我国间接税比重达65%,个税基本变为 工资税 。http://t.cn/8kg4k12
| 轉發(3) | 評論(1)
6分鐘前來自新浪微博
作者: admin 时间: 2014-1-26 09:49
【案例】
郑敏博士
//@中国网络传播学会:【小蜜蜂早班车】#《纽约时报》网站发布2013年点击量最高的十篇文章#
◆◆
@清华史安斌
《纽约时报》网站发布2013年点击量最高的十篇文章,其中名列榜首的是一篇由实习生完成的报道(作者为统计学博士生,因该文的成功被NYT聘为全职记者),该报道利用大数据和可视化新闻的手段为我们描绘了一幅美国英语的“方言地图”(下图),普京总统撰写的评论名列第五,波士顿爆炸案三篇,健康报道2篇
作者: admin 时间: 2014-1-26 09:59
【案例】
沈浩老师
//@搬运大数据的亨利:一线城市向人口输出大省之间的人口大迁徙。建议分方向统计,看起来更准确。再基于典型行业统计,可看出各行业对就业的贡献,也能布局输出方的产业,更多地就近就业。另外,西藏人基本不出来,待在家里放牧和念经。
◆◆
@沈浩老师
百度春节人口迁徒大数据可视化:http://t.cn/8FfUtiM
(11)
(7)| 轉發(84) | 評論(11)
今天 08:01來自iPhone客户端
(1)| 轉發(18)| 收藏| 評論(6)
今天 08:41 來自iPhone客户端 | 檢舉
作者: admin 时间: 2014-1-27 09:21
【案例】
话题:中石油柴油掺水超标40倍 回应:影响不好请别报道[查看原文]
红色鸡国 [网易加拿大网友]: 2014-01-27 06:36:04 发表
中国油价远远贵于美国!算算就知道多贵了!
因为美国高速不收费所以应该拿海南来比!因为中国只有海南高速不收费!费用被合在汽油钱里!
今日海南93号汽油价格是8.83合人民币元一升!
今日全美油价3.295美元一加仑合0.87美元一升!合人民币5.26元一升!
所以中国汽油真实价格比美国贵了67%!而且中国汽油含硫量是美国的5倍以上!是日本的15倍以上!简直又毒又贵!真是天差地别!
2012美国平均工资大概是24美元时薪 也就是一年5万美元税前!
中国2012平均工资城镇私企2.8万 城镇非私企4.6万 60%的人在私企工作!
所以城镇平均工资是3.52万人民币!
所以美国平均工资能买57441升汽油!
中国全国平均工资能买3986升汽油!差距为14.4倍!
当然这样对比对美国不公平!因为美国农民收入比城市高!但出去在城市的2.6亿农民工中国还有50%的人是在农村的农民!
中国农民人均收入只有城市的三分之一所以购买力差距是43.2倍!
平均下来汽油购买力算上高速路买路钱中国美国差距是28.8倍!感谢国家吧!
现在中石化毒贵油里还加水!哈哈哈哈哈!水变油是一高档把戏哟!
http://comment.news.163.com/news_guonei8_bbs/9JIKLM740001124J.html
作者: admin 时间: 2014-2-6 11:16
【案例】
张玮玉
//@新媒体董少伟://@杨伯溆://@DataDancing: //@云泉微博: //@田志宏-哈工大://@中科院王飞跃:转发微博
◆◆
@孙茂松
学术界已经开始跟进MOOC的相关研究了。NIPS Workshop on Data Driven Education (2013)。这是一个积极的信号。五位特邀讲者的PPT都颇有参考价值。见 http://t.cn/8Fa9rYI
(9)| 轉發(142) | 評論(12)
2月5日19 : 27來自新浪微博
| 轉發| 收藏| 評論
27分鐘前 來自Android客户端 | 檢舉
作者: admin 时间: 2014-2-7 18:12
【案例】
南方周末
【毛泽东悼念活动中的医疗救护】吊唁期间,大会堂内共治疗398人,大会堂外天安门广场共治疗8431人,巡诊6984人,合计15813人。一万五千多人在吊唁大厅内外出现不同程度的病状,体现出中国民众对最高领袖去世的悲恸程度和承受不住的精神打击。http://t.cn/8FShG9F
(27)
(26)| 轉發(85)| 收藏| 評論(91)
14分鐘前 來自南方周末 | 檢舉
作者: admin 时间: 2014-2-9 10:20
【案例】
数据新闻:全球新闻界的新宠
在全球新闻界,”数据新闻”已经不再停留于一个新名词,它代表着新闻业正在进行的一系列如火如荼的实践——
数据新闻的前景被看好
2013年6月,由”全球编辑网络(Global Editors Network)”和谷歌赞助的一项新闻作品评选活动公布了该年度获奖名单。8个新闻作品从300多个参赛作品中脱颖而出,获得了最终的”数据新闻奖”。在参与奖项评选的名单中,不仅能看到《卫报》、《金融时报》、BBC、美联社、《得克萨斯论坛报》、《琼斯夫人》杂志等老牌主流媒体的名字,也可以看到ProPublica这样的新兴公共新闻网站和诸多独立数据记者的身影。值得一提的是,欧美媒体并没有垄断参评名单,南美洲、大洋洲、亚洲、非洲的许多国家和地区的媒体组织也参与其中。这是全球第一个专门为数据新闻设立的奖项,从2012年开始颁发。
在全球新闻界,”数据新闻”(也称”数据驱动新闻”)已经不再停留于一个新名词,它代表着新闻业正在进行的一系列如火如荼的实践。早在2011年伦敦Mozilla大会(Mozilla Festival)上的48小时工作坊中,众多齐聚于此的数据新闻倡导者就产生了”以网络协作方式编写一本介绍数据新闻理念和方法的书籍”的想法——这就是如今在互联网中广为流传的《数据新闻手册》。
众多媒体专家看好数据新闻的前景。”精确新闻学”的奠基人、美国北卡罗来纳大学教堂山分校荣休教授菲利普·迈耶如此强调推行数据新闻的时代意义:”现在是个信息过剩的时代,对信息进行处理很重要。我们需要做两步:一个是通过分析不断变动的数据以找到其中的意义和结构,另一个则是通过展示让用户了解哪些信息对他们具有重要性和相关性。”有”互联网之父”之称的蒂姆·伯纳斯·李(Tim Berners-Lee)则干脆宣称:”数据新闻就是未来。”
“数据即讯息”成为时代共识
如果说20世纪60年代麦克卢汉提出的”媒介即讯息”在振聋发聩的同时也引发争议的话,那么”数据即讯息”俨然已经成为这个时代的共识,其商业价值和管理价值正在得到前所未有的重视与开发。
2013年,由美国前情报机构工作人员斯诺登曝光的监听丑闻不只是一场国际政治风波,更彰显着数据在这个时代对于每个人的价值。英国《卫报》就此刊发了报道《解密美国国安局文件:曝光事件对你有何意义》,其中提及如果某人被视为恐怖对象受到监控,那么和他相关的三级以内的朋友圈都会”遭殃”。用户可以根据自己在”Facebook”上的好友数判断将有多少人牵涉其中。举个例子,如果某人在”Facebook”上有209个好友,那么34150个好友的朋友和5580110个”三级好友”也会被纳入监控范围。这一系列惊人的数据直白地描述了人们的生活是如何被美国安全部门记录和监控的。
身处”大数据时代”,似乎一切事物都可以通过数字和数学来解释。”数据新闻”的兴起与当下的时代背景息息相关。
一方面,无论人们是乐意还是抗拒,都不可避免地被这场数据化洪流裹挟着前行。新闻媒体担负着传播信息、监测环境、对周遭世界的变化作出解释的职能,应运而生的”数据新闻”正是全球媒体应对大数据时代变迁所作出的关键革新。
另一方面,伴随互联网技术的发展,”开放数据”的理念被越来越多的人所接受,各国政府更是在开放数据活动中首当其冲,面向公众公开的政府数据为媒体制作数据新闻提供了重要内容来源。以英国为例,2010年初英国政府的数据开放网站data.gov.uk正式创建,所有政府部门要公开的数据都可以在这个网站上找到。针对政府未公开的数据,媒体可通过《信息自由法案》申请有关部门公开数据。例如看过”开放知识基金会”制作的有关英国税收的报道《我的钱去哪儿了?告诉你你的缴税如何花费》后,用户就可以通过选择年薪数量知晓自己缴纳的税收都用在了哪里。
给新闻业注入创新活力
无论老牌主流媒体还是新兴网络媒体,都不约而同地投入资金和人力开发数据新闻业务——究其原因,是数据新闻为它们注入了创新的活力。
首先,数据新闻业务从获取和分析资料的方法上提升了新闻报道的科学性和真实性,使跨越一定时间和空间的综合报道有了新的报道方式,增加了报道的广度和深度。
一直以来,新闻报道者都受困于呈现片段真实与追求整体真实之间的悖论。数据新闻业务的开展则为记者提供了一种全新的解题思路,即基于更大的样本量,采取数据挖掘与统计的量化研究方法,更全面、完整地报道重大新闻主题。在2013年美国联邦政府关门危机中,《纽约时报》运用静态图表和大量数据展示了包括美国航空航天局、国家环境保护局、劳工部、内政部等诸多部门在内的雇员总数、”被休假”人数比例、休假雇员与坚守雇员的职能区别。《华盛顿邮报》则通过众包新闻的方式,运用谷歌地图呈现了全美2317个与政府关门相关的故事。根据受影响程度,该报将故事主角分为四种类型,并以四种颜色的圆点定位地图中的具体地点,使用户既可以了解整体状况,也可以点击阅读自己感兴趣的某个地区中的个体。以上报道有助于民众更清楚地了解政府关门危机到底与普通人有何联系。
其次,采用科学的分析方法,数据新闻可以帮助媒体从支离破碎的信息中发现规律和趋势,使新闻报道更多地聚焦一些新鲜的主题。针对近年来世界上多个国家和地区出现生育率降低、育龄女性不愿被婚姻与生育束缚的现象,英国《经济学人》杂志网站推出报道《历史的终结和最后一个女人》,按照现有生育率推算各国(地区)最后一个女人出生的时间,预测各国(地区)的历史,引发公众对该社会问题的关注与思考。
此外,通过运用数据可视化技术,数据新闻业务使新闻语言不再局限于以文字表达为主,取而代之的是更为丰富多元的信息图表或动画视频,文字只起到辅助说明的作用;同时,这些图表往往以交互式设计的方式呈现,让用户拥有更多”发现”的乐趣。法国数据记者让·阿比亚特西(Jean Abbiateci)的作品《”傻瓜”的艺术品市场》获得了2013年度数据新闻奖。该作品对2008年至2012年间拍出的最昂贵的320件艺术品进行数据统计与分析。在”毕加索:超级巨星”部分,用户可以找到不同年代或艺术流派的知名艺术家(拍品总价进入前50名);而在”男性主导的行业”部分,用户可以根据年份、艺术家性别、国籍、作品畅销度、拍卖城市、诞生年代等指标对320件艺术品的信息进行梳理,获得丰富的信息量。例如,在320件艺术品中,只有一件是女艺术家作品,数据图中强烈的对比令人印象深刻。
毋庸置疑,新闻业正面临着前所未有的巨变格局。如何通过创新使新闻界适应当下社会的需要?从全球实践的角度看,推广数据新闻不失为一种可借鉴的解题思路。
原标题:数据新闻:全球新闻界的新宠
来源:光明网-《光明日报》
作者:方洁
http://www.neweyeshot.cn/archives/6603
作者: admin 时间: 2014-2-10 10:16
本帖最后由 admin 于 2014-2-10 10:27 编辑
【案例】
传媒人网
好威武霸气的大数据!
◆◆
@武大沈阳
【东莞】对东莞这个词微博讨论最热烈的是广东、北京、江苏和上海。男性占75.6%。V占5.7%(比例很高)。魔蝎、天平、射手和天蝎最喜欢聊。而百度搜索指数昨升至67万次。“东莞桑拿”平均日搜次数为3156次,对比某网络社区的4404次,注册用户三千万,换算可知这些年通过网络深入关注东莞桑拿大概有2149万
(5)| 轉發(22) | 評論(7)
33分鐘前來自新浪微博
| 轉發| 收藏| 評論(2)
8分鐘前 來自专业版微博 | 檢舉
百度地图曝东莞8小时迁徙图
网易科技讯 2月10日消息,昨日,中央电视台曝光东莞多个娱乐场所存在卖淫嫖娼等违法行为后,东莞市当天下午开始出动大批警力,对全市所有桑拿、沐足以及娱乐场所同时进行检查行动。通过百度地图可查看2月9日东莞8小时内的迁徙图,从图中可看出,嫖客四散迁徙,其中以港客最多。
除了大数据让大家看到事情真相的同时,时下流行的互联网思维也是观察此事的不错角度,科技博客i黑马表示,互联网创业者和公司也要从东莞事件中挖掘一些在商战中实用的手段:
对于互联网公司而言,东莞到底有何值得学习的呢?首先是如何找到用户的刚性需求。所有成功的互联网产品之中,满足刚需是基本要求。而所谓的刚需无非是人类自身角度最实际迫切的需求。这就要求互联网公司创业者在选择产品的时候一定要善于从人类本源本质需求出发。
第二,互联网创业者应该像东莞学什么?学竞争的手段。竞争手段有一个最著名的规则,人无我有,人有我优,人优我转。如果东莞的服务只是一个单纯的“性”,那么东莞也不可能这么名气。而在于围绕着基本的需求满足为出发点,不断地优化自身的产品结构。看看东莞,多达上百项的服务,基本满足了所有可能拥有的需求。这给互联网公司的启示是千万别一招鲜,当你确信你已经满足了用户的需求的时候,立刻要成为行业领头者,成为行业领头者之后,如果还有人来模仿,你就要学会改变方向。
第三,互联网公司要像东莞学什么?学快速迭代的产品思维,学产品细节与服务的分解。服务业最高的精髓是什么,是标准化,怎么标准化,就是要善于将一个服务的步骤分解为多个小的服务,同时不断优化每个服务的精准与优质度,然后反复的分解,反复的练习,直到所有的流程都一致了,再练习下一个环节,任何好的服务都是这样炼成的,日积月累,就能形成竞争差异,互联网公司也要将自己的产品和服务分解为标准的细节,然后反复演练,这样才能标准化,而标准化到极致是壁垒。
第四:互联网公司要跟东莞学什么?学营销与粉丝经济。东莞这样的产业是灰色产业,是无法公开与见光的,但是为何几乎全国中国男性都知道东莞,原因是东莞形成了品牌的心智定律,并且拥有了粉丝。而又粉丝的前提是一群去过东莞来的人的口碑传播。互联网公司要重视第一批用户,只有让第一批用户用的极爽,自然口碑传播,口碑胜过一切行为。而口碑的关键在于心智,从而形成心智-口碑-粉丝-在传播。而东莞通过t台秀的方式,并且标签化每个服务者,让用户清楚的知道自己的选择。所以互联网公司要善于标签化自我的产品。
第五:互联网公司要跟东莞学什么?给用户荣誉感。东莞为何能红,其中视频的细节可以看得到,当用户走进去第一瞬间就是喊老板好,这就是荣誉感,不管你是不是老板,当你进去,你就先满足了男性的内心的自尊心。这就是对人性的深刻洞察,当把你当做老板的时候,男人出于面子,往往就会大手花钱。对于互联网公司而言,不管是面对屌丝用户,还是高富帅用户,你一定要给其荣誉感。游戏中为何那么多人热衷于升级打装备成国王,那就是荣誉感在背后支撑。
第六:互联网公司要跟东莞学什么?学体验式销售。先想想为何它的产品不是一个价格,为分为几个不同的价位,因为他们深刻运用了价格的炮灰理论。只有对比过才能产生差异,如果不给以视觉冲击,单纯靠文字推销和介绍有用吗。先让用户免费视觉体验,再导入销售,这是多么高明的招数,对于互联网公司而言,要善于用各种视觉冲击和傻瓜似的方式让用户试用你,只有让用户用,你才可能产生真正的付费,我突然想起婚恋网站了,你一上来就让我付费我真不愿意,但是你让我尝试爽了我肯定会付费的。
当然这些都是互联网公司可以学习的精华,任何事物都有可学习的,当然也要区分事物本身的糟粕,如此可为幸甚。
http://tech.163.com/14/0210/07/9KN5FBNB000915BF.html
作者: admin 时间: 2014-2-10 12:46
【案例】
@壹读
【性交易中的“男客”和“小姐”】有35.2%的女性性工作者与丈夫发生第一次性行为,其后才开始提供性服务。她们的文化程度低于其他女性,但相比于其他女性,她们更多地认为性交易是一种耻辱。大部分男性购买性服务时不是独自一人,而是在别人的陪伴下或陪伴别人去。|性交易中的“男客” 和 “小姐”
-
性交易中的“男客” 和 “小姐”一边是“已婚者更爱找‘小姐’”和“有时‘小姐’的性别并不重要”;另一边则是“小姐”自己“比其他女性更觉得性交易耻辱”和“也可能是想报复男友或丈夫”。文 | 徐冉
文章详情 14
(16)
(16)| 轉發(63) | 評論(22)
今天 11:31來自新浪微博
| 轉發(1)| 收藏| 評論
24分鐘前 來自媒体版微博 | 檢舉
作者: admin 时间: 2014-2-10 18:39
【案例】
王君超
搜索群体的年龄、性别恐怕只是注册、登录用户, 没有登录的群体更大.#东莞数据#
//@宪阁微观: //@ECO中文网: 这样的数据报道挺有意思的~
◆◆
@199IT-互联网数据中心
【数据解读:东莞事件网络影响力】1、东莞百度指数直线上升从原来的8000升至70万; 2、微博指数上升至30万; 3、从东莞迁徙到香港降至13.9%; 4、受此影响一路向西上升娱乐榜第七位; 5、在百度搜索东莞群体主要集中在30-39岁,男性占81%。
收起|查看大圖|向左轉|向右轉
(8)|
轉發(63)
|
評論(15)
今天 14:23來自199IT互联网数据中心
|
轉發|
收藏|
評論
9分鐘前
來自新浪微博
作者: admin 时间: 2014-2-11 11:29
【案例】
黎津平
工人代表指企业老大,依此类推 //@杰人微言:湖南人大代表中企业主超过三分之一,最多的代表团益阳、邵阳和湘潭,企业主超过一半。@清华郭-于华@于建嵘@我是西蒙周@传媒老王@高会民@萧含@谢佑平@看历史@作家天佑-
@米瑞蓉@鹏媒体赵鹏@郭世佑@贺卫方@清华孙立平@何兵
◆◆
@杰人微言
【惊天秘密】贿选阴影之下的湖南省人大正在举行,我研究了代表名单,发现企业主占35.2%,官员占63.8%,共占99.9%,名单详情和数据分析见http://t.cn/8FCna04
这是研究中国政治的最佳样本,也能解释湖南贿选为何那么严重。@于建嵘@清华孙立平@黎津平@徐昕@罗亚蒙@十年砍柴@韩咏红@郑维@袁莉wsj@袁腾飞
收起|查看大圖|向左轉|向右轉
|
轉發(10)
|
評論(3)
25分鐘前來自新浪微博
|
轉發|
收藏|
評論
2分鐘前
來自Windows.Phone客户端
作者: admin 时间: 2014-2-12 12:51
【案例】
游识猷
【美国2013癌症数据图】饼的大小是2013年美国新诊断出的癌症数量,每个饼中深红色的扇形表示诊断N年(N=5 或10或15或20)后的死亡比率。比如乳腺癌的死亡率就比肺癌低得多。每年很多男性会得前列腺癌,但死亡率并不高。死亡率最高的还是胰腺癌和肝癌。http://t.cn/8FpvrYl
收起|查看大圖|向左轉|向右轉
|
轉發(2)|
收藏|
評論
10分鐘前
來自新浪微博
作者: admin 时间: 2014-2-12 23:08
【案例】
@非池中III
毛主席1961年7月的伙食费654.82元,水果费86.65元,共741.47元。1961年中国人民银行的黄金价格是3.04元/克,主席當月生活費約合244克黃金。今日(2014.2.12)上海黄金交易所金價251.57元/克,按每克人民币250元换算,244克黃金合60976元。就是說毛1961年一个月的伙食费超过今天6万元!這就是偉大領袖。
收起|查看大圖|向左轉|向右轉
(2)|
轉發(56)
|
評論(12)
今天 22:05來自WeicoPro
作者: admin 时间: 2014-2-14 21:54
本帖最后由 admin 于 2014-2-14 21:58 编辑
【案例】
http://weibo.com/1424710994/z5vxY3RpD
数据化管理
【数据挖掘的重要性——从林彪的一个故事谈起】有时候数据分析与挖掘并不需要高深的理论和高端的分析工具,仅仅需要一颗善于发现的大脑和永远不放过细节的心!via@萧秋水
收起|查看大圖|向左轉|向右轉
(8)|
轉發(5222)|
收藏|
評論(502)
2012-11-16 23:11來自新浪微博
|舉報
罗月领:【政策】决策与数据//@刘强-同舟共济: //@国匠城市规划论坛: 【大数据更需要小心思】大数据的提法近日甚嚣尘上,首先要明白数据是石油,谁掌握了他就能建立一个王国,所以数据的占有,是有垄断倾向的。但更重要的是,大数据需要的是小心思,城市研究也是如此,小心思往往蕴含大能量,期待我们去发现。 (2013-2-4 09:42)
善良品道://@中国灯谜: 好故事。陈省身说数学是最美的语言。//@野有蔓草2000: mark(2013-1-27 15:52)舉報|
|
回覆
 广州亚运会收藏:大数据时代,需要我们从数字中去追求真相。 (2013-1-24 19:18)
广州亚运会收藏:大数据时代,需要我们从数字中去追求真相。 (2013-1-24 19:18)
|
回覆
 熟视无睹-做好自己://@邝海炎不骂人: 哈哈,这个大数据案例太牛了//@涂子沛: 这个林彪运用数据分析的故事非常精彩!数据是对客观世界的记录,真相总是会通过数据留下珠丝马迹。 (2013-1-24 18:37)
熟视无睹-做好自己://@邝海炎不骂人: 哈哈,这个大数据案例太牛了//@涂子沛: 这个林彪运用数据分析的故事非常精彩!数据是对客观世界的记录,真相总是会通过数据留下珠丝马迹。 (2013-1-24 18:37)Anyon在路上:的确,大数据看的不是数量而是关系
作者: 刘海明 时间: 2014-2-14 22:46
【案例】
@泛媒研究院
汪卫教授谈大数据具有4V特征:体量volume、多样性Variety、价值密度Value、速度Velocity。计算机学科在做哪些大数据工作?一是基于云计算的大数据处理平台,以实现对大规模、高速变化的各种类型数据的处理能力。二是面向应用领域的海量数据分析技术,以实现对数据中蕴含的信息的全面、深入的挖掘。
收起|查看大圖|向左轉|向右轉
|
轉發(2)
|
評論(1)
16分鐘前來自专业版微博
|
作者: 刘海明 时间: 2014-2-16 13:50
【案例】
关注公安微博
大数据给意图移民加拿大的富人带来了麻烦。
◆◆
@网络新闻联播
【加拿大回应“取消移民是否针对中国富人”】加拿大投资移民计划被叫停,有媒体称是因为中国富人申请令加方“难以应对”。对此,加拿大公民与移民部媒体事务负责人表示,压垮投资移民项目的不是申请,而是移民没有为加拿大社会做出贡献。以20年为时间段,一名投资移民比一名技术移民少纳税20万加元。
收起|查看大圖|向左轉|向右轉
(4)|
轉發(14)
|
評論(5)
27分鐘前來自央视新媒体
|
轉發|
收藏|
評論
2分鐘前
來自新浪微博
作者: 刘海明 时间: 2014-2-20 22:38
本帖最后由 刘海明 于 2014-2-20 22:41 编辑
【案例】数据新闻学的发展路径与前景 (2014-02-20 21:22:26)[url=] 转载▼[/url]
转载▼[/url]
如何将数据转化为故事和洞见:兼论数据新闻学的发展路径与前景
史安斌(清华大学新闻与传播学院副院长、教授、博士生导师)
廖鲽尔(清华大学新闻与传播学院硕士生)
刊于《新闻与写作》2014年第2期
摘要:
在全球进入“大数据时代”的背景下,新闻传播学应运而生了一个新兴的学科分支——“数据新闻学”,并被视为未来新闻业发展的主要方向之一而受到各方广泛关注。本文旨在梳理“数据新闻学”产生的背景、内涵、外延、功能及基本特征,结合国际主流媒体践行“数据新闻”的经典案例与新闻学界这一领域所开展的教学研究上的探索,探讨“数据新闻学”的发展路径及前景,并为我国在新媒介环境下如何发展数据新闻提出具有启示性的建议。
关键词:大数据 数据新闻 多媒体 交互性 可视化
数据新闻的诞生背景
“大数据”(Big Data)是近年来全球媒体和舆论关注的“热词”之一。仅在“谷歌搜索”就接近8亿个条目。2013年初,由牛津大学互联网研究院维克托·迈尔-舍恩伯格(Viktor Mayer-Sch渀戀攀爀最攀爀)与《经济学人》数据新闻编辑肯尼思·库克耶(Kenneth Cukier)合著的一本带有鲜明的“福音书”色彩的《大数据时代:生活、工作思维的大变革》(Big Data: A revolution that will transform how we live, work and think)在我国翻译出版,并迅速成为畅销书。他们在书中满怀信心地预言,大数据将是人们获得新知、创造新价值的源泉,也是改变市场与组织的结构以及政府与公民关系的有效途径。[1]换言之,当今世界正在经历一次大规模生产、传播和运用数据的革命,量化、质化等社会科学的研究方法已伴随着社交媒体时代产生的海量信息和数字化浪潮深入人心,社会各行各业都日益倾向于使用数据进行决策与运作。
与之相应,新闻传播学界也提出了一个新的概念——“数据新闻学”(Data Journalism)。业界使用的更为准确的说法是“数据驱动的新闻”(Data-driven Journalism)。首先,它的出现顺应了当今公共信息走向公开透明的总体趋势。目前世界上已经有30多个国家的中央政府建立了“开放数据库”,利用数字化手段推动政务公开,“阳光执政”已经成为不可阻挡的时代潮流。从本质上看,大力发展“数据新闻”也是为了保障民主社会当中公民所拥有的知情权、参与权、监督权和选择权。
其次,数据新闻学的发展也是为了更好地适应当今新闻传播的变局。在社交媒体时代,新闻报道的专业“门槛”越来越低,人人都是记者,人人都是电视台,而传统媒体在重大突发事件的报道中丧失其“第一落点”已经成为“常态”。此外,在过去一年中,谷歌眼镜、小型无人机(drone)等新型装备的面世及其在新闻报道中被广泛使用。由“叙事科技”(Narrative Science)等网站联合美国西北大学梅迪尔(Medill)新闻学院共同开发的“机器人记者”和机器新闻写作软件正式进入业界实践。上述这些变化都预示着新闻报道“去人工化”、“去专业化”的趋势将彻底改变传统新闻生产的模式和机制。另一方面,在新闻日趋“扁平化”、“碎片化”和资讯、数据高度“饱和”的今天,提供深度挖掘的资讯和数据,对全球大事与天下大势做出富于洞见的解读、剖析和预测,反而成为一种“稀缺资源”,甚至可以被迅速转化为行之有效的盈利手段。有鉴于此,在社交媒体和技术变革的挑战面前,媒体机构和专业记者积极开发“数据新闻”就成为维持其生存能力、进而提升其核心竞争力的“不二法门”。
早在2010年8月,首届“国际数据新闻”圆桌会议在阿姆斯特丹举行,对这个概念做出了如下界定:“数据新闻是一种工作流程,包括下述基本步骤:通过反复抓取、筛选和重组来深度挖掘数据,聚焦专门信息以过滤数据,可视化的呈现数据并合成新闻故事。”[2]具体来说,媒体机构和专业记者通过对各类原始数据信息的挖掘、鉴别、甄选、吸收、分析,将错综纷繁的信息和数据“碎片”筛选、整合、凝练而成条理清晰的新闻报道,从而更好地描绘全景、提炼观点、阐释细节。实际上,在“数据新闻学”的概念明确提出之前,学界和业界已经围绕着“计算机辅助报道”(Computer Assisted Reporting)、“精确新闻”(Precision Journalism)及“数据可视化”(Data Visualization)等概念和模式做了大量的研究和实践工作,其共同点都在于最大限度地发挥数据信息的功效来提升新闻报道的品质,为具有不同需求的受众提供“纵深化”、“利基化”(niche)、“定制化”的内容。作为大数据时代下新闻传播学的最新发展趋势之一,数据新闻学集中体现了跨学科、精细化、多平台的特点,在专业知识和技能上提高了新闻生产的“门槛”,具体来说,除了传统的文字写作、音视频制作外,专业记者还要掌握包括社科研究方法、计算机数据抓取与处理、可视化、平面/交互设计、计算机编程等众多领域的知识和技能。[3]
数据新闻的两种模式
从功能上讲,“数据新闻学”与传统新闻学最根本的区别在于,前者为社交媒体时代的新闻记者赋予了一种新的核心竞争力——即同时拥有敏锐的新闻“嗅觉”和使用大规模数据处理信息的能力,从而完成更具有深度和专业性、更富于逻辑性和感染力的报道。[4]简言之,当今的专业记者应当擅于挖掘“数据”,将其转化为生动的“故事”和深邃的“洞见”,并且借助于新媒体使新闻报道呈现出“可视性、纵深性、互动性”的特点,满足受众对新闻报道“更精确、更深入、更直观”的要求。数据新闻涵盖的往往是与公共事务和国计民生密切相关、但又不容易通过文字或图表等传统手段理解和阐明的领域。目前较为成功的数据新闻集中于政治(主要是选举活动)、财经、能源、环境、体育等领域的相关选题。本文将结合两个典型的案例来分析数据新闻的两种基本模式:“利基模式”和“类比模式”。
所谓“利基模式”就是对数据进行筛选、整理和挖掘后转化为满足不同层面受众需求的细分化、定制化的新闻资讯,借助于新媒体平台,以直观、易用的形式向公众提供互动式服务,满足公众日益增长的知情、监督和选择的需求。在世界各大知名媒体当中,澳大利亚广播公司(ABC)是数据新闻的先行者,也是“利基模式”的创立者。 2011年11月24日,伴随着带有数据新闻“烙印”的“用数字解读煤层气”(Coal Seam Gas by the Numbers)的专题亮相,ABC开展的“多平台报道工程”及其所开发的“ABC在线新闻”网站正式启动并上线。[5]这个数据新闻专题是由五个页面的交互地图、可视化数据及文本内容构成的。煤层气(俗称“瓦斯”)则是近年来当地各阶层公众非常关注的热门话题,这是因为它与公共安全和环境保护密切相关,但不同阶层关注的“兴趣点”并不一致。ABC的记者围绕煤层气做了大量的前期采访和调研,挖掘出与其相关的细分数据,并进行系统过滤与整合,利用多媒体平台手段进行展示。其中值得一提的是在数据新闻理念下制作的“澳大利亚煤层气开采”交互地图。用户可以通过点击不同的地点来查看煤层气管道和矿井建设现状,不同的色块和深浅反映出开采活动的密度和频次,从而让受众在宏观上了解澳大利亚煤层气的资源分布和开采情况。同时,不同阶层的用户可以点击“深入”(Zoom in)功能自主查看某一个具体煤层气矿藏的发现者是谁,开凿日期是哪一天,最新的开采进度如何等个性化的详细信息,确保信息的公开透明和公众的知情权、监督权和选择权。例如,环保主义者可以据此了解煤层气开采对当地环境带来的影响;中产阶级可以查阅相关信息来决定是否在当地定居或购房;选民可以找到他们所需要的信息来决定当地政府的管理部门在煤层气开采的问题上是否履行了相应的职责,等等。
ABC制作的“澳大利亚煤层气开采”交互地图(来源:ABC News Online)
所谓“类比模式”是指使用量化、质化等社会科学的研究方法,根据报道主题确定相关的“变量”,针对这些“变量”挖掘不同类别和层面(例如,不同国家、社群、族群等)的相关数据,让受众通过直观化、互动化的手段进行横向和纵向的类比,促使他们在全球视野下和充分知情的基础上进行理性分析,以免做出“标签”式的臆断或产生“坐井观天”式的偏见。与提供专业信息服务的“利基模式”相比,“类比模式”旨在引导受众寻找数据当中蕴藏的“洞见”,提升全球公民意识和媒介素养。
有近70年历史的德国《时代周报》(Die Zeit)在其网站“时代在线”(Zeit Online)利用数据新闻理念,制作了名为“基于PISA项目的国家财富比较”(PISA based Wealth Comparison)的报道集中体现了“类比模式”的一些特点,值得在此做出进一步的分析。PISA的全名为“国际学生评估项目”,是“经济合作与发展组织”(OECD)所实施的对全球65个国家和地区的中学教育水平的总体测评。[6]近年来,代表中国内地参评的江浙沪等省市在这项评估中一直名列前茅。“时代在线”的报道超越了教育领域,通过挖掘各个不同领域的数据之间的内在联系,旨在向受众揭示各国经济社会发展水平与教育之间存在的有机联系。在具体做法上,报道团队首先确定了进行量化与质化类比的三个主要领域——即社会科学研究中所说的“变量”,并对它们进行可视化的展示,其中包括:“物质财富”——通过电视机、汽车和家用浴室的拥有数量来呈现;“家庭状况”——通过与老年人一起居住的家庭数量、独生子女家庭比例及父母(特别是母亲)失业率来呈现;“知识获取”——通过互联网家庭普及率、电子邮件使用频率及个人书籍拥有量来呈现。在网络技术人员的帮助下,他们把这些数据事实通过生动形象的“自述图符”展现给受众。从传播效果来看,不同国家和地区之间的数据类比就如纸牌游戏的较量一般生动有趣。此外,这个报道项目还充分显示了传统媒体与新媒体之间的“竞合”关系。《时代周报》从“德国开放数据网络”(German Open Data Network)等互联网机构聘请了数位信息设计专家。在他们的帮助下,报纸记者在前期搜集的海量数据的基础上,制作出质量更高的“气泡式”(bubble-styled)交互化、可视化的报道。受众通过与数据的互动和不同领域数据之间的类比,全面而深入地把握了不同国家经济社会发展与教育水平之间的关系。这个数据新闻报道项目不仅为大幅提高了“时代在线”的访问流量,同时也为“类比模式”的数据新闻报道提供了以资借鉴的报道范式。
Zeit Online制作的“PISA各国财富比较”数据化报道(来源:Zeit Online)
为了更好地总结和分享各国在数据新闻方面的实践经验,由行业组织“全球媒体总编协会”(GEN)和谷歌公司联合发起了“数据新闻奖”(Data Journalism Awards),这是全球范围内第一个在数据新闻领域设立的专业奖项,目前已经举办了两届,旨在表彰一批引领实践前沿的媒体和个人(自媒体),激励新闻工作者更加重视数据挖掘和深度报道。2013年度“数据新闻奖”吸引了来自全球300多家新闻机构及网站、自媒体报名参加,最终评选出了“美国各州同性恋权益交互地图”、“数字解读阿根廷内阁2004-2013支出状况”、“英国社会层级数字计算器”、“威尔士儿童关怀状况”等8个获奖项目。其中既有来自BBC、《卫报》、阿根廷《民族报》等老牌媒体机构,也有来自 “为了公众”(ProPublica)、“威尔士传媒”(Media Wales)等公民新闻网站或自媒体组织。[7] 评选主题分成四个大类:数据驱动的调查性新闻、数据驱动的移动应用软件(APP)、数据化叙事报道、数据新闻站点或机构。上述四个类别基本反映了数据新闻在业界和实践层面发展的现状和趋势,今后会随着业态的逐步丰富而增加新的奖项。
数据新闻的发展启示
大数据时代的到来,不仅推动新闻业界做出相应的战略性调整,同时也给传统新闻学的教育理念、模式和内容带来了诸多挑战。新闻教育已经不再满足于5W、倒金字塔、标题导语写作等一些采写编拍的基本技巧,这是因为在新闻报道日渐“去人工化”的今天,上述这些“雕虫小技”都可以由机器代替。为了顺应这一发展潮流,许多国家的新闻学院和研究机构在“数据新闻学”的专业教育、学术研究和行业培训方面做了诸多具有前瞻性、广泛性的努力和尝试。在此,本文结合一个最新的案例进行分析。
2014年初,“欧洲新闻学研究中心”将推出一门题为“数据新闻学:关键步骤、技能、工具”的网络公开课,由来自高校的新闻学教授和来自推特等社交媒体的业内专家共同执教。[8]该课程由五个在线教学模块组成,通过讲义、视频、论坛等手段,重点传授记者如何获取大数据、如何从中有效挖掘出“故事”和“洞见”及制作“可视化新闻”的技巧。这五个模块涵盖了“数据新闻学”在新闻生产实践中的各个关键环节,细致清晰地勾勒出数据新闻生产与传播的脉络,值得一一介绍。课程的“起始模块”首先利用丰富的实例,阐释“数据新闻学”的内涵,对数据新闻生产的流程进行生动而具体的展示。“模块二”重点教授学生如何挖掘出支撑新闻故事所需的各项数据,包括培养学生对常用数据信息源的“敏感度”和使用简易、省时的搜索引擎的技能。“模块三”利用电子制表软件和基础数据,在帮助学生在做好数据挖掘的基础上,对已收集数据进行细致的理解和分析,从而更好地以此支撑新闻文稿的撰写。“模块四”指导学生在基本数据挖掘的基础上进行更深层次的数据信息分析,对信息进行精密细致的“过滤”,最终从鱼龙混杂的海量数据中筛选出最有价值的数据。最后一个模块会对“可视化新闻”进行详细的讲解,教会学生如何把抽象的数据转化成生动的故事、图表、视频和其他视觉互动形式(如动漫、数字高程模型或称DEM、卫星导航图等),以期启发受众形成对新闻事件的深入认知和“洞见”。
大数据时代的口号是“一切皆可量化”,“数据新闻学”作为一门应运而生的学科分支,越来越受到学界和业界的关注和重视。数据新闻利用精细准确的大数据信息及交互、可视的多媒体技术,正在逐渐替代仅依托“文本配图片”式的传统报道模式。从理念上说,数据新闻已从简单描摹事件的表层现象转为深入挖掘其内在本质。近年来,数据新闻在中国也正蓄势待发。在学界,一些高校的新闻院系与国际一流媒体强强联手,开始设置“财经新闻数据挖掘与分析”(清华大学全球财经新闻硕士项目与彭博新闻社合作开设)、“数据新闻学”(香港大学新闻及传媒研究中心与路透社合作开设)等相关课程,致力于培养适应大数据时代新闻生产需要的媒体人才。在业界,一些国内知名媒体也在积极探索和践行数据新闻,以期提高自身的报道质量与影响力,如“新浪图解新闻”、“网易新闻数读”、“搜狐数字之道”等。随着中国经济社会快速发展,国民媒介素养不断提升,可以预见到数据新闻在中国未来广阔的发展前景。为了更好地适应大数据时代的新闻传播变局,中国新闻界应该继续深入思考,开拓创新,鼓励和引导受众挖掘数据,认知数据,与数据进行互动,从而更好地发挥数据新闻在信息传播、公众沟通、舆论监督等方面的重要作用。
[1] Victor Mayer- Sch渀戀攀爀最攀爀, Kenneth Cukier
:《大数据时代:生活、工作思维的大变革》[M],盛杨燕,周涛译,杭州:浙江人民出版社,2013.1
[2] 方洁:《全球视野下的“数据新闻”:理念与实践》,《国际新闻界》[J],2013年第六期
[3] 郭晓科:《数据新闻学的发展现状与功能》,《编辑之友》[J],2013年第八期
[8] http://www.datadrivenjournalism.net/course/
http://blog.sina.com.cn/s/blog_81651ac20101rh5r.html
作者: admin 时间: 2014-2-28 22:51
【案例】高永亮博士
//@沈浩老师: //@周老老:【知识+信息】现在大数据很火,但是有多少人关心其中蕴含的科学与技术内容呢?
◆◆
@数据挖掘与数据分析
【基础知识:统计学和数据挖掘区别】统计学和数据挖掘有着共同的目标:发现数据中的结构。事实上,由于它们的目标相似,一些人(尤其是统计学家)认为数据挖掘是统计学的分支。这是一个不切合实际的看法。因为数据挖掘还应用了其它领域的思想、工具和方法,尤其是计算机学科,例如数据库技术和机器学习
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(53)[/url]| 轉發(414) | 評論(65)
2月27日07 : 14來自iPhone客户端
[url=]
[/url]| [url=]轉發[/url]| [url=]收藏[/url]| [url=]評論[/url]
6分鐘前 來自iPad客户端
作者: 刘海明 时间: 2014-3-3 10:25
本帖最后由 刘海明 于 2014-3-3 10:28 编辑
【案例】
媒体统计各国民众每周阅读时间 印度近11小时居首
新华网3月3日电 据科技博客网站Gizmodo报道,随着电脑和移动设备的广泛普及,人们阅读的时间相对下降了许多,上面这张名为“全球各地的阅读者”的数据图清晰地展示了世界各国民众每周用在阅读上的时间。
一项研究报告显示,美国人要比世界其他国家或地区国民的阅读时间少得多。这一数据来自NOP世界文化评分指数,并由@Amazing Maps 据此绘制出了一幅地图。印度国民的阅读时间雄踞第一位,每周的阅读时间长达10小时42分,美国则“愚钝地”排在第22位,美国人每周只阅读5小时42分钟,下面是完整的名单:
1. 印度——10小时42分
2. 泰国——9小时24分
3. 中国——8小时
4. 菲律宾——7小时26分
5. 埃及——7小时30分
6. 捷克共和国——7小时24分
7. 俄罗斯——7小时06分
8. 瑞典——6小时54分
8. 法国——6小时54分
10. 匈牙利——6小时48分
10. 沙特阿拉伯——6小时48分
12. 香港——6小时42分
13. 波兰——6小时30分
14. 委内瑞拉——6小时24分
15. 南非——6小时18分
15. 澳大利亚——6小时18分
17. 印度尼西亚——6小时
18. 阿根廷——5小时54分
18. 土耳其——5小时54分
20. 西班牙——5小时48分
20. 加拿大——5小时48分
22. 德国——5小时42分
22. 美国——5小时42分
24. 意大利——5小时36分
25. 墨西哥——5小时30分
26. 英国——5小时18分
27. 巴西——5小时12分
28. 台湾——5小时
29. 日本——4小时06分
20. 韩国——3小时06分
与此同时,数据显示,美国则在其他不太费脑筋的项目上占据领先地位,比如,美国人看电视时间全球排名第五,每周有19小时。不过,在非工作互联网使用时长方面,美国只排在19位,每周大约9个小时,这一结果有些奇怪,因为每天有那么多美国人花那么多时间在刷Facebook。数据还显示美国人每周听广播的时间长达10个半小时,但是小编感觉现实中,人们坐在车里聊天的好像比听广播的更多。
http://world.163.com/14/0303/09/9MDCLDG000014JB5.html
作者: 刘海明 时间: 2014-3-4 00:28
【案例】
传播小王子
右边所言极是,《爆发》里说,94%的人类行为都可预测。难在得出预测模型。//@cnsns:不能仅满足用所谓“数据”报道过去事件,进一步是论证事件,更要用数据去预测事件,更牛是用数据影响事件的走向。我说的“事件”,可以理解为新闻。无论如何,把事件单位粒度变小,会使整个社会生态发生巨大改变。
◆◆
@传播小王子
【大数据与新闻生产】新闻联播和焦点访谈都在采用大数据来解读新闻事件,这的确是一个方向。个人对此颇有兴趣,也做了一些尝试。感觉目前学界和业界做的描述性的统计分析、观点的聚类和词频统计已经很成熟了,不知道下一步的研究该是什么呢?
(4)|
轉發(51)
|
評論(11)
3月3日20 : 23來自Android客户端
|
轉發(2)|
收藏|
評論(2)
8分鐘前
來自新浪微博
作者: 刘海明 时间: 2014-3-4 17:03
【案例】
数据挖掘与数据分析
两会的召开直接关系着国计和民生,既然与自己的生活息息相关,咱们又怎么能不好好的关注关注呢?大家都对两会的什么方面感兴趣?在大家的理解之中,两会又是什么概念层面上的东西?我想,这通过手机百度的热搜关键词排行榜就不难看出。
收起|查看大圖|向左轉|向右轉
|
轉發(2)|
收藏|
評論
6分鐘前
來自新浪微博
作者: admin 时间: 2014-3-9 18:53
【案例】@马丁路德纲
有人发现MH370.com域名居然是2014.3.7日飞机起飞之前注册的…是巧合吗?!
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(48)[/url]| 轉發(257) | 評論(75)
今天 16:22來自iPad客户端
作者: admin 时间: 2014-3-15 17:02
【案例】
@Echolley
失联飞机还没找到,国家实力比拼已甚清晰。当中国还在南海和马六甲徒劳搜索,美国根据卫星数据直接派军舰去了印度洋。飞机美国生产,发动机英国制造,卫星数据来自美国,如今重大新闻也都华尔街日报、纽约时报、BBC独家发布了。谁真正掌握着我们的技术、数据、航空空间和信息来源?
(1)|
轉發(17)
|
評論
35分鐘前來自新浪微博
作者: admin 时间: 2014-3-22 20:49
【案例】
@媒介360
【网络时代大数据如何反恐 打通后台消灭信息"孤岛"】互联网时代恐怖分子的一举一动都可能留下数据痕迹。美国反恐手段之一,是通过综合利用恐怖分子各种信息包括通话、交通、购物、交友、电邮、聊天记录、视频等,对恐怖行为发生前进行预警和事后分析排查。(微信:imedia360)http://t.cn/8sG1On5
收起|查看大圖|向左轉|向右轉
|
轉發(4)
|
評論(1)
今天 17:58來自新浪微博
作者: admin 时间: 2014-3-23 09:55
本帖最后由 admin 于 2014-3-23 09:56 编辑
【案例】
北大新媒体
别样思维看“大数据”//@互联网分析沙龙: 【大数据的核心概念】反馈的速度越快,它创造的价值越大,消费者参与的动机就越大。数据越跑越大、反应越来越快、结果越来越好、用户参与会越来越大,才能变成一个黑洞效应。
◆◆
@互联网分析沙龙
【一位文科教授眼中的"大数据"】教授用一张图简洁明了的描述了大数据,通俗易懂,趣味性强,体现的核心是"多、快、好、省",推荐!
收起|查看大圖|向左轉|向右轉
(16)|
轉發(426)
|
評論(29)
1月20日19 : 31來自脉搏网
(5)|
轉發(34)|
收藏|
評論(5)
30分鐘前
來自媒体版微博
作者: admin 时间: 2014-3-25 16:10
【案例】
数据化管理
欧洲上空24小时航线动画//@段洪涛-大数据: MH370事件引发的大数据猜想
◆◆
@星图数据
#大数据为MH370调查提供有力保障# 近日,一副欧洲上空24小时炫彩航线的动画被曝光,24小时内,3万多架航班飞越欧洲上空,总航程4600多万公里,英国全国空中交通管理局将这些航班的雷达飞行数据“编”成一张网。此前,根据英国航空失事调查局调查,MH370坠机位置在印度洋南部。|欧洲上空24小时航线动画(炫彩丝带连接世界)
收起|查看大圖|向左轉|向右轉
<
>
| 轉發(15) | 評論(4)
52分鐘前來自360浏览器超速版
| 轉發| 收藏| 評論
4分鐘前 來自新浪微博 | 檢舉
作者: admin 时间: 2014-3-28 18:07
【案例】
周21cbh斌
这个公式很牛
◆◆
@21世纪网
【寻找MH370:数学公式能帮大忙】http://t.cn/8scnLUZ
(4)|
轉發(21)
|
評論(5)
3月27日14 : 53來自新浪微博
作者: admin 时间: 2014-3-29 10:13
【案例】
肖珺CHINA
//@中国网络传播学会:【小蜜蜂早班车】#海量信息时代的稀缺——专业事实核查#
◆◆
@媒介评弹
【独家分享:海量信息时代的稀缺——专业事实核查!】且看德国《明镜周刊》的事实核查部http://t.cn/zRWc92X《纽约客》杂志事实核查的故事 http://t.cn/hx8XS 《卫报》如何核查阿富汗战争日志 http://t.cn/zRUuQZ6《三联生活周刊》:大数据时代如何进行事实核查http://t.cn/zRUOAwQ
(22)
作者: admin 时间: 2014-4-5 22:49
本帖最后由 admin 于 2014-4-5 22:54 编辑
【案例】
微博小秘书[url=http://verified.weibo.com/verify] [/url]:
[/url]: #周一见#文章,成功抢头条。转发破纪录,热度暂无双!短短四天,有关文章的微博阅读量高达9.5亿,热议微博数猛增56倍!在参与讨论的网友中,70%用户是90后高学历女性;广东、江苏、北京成为最热衷讨论此话题的区域。更详细数据猛戳大图
#周一见#文章,成功抢头条。转发破纪录,热度暂无双!短短四天,有关文章的微博阅读量高达9.5亿,热议微博数猛增56倍!在参与讨论的网友中,70%用户是90后高学历女性;广东、江苏、北京成为最热衷讨论此话题的区域。更详细数据猛戳大图

作者: admin 时间: 2014-4-8 12:33
【案例】
宪阁微观
//@喻国明: 真相不辩不明。支持在程序透明、过程公开的情况下对簿公堂。 //@博联社马晓霖:【支持起诉】我对谣言一向深恶痛绝,支持李董起诉打官司破谣言。我想这也是众网友的共同心愿,不信看评论。
◆◆
@搜狐新闻客户端
【爆料人:李小琳丑闻很多】负责撰写报道的《亚洲周刊》资深特派员纪硕鸣回应,称报道查核资料、详尽数据,铁证如山,却在李小琳的口中成“谣言”,“真相只有一个,是骡子是马拉出来遛遛!”又说李小琳绯闻丑闻很多,目前报道只限公司经济层面,是怕“那些邋遢事脏了干净笔”。(中国经营报)
(135)
(35)| 轉發(1005) | 評論(311
作者: 刘海明 时间: 2014-4-16 08:41
【案例】@微首发
在全球进入“大数据时代”的背景下,中国电视应运而生了一个未来新闻业的重要方向——“大数据电视新闻”。从2014年马年春运春节到2014年的两会,央视一套通过“据说春运(节)”“据说两会”系列,积极地探索了大数据电视新闻的制作流程,为未来创新新闻制作流程奠定了坚实的基础http://t.cn/8sp5flj
[url=](7)[/url]

[url=](6)[/url]| 轉發(18) | 評論(2)
4月14日11 : 39來自微博 weibo.com[url=]7)[/url]
作者: admin 时间: 2014-4-18 20:50
【案例】
@一图观政
【第二期 | 扒一扒各省法院院长:大部分是半路出家】不要抱怨法院院长不懂法!大部分法院院长都是半路出家,他们曾经是——报社评论部编辑、机床厂统计员、兽防站工作人员。并且,许多院长本身就不是扎根法院系统,过半数院长都长期待在法院以外的系统(如党政)。更多精彩请戳大图,图片仅300K。
收起|查看大圖|向左轉|向右轉
作者: admin 时间: 2014-4-19 15:20
【数据】
2013年美国报业收入下降2.6%
2014年04月19日 05:35 新浪财经 微博
新浪财经讯 北京时间4月19日凌晨消息,美国报业协会(NAA)周五发布的数据显示,2013年美国报纸行业收入下降2.6%,至376亿美元,发行收入的增长未能弥补印刷广告需求的萎缩。
发行收入增长3.7%,至109亿美元,连续第二年增长。但广告收入下降6.5%,至236亿美元,其中,数字广告收入增长1.5%,至34.2亿美元,但印刷广告收入下降8.6%,至173亿美元。
发行和广告以外业务带来的营收增长5%,至31.5亿美元。(羽箭)
http://finance.sina.com.cn/world/20140419/053518851224.shtml
作者: 刘海明 时间: 2014-4-23 09:53
【数据】@陈永东
【媒体把我们的时间弄哪去了?】据eMarketer数据,2013年美国成年人在媒体上所花时间排名:1、数字媒体(43.4%);2、电视媒体(37.5%);3、广播电台媒体(11.9%);4、印刷媒体(4.4%);5、其他占2.8%。2013年美国成年人每天花在媒体上的时间人均12小时03分。显然我们花在数字媒体的时间不断增加。

| 轉發(2) | 評論
9分鐘前來自微博 weibo.com
作者: admin 时间: 2014-5-9 13:03
【案例】
转载]女人与大数据 (2014-05-07 13:18:05)
把一些习以为常的事情做出了经典的解释!我就属于那种通过各种蛛丝马迹来判断一个人的人!原来我已经使用大数据这么多年了,继续发扬这种风格!
作者: 屠龙的一口胭脂井
我刚刚拔了智齿,从全身麻醉出来,脑袋不清醒又睡不着。决定写个博客说点胡话,这样醒来可以不负责。这胡话就是这两天脑子里一直盘旋的想法: 大数据时代,就是女性的时代,女性在基因里就会计算大数据。
很多男性和孩子,其实一直奇怪女性这种特殊的能力。比如小时候你刚进家门,妈妈就以狐疑的语气马上说:“刘志军,你今天是不是没考好?”。比如你刚看一眼手机,老婆就笑:“是不是又是隔壁二狗约你打游戏?”。再比如你刚刚关起门打电话,女朋友一会儿就哭了:“你是不是又背我出去找小三?”。
她们有的时候猜对了,有的时候猜错了。但是总体,正确率高于chance level。她们错的时候,男人就撇撇嘴,你们女人就爱胡思乱想;她们对的时候,男人就说,女人就是一种敏感的动物,可能感觉器官就敏锐一些。
不管怎么说,这些瞎猜,总体正确率高于chance level这点,也让男人非常害怕。为了适应这点,男性也形成了相当强的反侦察技能。这部分超出了本文的scope,就在此不再细表。
有一些research,比如Hanna Holmes的paper指出,女性大脑的白质(用于连接各种区域的解剖组织)高于男性所以把事物连接在一起想象的能力强。也有最近研究表明,女性对“日期”记忆能力强于男性,所以能记住所有生日,纪念日,甚至不重要朋友的一些重大日子。
不管这些结果的真实性,我觉得,这都不是女性最卓越的能力。女人最卓越的能力是长期追踪一些看似不重要的数据,形成自己的baseline和pattern。一旦这些数据点的pattern,显著不同于她所熟悉的baseline,她就知道反常。女人在日常生活中不考虑什么causality和correlation的区别,俺们信奉的原理就是:“事出反常必有妖”。
讲大数据的人经常讲林彪的例子。林彪打完一张战役,就认真记录一些非常细节不重要的数据,比如缴获枪支,长枪和短枪的比例,战俘的年龄层次,缴获的粮食是高粱还是小米等等。都事无巨细记在本子上面。别人都笑他。但是后来,他就用这些数据来判断哪个地方是敌军指挥部。
女人的干的事情,基本雷同。一个女孩A暗恋男孩B,但通常不直接联系,过了两天我问她要不要叫他一起吃饭,她说,他正在打球。我说你怎么知道?
她说,男孩B平时是早上8点在gmail邮箱上线,8点半呈现away状态,这是他出去买咖啡早饭了。9点再次上线后busy,这是在工作,12点半再次away就是午餐,晚上一直在线,可能是读paper或打游戏。其哥们C,早上十点上线,全天在线,然后夜里2点还在线上,这是一个晚睡晚起的男生。其另一个哥们D,全天Busy,但是大多数时间都在。但是重要的pattern是,每星期有2-3天,他们一起离线或者away 3-4个小时。结论:他们在一起打球。
我听了以后跪服。我说,你真太棒了,这就是大数据。有人说,真是闲的无聊,难道不能直接问?生活里的小事,随便问问当然无所谓,但是在社交场合不合适问的事情,用大数据能得到答案,难道不是一种卓越能力吗?
最近出了几篇paper,通过data mining人在社交网络上点赞的规律,来预测人的智商,兴趣,等等。其实这种事情,女性经常干。哪个女生敢说,自己没在party之前把所有宾客都google了个底朝天?在刚开始谈恋爱的时候,把对方的博客,微薄,facebook,亲朋好友的博客,微薄,facebook翻了个底掉?
反正我干过:)。信息时代嘛,我干这种事情毫无羞耻心并且认为丝毫不是浪费时间。交朋友,谈恋爱,是比买车买房更重要的事情,产生更深远的影响,所以做背景调查相当重要,对于陌生人尤其重要。
话扯远了,最后扯回到,妈妈当初是怎么看出你考试没考好的,老婆是怎么看出你要出去打游戏,女友怎么怀疑你找了小三的。她们每天都用眼睛观察你眼睛的gaze,看了什么,盯了几秒,你洗脸刷牙需要多长时间,多长时间刮一次胡子,你把拖鞋放在哪里,在饭桌上说多少话。
如果你哪天,盯着手机的时间比以往长,牙膏突然挤到水池边,没到重大节日突然刮胡子,拖鞋突然放得很整齐,在饭桌上一句话没有,饭后很快很轻很轻地进了另一间屋子,又很轻很轻把门关上。
这些pattern集合在一起,就是“事出反常必有妖”。小时候当你有鬼心思,你妈妈总是第一次猜到,她总是得意的说:“你是我生的,你怎么想我还不知道?”。实际真正的trick并不是她生了你。
是因为她爱着你,她一直细致入微地观察着你,mentally记录着你的bio-signal,才能达到如此神乎其神的程度。
没有任何sensor和algorithm能达到母亲的程度,但希望未来能有sensor和algorithm近似于母亲的贴心,达到数据时代为人带来的真正便利。
我脑子真的不行了,马上要去睡觉。说两句总结,
第一,女性要相信自己入微的观察和大数据能力,并且把这种能力用在更high level的地方,一定能在这个时代有更强大竞争力。
第二,妈妈,我爱你。
http://blog.sina.com.cn/s/blog_8a28b4270101qp50.html
作者: admin 时间: 2014-5-9 20:21
【案例】联合国
[道路安全]在高收入国家,行人碰撞往往发生在城市街道,而在低收入和中等收入国家,碰撞则更常见于连接城市和郊区的干道上。绝大多数行人碰撞发生在行人横穿马路时,而非沿道路行走或驻足街道时。全世界行人死亡和伤害中的大部分发生在清晨、黄昏和夜间等照明条件不足的情况下。
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(5)[/url]| [url=]轉發(16)[/url]| [url=]收藏[/url]| [url=]評論(3)[/url]
9分鐘前 來自联合国
作者: admin 时间: 2014-5-14 09:44
【案例】
包蓓蓓
赞,有趣!#DataJournalist# 在学校的时候也选修过数据新闻课程,这确实是一种趋势。而且对记者没有语言限制,只要创意够好、可视化够吸引人就好。国内这方面的内容还很缺乏。大有可为。 //@老杜找乐儿:这个实在是太牛逼了。PO主是NYU的同学。
◆◆
@周宗珉
听上去有些不可思议?——是的,《纽约时报》发表了我的期末作业。 http://t.cn/RvvPDyT
作者: admin 时间: 2014-5-14 20:39
【案例】
数据是如何”说谎“的2014-05-14 [url=]全媒派[/url]
「数据会说谎」的真实例子有哪些?究竟是数据在说谎,还是逻辑在说谎?
想象你明天要跟你的经理作报告,手里有一堆结果,但是显然这些结果对于之前的方法只有边际的增长——但人类永远是聪明的,他们会找到各式各样的方法在数据变化不大的时候给人造成视觉冲击。所以媒体人,在分析使用数据的时候,一定要睁大你们的双眼哟!
截图说话——美国 Fox news 经常用的一些招数。这些招数更多的是从视觉上给人一种“错觉”。比如说,本来不大的差异,截掉 Y 轴的一部分,瞬间差异就会让看的人觉得——差得这么多!
例子:
1、在趋势图中,为了说明增长趋势多明显,把 Y 调成不从 0 开始。这样差距会看起来很大,增长很大,但是如果把 Y 轴从 0 开始看的话,会显得基本没有差距。
差距够大吧!巨量增长啊!我们公司的财务情况这样的话,公司明年就得 IPO 啊!可惜 Y 从 0 开始的话,这图应该看起来的样子是:
p.s.刚发现在用 Excel 画这图的时候,excel 都自动把 Y 轴的起始值调成比最小值多一点!这样看起来差距真是巨明显有没有!看来微软真是很懂画图的真正需求啊。
2、作两两比较的时候把 Y 的值从高位开始,造成俩差距巨大的错觉。
看啊,右边比左边高了 4 倍不止!!!咦,等等,不是就 39.6%跟 35%的差别吗....这...
3、分数加起来不等于一,放大差距。
图上的数据 normalize 一下的话那么佩林是 36.2%,32.6%,31.0%,直观差距不大。但是在这个饼型图里瞬间变成了 10%的差距!这个比较明显的话那看下面,一扫的话没发现这里百分数加起来不等于 1 了吧。
4、 挑取 x 轴的数据以捏造趋势
假设数据的波动性很大,比如说如下:10, 1, 20, 3, 30, 4, 50,看起来应该是
公司的财务状况这么不稳定!怎么办?没关系——如果我只抽取奇数项的话(挑取 x 轴,虽然挑得好像是很有系统地——奇数,但是你总能想到一个看着挑得系统的方法),
就会看着像
这样明年又可以上市了...
部分图片来源于simplystatistics.org
文章来源:知乎日报
http://mp.weixin.qq.com/s?__biz=MzA3MzQ1MzQzNA==&mid=201051754&idx=4&sn=7f8922fb86fddeed6e5d151d67715ba9#rd
作者: admin 时间: 2014-5-19 13:05
【案例】
@数据堂
【在大数据时代,相亲也要采取新思维!】近日,一篇关于“剩女脱光新技能”的经验分享帖引发网友热议。帖子里讲述了一位剩女如何用互联网思维搞定男神的经历,一语中的地告诉大家:“剩斗士”们之所以年复一年地奔忙在相亲路上,很可能是因为方法不正确哦。http://t.cn/RvZXBkf
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(2)[/url]| 轉發(6) | 評論(4)
今天 10:27來自微博 weibo.com
作者: admin 时间: 2014-6-7 08:53
【案例】
恐怖的大数据!
某比萨店的电话铃响了,客服人员拿起电话。
客服:XXX比萨店。您好,请问有什么需要我为您服务?
顾客:你好,我想要一份……
客服:先生,烦请先把您的会员卡号告诉我。
顾客:16846146***。
客服:陈先生,您好!您是住在泉州路一号12楼1205室,您家电话是2646****,您公司电话是4666****,您的手机是1391234****。请问您想用哪一个电话付费?
顾客:你为什么知道我所有的电话号码?
客服:陈先生,因为我们联机到CRM系统。
顾客:我想要一个海鲜比萨……
客服:陈先生,海鲜比萨不适合您。
顾客:为什么?
客服:根据您的医疗记录,你的血压和胆固醇都偏高。
顾客:那你们有什么可以推荐的?
客服:您可以试试我们的低脂健康比萨。
顾客:你怎么知道我会喜欢吃这种的?
客服:您上星期一在中央图书馆借了一本《低脂健康食谱》。
顾客:好。那我要一个家庭特大号比萨,要付多少钱?
客服:99元,这个足够您一家六口吃了。但您母亲应该少吃,她上个月刚刚做了心脏搭桥手术,还处在恢复期。
顾客:那可以刷卡吗?
客服:陈先生,对不起。请您付现款,因为您的信用卡已经刷爆了,您现在还欠银行4807元,而且还不包括房贷利息。
顾客:那我先去附近的提款机提款。
客服:陈先生,根据您的记录,您已经超过今日提款限额。
顾客:算了,你们直接把比萨送我家吧,家里有现金。你们多久会送到?
客服:大约30分钟。如果您不想等,可以自己骑车来。
顾客:为什么?
客服:根据我们CRM全球定位系统的车辆行驶自动跟踪系统记录。您登记有一辆车号为SB-748的摩托车,而目前您正在解放路东段华联商场右侧骑着这辆摩托车。
顾客当即晕倒。
来源:http://www.dapenti.com/blog/more.asp?name=xilei&id=90429
作者: admin 时间: 2014-6-14 09:42
本帖最后由 admin 于 2014-6-14 09:43 编辑
【案例】
外媒:过去一年中国至少180人在暴恐案中身亡
新疆乌鲁木齐中院13日公开审理“北京10·28严重暴力恐怖案”相关涉案犯罪嫌疑人。此前,新疆维吾尔自治区人民检察院官方网站发布了该案信息:2013年10月28日12时许,北京天安门广场前发生严重暴力恐怖案件,3人驾乘吉普车闯入长安街便道,致2人死亡,40人受伤。嫌疑人点燃汽油致车辆起火。案件发生后,公安机关先后抓获8名犯罪嫌疑人。今年5月30日,乌鲁木齐市人民检察院以组织、领导、参加恐怖组织罪和以危险方法危害公共安全罪对上述8名嫌犯提起公诉。
英国广播公司(BBC)13日报道称,这起袭击事件是“多年来北京发生的第一起类似事件”。报道称,在过去一年里,有至少180人在中国各地发生的类似攻击行动中死亡。中国政府将这些极端攻击事件归咎于新疆地区的伊斯兰激进主义和分离主义运动。
《环球时报》记者注意到,新疆公检法部门近来加大了重拳严打暴恐分子的力度:6月13日公审当天,新疆伊犁哈萨克自治州召开新闻发布会,通报了近期查处的10起党员干部散布违背党和国家路线方针政策、损害民族团结言论案件,其中2起案件涉及传播邪教。所涉人员当中包括伊犁州政府办公厅党组成员巴图尔·杜瓦买提、察布查尔县水利局退休干部王荣芳等。记者注意到,10名涉及人员在不同行业和部门工作,既有少数民族干部,也有汉族干部。
本月4日,乌鲁木齐市人民检察院发布消息称,根据自治区严厉打击暴力恐怖活动专项行动工作部署,市检察院侦查监督部门迅速组织专案小组,做到案件“当日受理当日审结、最迟不超过48小时”。6月5日,新疆塔城、乌鲁木齐、阿克苏、克州、喀什、和田等人民法院对23案81名被告人公开宣判,分别以组织、领导、参加恐怖组织罪,故意杀人罪、放火罪等判处各被告人死刑、无期徒刑及有期徒刑。其中9人被判处死刑,3人被判处死刑,缓期两年执行。
新疆快速重拳严惩暴恐分子引发国际媒体的高度关注。法新社12日报道称,流亡在外的“穆斯林维吾尔人”组织宣称,新疆的不稳定与不安全是因为“中国政府的文化压制”和“强硬的安全措施”所致,汉族的移民导致“社会与经济发展的不公平”。不过,法新社也表示,中国政府宣称,新疆的不安全是因为恐怖组织所致,中国政府正在努力提高当地民众的生活水平。法新社还声称,新疆的新闻管控“很严厉”,许多消息“无法证实”。对此,《环球时报》记者却有不同的体会,事实上,新疆近年来发生影响比较大的暴恐事件时,外国驻华记者总是能“第一时间”出现在新疆,不知法新社记者对“新闻管控很严厉”的体验从何而来。自治区分管媒体的官员也证实:“这些记者来得比中国记者都快,而且会迅速出现在事发地。”
路透社12日在报道近几周新疆警方集中逮捕和审判暴恐分子的消息时,援引香港科技大学学者戴维·扎维格的话说:“建设更加公平的系统是防止极端思想扩散的真正良药。中国现在处于非常困难中,急需长远和短期的解决办法。”
然而,新疆当地民众的看法似乎与西方媒体有极大不同。新疆西域律师事务所律师吴建民13日对《环球时报》说:“对这批暴恐分子的判决,体现出从中央到地方,对暴恐分子都采取了严格的司法手段,这种打击力度符合新疆当前的形势需要。”
病中的新疆社科院退休干部塔伊尔江·穆罕默德表示,当他看到“新疆集中宣判一批涉暴恐案件”的消息后,“精神好了许多”。他说,既然暴恐分子非要破坏新疆的社会稳定、阻碍新疆的经济发展、抹黑新疆的形象,那么国家的法律就要顺应民意,打击他们的恐怖气焰。
美籍华人、新疆大江投资有限公司董事长江庆云表示,公审暴恐分子让他有畅快淋漓的感觉:“这是一件大事,对新疆各族人民太重要了,不只新疆人民,全世界所有善良的人都很赞成这件大好事。”他希望严打战役要一直打下去。南航新疆分公司工作人员张继表示,只要新疆各族群众团结起来,保持对暴恐分子予以严惩的高压态势,就能确保新疆社会稳定和长治久安。
(原标题:新疆公审驾车撞金水桥暴恐分子 引发外媒关注)
本文来源:环球时报 作者:邱永峥
http://news.163.com/14/0614/07/9UMCJ2BE00014JB6.html
作者: admin 时间: 2014-6-16 12:57
【案例】
大数据偷了你隐私你知道吗
文/新浪财经专栏作家 董希淼
大数据是座金矿,背后隐藏着大量的经济与政治利益。而通过数据挖掘,人类所表现出的数据整合与控制力量远超以往。但大数据是把“双刃剑”,国家和企业因大数据获益的同时,个人隐私的保护却从此变得更加艰难。
大数据是把“双刃剑”
最近,关于数据与信息安全的新闻一条接着一条:
4月2日,马云[微博]旗下的公司拟收购恒生电子(29.84, -0.12, -0.40%),据说收购方看重的不仅是恒生的金融电子平台,更有恒生的后台数据资料,因为据此分析金融客户的交易行为,成就阿里金融大数据梦想。
5月28日,媒体报道称,我国政府正在推动国内银行放弃使用IBM[微博]高端服务器,此前已经将Windows 8系统列入政府采购黑名单,并要求国有企业切断与美国咨询公司的业务往来。
6月6日,中信证券(11.46, 0.13, 1.15%)医药行业首席分析师张明芳在其微信群发布了丽珠集团(47.90, -1.05, -2.15%)即将公布股权激励方案的消息。消息一出,众多基金经理纷纷退群并截屏转发,一些投资者甚至不惜追高买入。
而在个人隐私方面,日前网上流传了一个关于买比萨的段子: 一个客户打电话订购比萨,客服人员马上报出了他的所有电话和家庭住址,推荐了他适合的口味,报出他最近去图书馆借过什么书,信用卡已经被刷爆,了解他房贷还款金额,知道他丈母娘刚动过心脏搭桥手术,甚至还准确定位出他正在离比萨店20分钟路程的地方骑着一辆摩托车……
段子虽然有点夸张,但在这个时代,信息安全却是我们不得不面对的一个问题。尤其是个人隐私的问题,正越来越困扰我们身边的很多人。
每当我们上网、使用手机或者信用卡,我们的浏览偏好、采购和行为都会被记录和追踪。或者,在我们根本没有意识到的时候,智能设备便处于联网之中,相关数据被悄然发送到第三方。
于是,我们的邮箱里塞满了各种推销邮件,我们的手机里充斥着各类垃圾短信,我们的电话中夹杂着各色推销广告……甚至,我们一些基于私人爱好的搜索行为,会在大庭广众之下出现在令人难堪的大幅广告。更有甚的是,犯罪团伙通过关注和分析父母的微博、微信,组织了绑架孩子等恶性事件。在去年的3•15晚会上,央视用Cookies提出了互联网上隐私泄漏和侵犯的问题。
2012年底,《纽约时报》刊文宣称,“大数据时代”(Age of Big Data)已经来临。巴拉巴西在《爆发:大数据时代预见未来的新思维》中提出,93%的人类行为能够通过有效的数据分析而进行预测。在物联网、云计算、社交网络的催生下,互联网时时刻刻释放出海量数据。大数据是座金矿,背后隐藏着大量的经济与政治利益。而通过数据挖掘,人类所表现出的数据整合与控制力量远超以往。但大数据是把“双刃剑”,国家和企业因大数据获益的同时,个人隐私的保护却从此变得更加艰难。
对马云的收购行为,据说商务部正在进行反垄断调查;银行能否放弃IBM服务器可以商榷,但信息安全警钟已经敲响;中信证券的分析师因泄露内幕信息,目前正被停职调查。而我们,也到了不得不认真地思考个人隐私保护问题的时候了。
可以采取的措施有:
首先,明确立法。2012年全国人大常委会作出了关于加强网络信息保护的决定,但立法的缺失仍是我们目前存在的严重问题。要做好顶层设计,积极推动立法,建立个人隐私保护的法律法规和基本规则。尤其是,要通过立法,大幅度提高隐私泄露和侵犯的违法成本。
其次,加强监管。应建立大数据产品在个人信息和隐私安全方面的国家标准,明确个人信息和隐私具有财产属性,严格限制以营利为目的的企业,对个人隐私等信息进行商业化利用。通过加强政府监管,加大对侵害个人隐私行为的打击力度,。
再次,行业自律。大数据时代的个人隐私,构成现代商业服务和网络社会运行管理的基础。应积极提倡互联网公司、商业银行、保险公司等相关企业自重、自律,并制定行业标准或公约。特别是行业的龙头企业,要带头做“业界良心”。
最后,客户授权。客户是隐私信息的主人,对个人隐私拥有最终的决定权。在部署数据采集和分析行为时,应充分告知客户,让客户了解后果并做出选择。只有客户发起个性化需求时,才可以对客户信息进行调用,否则就视作侵犯隐私。
大数据带来了很多便利,影响决策,也改变了生活。但大数据分析和应用,有时候往往偏离了其精神实质。当下,世界杯足球赛正在巴西进行得如火如荼。如果我们可以通过大数据精确地分析出各场赛事的进球时间、比赛得分的话,那么竞猜结果、熬夜观看的乐趣还会有吗?人类不是机器,生活有时候并不需要十分精确,未知也是一种美好。
那么,什么是大数据精神?
很多人认为,“开放、分享”是大数据时代的主要精神。我以为,这是大数据本身所具有的特点,而不是大数据时代的精神。大数据并不只是指数据的采集与贩卖,更重要的是指通过对于客户信息和行为数据的分析、整理,帮助企业加深对于客户需求的认识和理解,从而通过精准营销、个性服务,挖掘和满足客户真实需求,改善和提升客户体验。只有尊重客户隐私并因此获得客户信任,大数据才能真正发挥作用,才能走得更远。从这个意义上讲,“尊重客户,改善体验”,才是大数据的精神实质。
所以,当马云津津乐道于分享他们所占有的海量信息时,当平安银行(10.12, 0.41, 4.22%)信誓旦旦要转化平安保险7000万客户时,当百度[微博]联手兴业银行(10.11, 0.23, 2.33%)虎视眈眈开发大数据时,我想应该问他们一句:你这么聪明,你的客户知道吗?
http://club.kdnet.net/dispbbs.asp?boardid=1&id=10135730
作者: admin 时间: 2014-6-18 06:57
【案例】
去年全国350万对夫妻离婚 离婚率连续10年递增
2014-06-18 03:17:14 来源: 京华时报(北京) 有9人参与
京华时报(微博)讯 昨天,民政部发布2013年社会服务发展统计公报。公报显示,2013年全国依法办理离婚手续的共有350.0万对,比上年增长12.8%,这是自2004年以来,我国离婚率连续10年递增。
公报数据显示,去年各级民政部门和婚姻登记机构共依法办理结婚登记1346.9万对,比上年增长1.8%。其中25-29岁办理结婚登记占结婚总人口比重最多,占35.2%,比上年提高1个百分点。
同时,2013年依法办理离婚手续的共有350.0万对,比上年增长12.8%,粗离婚率为2.6‰,比上年增加0.3个千分点,其中民政部门登记离婚281.5万对,法院办理离婚68.5万对。
据了解,自2004年开始,我国离婚率便出现逐年递增的情况。2004年,我国的粗离婚率仅为1.28‰,2010年突破2‰。到2013年,已经高达2.6‰。
本文来源:京华时报 。作者:陈荞
http://news.163.com/14/0618/04/9V0DGS5E0001124J.html
作者: admin 时间: 2014-6-22 09:55
【案例】@历史解密网站
中国姓氏最新排名,看看您的姓能排第几!
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
作者: admin 时间: 2014-6-24 19:00
【案例】
独家编译 | 《纽约时报》支招如何运营数据新闻2014-06-24 腾讯新闻 [url=]全媒派[/url]

编者按:在“数据新闻”炙手可热的今天,数据已深入媒体的骨髓血脉,成为记者无法剥除的领域。数据的使用可以丰富新闻的消息来源,方便记者进一步挖掘选题、拓展新闻深度。但面对枯燥无味的数据,长期与新讯息为伍的记者似乎总是无从下手。然而,《纽约时报》旗下数据网站的开发者Derek Willis却认为,“采访数据”比“采访人”更有趣。下面,就让我们看看在2014年新闻行业交流大会上,他对处理数据新闻有何高见。

2014年新闻行业交流大会近期在马里兰大学菲利普梅林新闻学院举行,在会议的第二天,《纽约时报》旗下数字数据网站The Upshot的开发者Derek Willis发表了演讲,与听众一同分享如何处理数据这一议题。
本次大会在马里兰大学举行,AJR(American Journalism Review)是这次大会的出版合作伙伴。
数据新闻运营五大建议
关于数据新闻,Willis说,记者并不需要很精通这些数据,他们需要的只是一个聪明的头脑。
他还表示,其实处理数据的方法和采访人很相似。记者都希望进一步了解这个对象,想发现这里面有什么内容。数据也是一样,即探索某个数据有何意义,与何相关。
在会上,Willis为如何处理数据新闻提出了几点建议:
1、记者必须始终对数据抱有怀疑态度。数据存在的问题往往不是从表面就能看出的,而是很根本性的问题。所以从一开始,记者心里就要有一个假设:这个数据可能存在差错。
2、尽快给数据分类。这里要记者要清楚你要处理的是什么数据。例如,处理警方逮捕记录的数据时,可能需要按照被逮捕者的年龄、罪名与地址分类。若有些数据存在缺失,还需要去除某些分类。他还指出,在Excel上做的数据统计有时会导致混乱,比如它会把警方标号的5-1-1改换成 5/1/01。
3、把数据视为消息来源。但是这同与个体的消息来源打交道不同,数据不会分辨你问的问题是否恰当。所以在处理数据前,你需要把需要了解的问题写下来,甚至大声读出来,看是否合理恰当。
4、多使用数据过滤工具。在这里,Willis建议应当摈弃低效率的Ctrl-F或Command-F组合键。尽管数据过滤工具只能在Excel中使用,但是在基于SQL的程序中有强大功能。记者需要先从宏观入手,再进一步简化问题。他说,“因为规则是很具体的,所以我们也必须从细微着手。”
5、注意数据的改动与翻译,并及时备份。Willis说,这是因为你输入的越多,出错的几率也就越大。

把数据视为采访对象
有时政府机构会把数据公开放在网络上,认为这样可以避免再跟记者打交道。但是这些数据通常不好解读,在这样的情况下,记者就需要另外做整合报道。
而数据的伟大之处在于它让你把新闻报道视为一个问题去探究,而不只是简单的文字陈述。
Willis因此指出,对待数据他有时候更像个局外人,而非一名记者。他之前报道国会新闻时,总是半开玩笑地说他更愿采访一堆数据而不是政客。
数据浪潮来袭
Willis说很多记者甚至不用学习就能很好的使用数据。尽管我们现在生活在一个前所未有的数据化时代,但其实了解Excel等软件一点都不难,只要你愿意下功夫。
但无论如何,数据新闻的大潮不可抗拒。如果没有学过怎么处理数据,记者会发现很多报道都超出他们的能力范围之外,他们根本没办法进行报道。
本文由腾讯新闻旗下产品“全媒派”独家编译,转载请注明出处。
http://mp.weixin.qq.com/s?__biz=MzA3MzQ1MzQzNA==&mid=201428051&idx=1&sn=305c3ddf77d38b8637c3a6a29abfc669#rd
作者: admin 时间: 2014-6-25 22:08
【案例】
数据化管理
【一图看懂房屋空置率到底多高】2013年中国住房空置率为22.4%,你相信吗?http://t.cn/RvOB9xX
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(12)[/url]| [url=]轉發(13)[/url]| [url=]收藏[/url]| [url=]評論(5)[/url]
24分鐘前 來自微博 weibo.com | [url=]檢舉[/url]
作者: admin 时间: 2014-6-29 12:00
【数据】
@时代迷思
【一张图让你掌握经济学的内涵】这是经济学必读的一张图,经典得一塌糊涂!
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(784)[/url]| 轉發(2719) | 評論(217)
6月28日20 : 00來自皮皮时光机
作者: admin 时间: 2014-6-30 00:09
【案例】
REVIEW ARTICLESBig Data and Its Technical Challenges
By H. V. Jagadish, Johannes Gehrke, Alexandros Labrinidis, Yannis Papakonstantinou, Jignesh M. Patel, Raghu Ramakrishnan, Cyrus Shahabi
Communications of the ACM, Vol. 57 No. 7, Pages 86-94
10.1145/2611567
CommentsVIEW AS:
PrintACM Digital LibraryFull Text (PDF)In the Digital EditionSHARE:
[url=]Send by email[/url][url=]Share on reddit[/url][url=]Share on StumbleUpon[/url]
[url=]Share on Tweeter[/url][url=]Share on Facebook[/url]MORE SHARING SERVICES
Share

In a broad range of application areas, data is being collected at an unprecedented scale. Decisions that previously were based on guesswork, or on painstakingly handcrafted models of reality, can now be made using data-driven mathematical models. Such Big Data analysis now drives nearly every aspect of society, including mobile services, retail, manufacturing, financial services, life sciences, and physical sciences.
Back to Top
Key Insights
As an example, consider scientific research, which has been revolutionized by Big Data.1,12 The Sloan Digital Sky Survey23 has transformed astronomy from a field where taking pictures of the sky was a large part of an astronomer's job to one where the pictures are already in a database, and the astronomer's task is to find interesting objects and phenomena using the database. In the biological sciences, there is now a well-established tradition of depositing scientific data into a public repository, and also of creating public databases for use by other scientists. Furthermore, as technology advances, particularly with the advent of Next Generation Sequencing (NGS), the size and number of experimental datasets available is increasing exponentially.13
The growth rate of the output of current NGS methods in terms of the raw sequence data produced by asingle NGS machine is shown in Figure 1, along with the performance increase for the SPECint CPU benchmark. Clearly, the NGS sequence data growth far outstrips the performance gains offered by Moore's Law for single-threaded applications (here, SPECint). Note the sequence data size in Figure 1 is the output of analyzing the raw images that are actually produced by the NGS instruments. The size of these raw image datasets themselves is so large (many TBs per lab per day) that it is impractical today to even consider storing them. Rather, these images are analyzed on the fly to produce sequence data, which is then retained.
Big Data has the potential to revolutionize much more than just research. Google's work on Google File System and MapReduce, and subsequent open source work on systems like Hadoop, have led to arguably the most extensive development and adoption of Big Data technologies, led by companies focused on the Web, such as Facebook, LinkedIn, Microsoft, Quantcast, Twitter, and Yahoo!. They have become the indispensable foundation for applications ranging from Web search to content recommendation and computational advertising. There have been persuasive cases made for the value of Big Data for healthcare (through home-based continuous monitoring and through integration across providers),3 urban planning (through fusion of high-fidelity geographical data), intelligent transportation (through analysis and visualization of live and detailed road network data), environmental modeling (through sensor networks ubiquitously collecting data),4 energy saving (through unveiling patterns of use), smart materials (through the new materials genome initiative18), machine translation between natural languages (through analysis of large corpora), education (particularly with online courses),2 computational social sciences (a new methodology growing fast in popularity because of the dramatically lowered cost of obtaining data),14systemic risk analysis in finance (through integrated analysis of a web of contracts to find dependencies between financial entities),8 homeland security (through analysis of social networks and financial transactions of possible terrorists), computer security (through analysis of logged events, known as Security Information and Event Management, or SIEM), and so on.
In 2010, enterprises and users stored more than 13 exabytes of new data; this is over 50,000 times the data in the Library of Congress. The potential value of global personal location data is estimated to be $700 billion to end users, and it can result in an up to 50% decrease in product development and assembly costs, according to a recent McKinsey report.17 McKinsey predicts an equally great effect of Big Data in employment, where 140,000–190,000 workers with "deep analytical" experience will be needed in the U.S.; furthermore, 1.5 million managers will need to become data-literate. Not surprisingly, the U.S. President's Council of Advisors on Science and Technology recently issued a report on Networking and IT R&D22identified Big Data as a "research frontier" that can "accelerate progress across a broad range of priorities." Even popular news media now appreciates the value of Big Data as evidenced by coverage in the Economist,7the New York Times,15,16 National Public Radio,19,20 and Forbes magazine.9
While the potential benefits of Big Data are real and significant, and some initial successes have already been achieved (such as the Sloan Digital Sky Survey), there remain many technical challenges that must be addressed to fully realize this potential. The sheer size of the data, of course, is a major challenge, and is the one most easily recognized. However, there are others. Industry analysis companies like to point out there are challenges not just in Volume, but also in Variety and Velocity,10 and that companies should not focus on just the first of these. Variety refers to heterogeneity of data types, representation, and semantic interpretation. Velocity denotes both the rate at which data arrive and the time frame in which they must be acted upon. While these three are important, this short list fails to include additional important requirements. Several additions have been proposed by various parties, such as Veracity. Other concerns, such as privacy and usability, still remain.
The analysis of Big Data is an iterative process, each with its own challenges, that involves many distinct phases as shown in Figure 2. Here, we consider the end-to-end Big Data life cycle.
Back to Top
Phases in the Big Data Life CycleMany people unfortunately focus just on the analysis/modeling step—while that step is crucial, it is of little use without the other phases of the data analysis pipeline. For example, we must approach the question of what data to record from the perspective that data is valuable, potentially in ways we cannot fully anticipate, and develop ways to derive value from data that is imperfectly and incompletely captured. Doing so raises the need to track provenance and to handle uncertainty and error. As another example, when the same information is represented in repetitive and overlapping fashion, it allows us to bring statistical techniques to bear on challenges such as data integration and entity/relationship extraction. This is likely to be a key to successfully leveraging data that is drawn from multiple sources (for example, related experiments reported by different labs, crowdsourced traffic information, data about a given domain such as entertainment, culled from different websites). These topics are crucial to success, and yet rarely mentioned in the same breath as Big Data. Even in the analysis phase, which has received much attention, there are poorly understood complexities in the context of multi-tenanted clusters where several users' programs run concurrently.

In the rest of this article, we begin by considering the five stages in the Big Data pipeline, along with challenges specific to each stage. We also present a case study (see sidebar) as an example of the issues that arise in the different stages. Here, we discuss the six crosscutting challenges.
Data acquisition. Big Data does not arise in a vacuum: it is a record of some underlying activity of interest. For example, consider our ability to sense and observe the world around us, from the heart rate of an elderly citizen, to the presence of toxins in the air we breathe, to logs of user-activity on a website or event-logs in a software system. Sensors, simulations and scientific experiments can produce large volumes of data today. For example, the planned square kilometer array telescope will produce up to one million terabytes of raw data per day.

Much of this data can be filtered and compressed by orders of magnitude without compromising our ability to reason about the underlying activity of interest. One challenge is to define these "on-line" filters in such a way they do not discard useful information, since the raw data is often too voluminous to even allow the option of storing it all. For example, the data collected by sensors most often are spatially and temporally correlated (such as traffic sensors on the same road segment). Suppose one sensor reading differs substantially from the rest. This is likely to be due to the sensor being faulty, but how can we be sure it is not of real significance?
Furthermore, loading of large datasets is often a challenge, especially when combined with on-line filtering and data reduction, and we need efficient incremental ingestion techniques. These might not be enough for many applications, and effective insitu processing has to be designed.
Information extraction and cleaning. Frequently, the information collected will not be in a format ready for analysis. For example, consider the collection of electronic health records in a hospital, comprised of transcribed dictations from several physicians, structured data from sensors and measurements (possibly with some associated uncertainty), image data such as X-rays, and videos from probes. We cannot leave the data in this form and still effectively analyze it. Rather, we require an information extraction process that pulls out the required information from the underlying sources and expresses it in a structured form suitable for analysis. Doing this correctly and completely is a continuing technical challenge. Such extraction is often highly application-dependent (for example, what you want to pull out of an MRI is very different from what you would pull out of a picture of the stars, or a surveillance photo). Productivity concerns require the emergence of declarative methods to precisely specify information extraction tasks, and then optimizing the execution of these tasks when processing new data.
Most data sources are notoriously unreliable: sensors can be faulty, humans may provide biased opinions, remote websites might be stale, and so on. Understanding and modeling these sources of error is a first step toward developing data cleaning techniques. Unfortunately, much of this is data source and application dependent.
Data integration, aggregation, and representation. Effective large-scale analysis often requires the collection of heterogeneous data from multiple sources. For example, obtaining the 360-degrees health view of a patient (or a population) benefits from integrating and analyzing the medical health record along with Internet-available environmental data and then even with readings from multiple types of meters (for example, glucose meters, heart meters, accelerometers, among others3). A set of data transformation and integration tools helps the data analyst to resolve heterogeneities in data structure and semantics. This heterogeneity resolution leads to integrated data that is uniformly interpretable within a community, as they fit its standardization schemes and analysis needs. However, the cost of full integration is often formidable and the analysis needs shift quickly, so recent "pay-as-you-go" integration techniques provide an attractive "relaxation," doing much of this work on the fly in support of ad hoc exploration.
It is notable that the massive availability of data on the Internet, coupled with integration and analysis tools that allow for the production of derived data, lead to yet another kind of data proliferation, which is not only a problem of data volume, but also a problem of tracking the provenance of such derived data (as we will discuss later).
Even for simpler analyses that depend on only one dataset, there usually are many alternative ways of storing the same information, with each alternative incorporating certain trade-offs. Witness, for instance, the tremendous variety in the structure of bioinformatics databases with information about substantially similar entities, such as genes. Database design is today an art, and is carefully executed in the enterprise context by highly paid professionals. We must enable other professionals, such as domain scientists, to create effective data stores, either through devising tools to assist them in the design process or through forgoing the design process completely and developing techniques so datasets can be used effectively in the absence of intelligent database design.
Modeling and analysis. Methods for querying and mining Big Data are fundamentally different from traditional statistical analysis on small samples. Big Data is often noisy, dynamic, heterogeneous, inter-related, and untrustworthy. Nevertheless, even noisy Big Data could be more valuable than tiny samples because general statistics obtained from frequent patterns and correlation analysis usually overpower individual fluctuations and often disclose more reliable hidden patterns and knowledge. In fact, with suitable statistical care, one can use approximate analyses to get good results without being overwhelmed by the volume.
Interpretation. Ultimately, a decision-maker, provided with the result of analysis, has to interpret these results. Usually, this involves examining all the assumptions made and retracing the analysis. Furthermore, there are many possible sources of error: computer systems can have bugs, models almost always have assumptions, and results can be based on erroneous data. For all of these reasons, no responsible user will cede authority to the computer system. Rather, she will try to understand, and verify, the results produced by the computer. The computer system must make it easy for her to do so. This is particularly a challenge with Big Data due to its complexity. There are often crucial assumptions behind the data recorded. Analytical pipelines can involve multiple steps, again with assumptions built in. The recent mortgage-related shock to the financial system dramatically underscored the need for such decision-maker diligence—rather than accept the stated solvency of a financial institution at face value, a decision-maker has to examine critically the many assumptions at multiple stages of analysis. In short, it is rarely enough to provide just the results. Rather, one must provide users with the ability both to interpret analytical results obtained and to repeat the analysis with different assumptions, parameters, or datasets to better support the human thought process and social circumstances.
While the potential benefits of Big Data are real and significant, and some initial successes have already been achieved, there remain many technical challenges that must be addressed to fully realize this potential.
The net result of interpretation is often the formulation of opinions that annotate the base data, essentially closing the pipeline. It is common that such opinions may conflict with each other or may be poorly substantiated by the underlying data. In such cases, communities need to engage in a conflict resolution "editorial" process (the Wikipedia community provides one example of such a process). A novel generation of data workspaces is needed where community participants can annotate base data with interpretation metadata, resolve their disagreements and clean up the dataset, while partially clean and partially consistent data may still be available for inspection.
Back to Top
Challenges in Big Data AnalysisHaving described the multiple phases in the Big Data analysis pipeline, we now turn to some common challenges that underlie many, and sometimes all, of these phases, due to the characteristics of Big Data. These are shown as six boxes in the lower part of Figure 2.
Heterogeneity. When humans consume information, a great deal of heterogeneity is comfortably tolerated. In fact, the nuance and richness of natural language can provide valuable depth. However, machine analysis algorithms expect homogeneous data, and are poor at understanding nuances. In consequence, data must be carefully structured as a first step in (or prior to) data analysis.
An associated challenge is to automatically generate the right metadata to describe the data recorded. For example, in scientific experiments, considerable detail regarding specific experimental conditions and procedures may be required in order to interpret the results correctly. Metadata acquisition systems can minimize the human burden in recording metadata. Recording information about the data at its birth is not useful unless this information can be interpreted and carried along through the data analysis pipeline. This is called data provenance. For example, a processing error at one step can render subsequent analysis useless; with suitable provenance, we can easily identify all subsequent processing that depends on this step. Therefore, we need data systems to carry the provenance of data and its metadata through data analysis pipelines.
Inconsistency and incompleteness. Big Data increasingly includes information provided by increasingly diverse sources, of varying reliability. Uncertainty, errors, and missing values are endemic, and must be managed. On the bright side, the volume and redundancy of Big Data can often be exploited to compensate for missing data, to crosscheck conflicting cases, to validate trustworthy relationships, to disclose inherent clusters, and to uncover hidden relationships and models.
Similar issues emerge in crowdsourcing. While most such errors will be detected and corrected by others in the crowd, we need technologies to facilitate this. As humans, we can look at reviews of a product, some of which are gushing and others negative, and come up with a summary assessment based on which we can decide whether to buy the product. We need computers to be able to do the equivalent. The issues of uncertainty and error become even more pronounced in a specific type of crowdsourcing called participatory-sensing. In this case, every person with a mobile phone can act as a multi-modal sensor collecting various types of data instantaneously (or example, picture, video, audio, location, time, speed, direction, acceleration). The extra challenge here is the inherent uncertainty of the data collection devices. The fact that collected data is probably spatially and temporally correlated can be exploited to better assess their correctness. When crowdsourced data is obtained for hire, such as with Mechanical Turks, the varying motivations of workers give rise to yet another error model.
Even after error correction has been applied, some incompleteness and some errors in data are likely to remain. This incompleteness and these errors must be managed during data analysis. Doing this correctly is a challenge. Recent work on managing and querying probabilistic and conflicting data suggests one way to make progress.
Scale. Of course, the first thing anyone thinks of with Big Data is its size. Managing large and rapidly increasing volumes of data has been a challenging issue for many decades. In the past, this challenge was mitigated by processors getting faster, following Moore's Law. But there is a fundamental shift under way now: data volume is increasing faster than CPU speeds and other compute resources.
Due to power constraints, clock speeds have largely stalled and processors are being built with increasing numbers of cores. In short, one has to deal with parallelism within a single node. Unfortunately, parallel data processing techniques that were applied in the past for processing data across nodes do not directly apply for intranode parallelism, since the architecture looks very different. For example, there are many more hardware resources such as processor caches and processor memory channels that are shared across cores in a single node.
Another dramatic shift under way is the move toward cloud computing, which now aggregates multiple disparate workloads with varying performance goals into very large clusters. This level of sharing of resources on expensive and large clusters stresses grid and cluster computing techniques from the past, and requires new ways of determining how to run and execute data processing jobs so we can meet the goals of each workload cost-effectively, and to deal with system failures, which occur more frequently as we operate on larger and larger systems.
This leads to a need for global optimization across multiple users' programs, even those doing complex machine learning tasks. Reliance on user-driven program optimizations is likely to lead to poor cluster utilization, since users are unaware of other users' programs, through virtualization. System-driven holistic optimization requires programs to be sufficiently transparent, for example, as in relational database systems, where declarative query languages are designed with this in mind. In fact, if users are to compose and build complex analytical pipelines over Big Data, it is essential they have appropriate high-level primitives to specify their needs.
In addition to the technical reasons for further developing declarative approaches to Big Data analysis, there is a strong business imperative as well. Organizations typically will outsource Big Data processing, or many aspects of it. Declarative specifications are required to enable meaningful and enforceable service level agreements, since the point of outsourcing is to specify precisely what task will be performed without going into details of how to do it.
Timeliness. As data grow in volume, we need real-time techniques to summarize and filter what is to be stored, since in many instances it is not economically viable to store the raw data. This gives rise to the acquisition rate challenge described earlier, and a timeliness challenge we describe next. For example, if a fraudulent credit card transaction is suspected, it should ideally be flagged before the transaction is completed—potentially preventing the transaction from taking place at all. Obviously, a full analysis of a user's purchase history is not likely to be feasible in real time. Rather, we need to develop partial results in advance so that a small amount of incremental computation with new data can be used to arrive at a quick determination. The fundamental challenge is to provide interactive response times to complex queries at scale over high-volume event streams.
Another common pattern is to find elements in a very large dataset that meet a specified criterion. In the course of data analysis, this sort of search is likely to occur repeatedly. Scanning the entire dataset to find suitable elements is obviously impractical. Rather, index structures are created in advance to find qualifying elements quickly. For example, consider a traffic management system with information regarding thousands of vehicles and local hot spots on roadways. The system may need to predict potential congestion points along a route chosen by a user, and suggest alternatives. Doing so requires evaluating multiple spatial proximity queries working with the trajectories of moving objects. We need to devise new index structures to support a wide variety of such criteria.
Privacy and data ownership. The privacy of data is another huge concern, and one that increases in the context of Big Data. For electronic health records, there are strict laws governing what data can be revealed in different contexts. For other data, regulations, particularly in the U.S., are less forceful. However, there is great public fear regarding the inappropriate use of personal data, particularly through linking of data from multiple sources. Managing privacy effectively is both a technical and a sociological problem, which must be addressed jointly from both perspectives to realize the promise of Big Data.
Consider, for example, data gleaned from location-based services, which require a user to share his/her location with the service provider. There are obvious privacy concerns, which are not addressed by hiding the user's identity alone without hiding her location. An attacker or a (potentially malicious) location-based server can infer the identity of the query source from its (subsequent) location information. For example, a user may leave "a trail of packet crumbs" that can be associated with a certain residence or office location, and thereby used to determine the user's identity. Several other types of surprisingly private information such as health issues (for example, presence in a cancer treatment center) or religious preferences (for example, presence in a church) can also be revealed by just observing anonymous users' movement and usage patterns over time. In general, it has been shown there is a close correlation between people's identities and their movement patterns.11 But with location-based services, the location of the user is needed for a successful data access or data collection, so doing this right is challenging.
Another issue is that many online services today require us to share private information (think of Facebook applications), but beyond record-level access control we do not understand what it means to share data, how the shared data can be linked, and how to give users fine-grained control over this sharing in an intuitive, but effective way. In addition, real data are not static but get larger and change over time; none of the prevailing techniques results in any useful content being released in this scenario.
Privacy is but one aspect of data ownership. In general, as the value of data is increasingly recognized, the value of the data owned by an organization becomes a central strategic consideration. Organizations are concerned with how to leverage this data, while retaining their unique data advantage, and questions such as how to share or sell data without losing control are becoming important. These questions are not unlike the Digital Rights Management (DRM) issues faced by the music industry as distribution shifted from sales of physical media such as CDs to digital purchases; we need effective and flexible Data DRM approaches.
The human perspective: Visualization and collaboration. For Big Data to fully reach its potential, we need to consider scale not just for the system but also from the perspective of humans. We have to make sure the end points—humans—can properly "absorb" the results of the analysis and not get lost in a sea of data. For example, ranking and recommendation algorithms can help identify the most interesting data for a user, taking into account his/her preferences. However, especially when these techniques are being used for scientific discovery and exploration, special care must be taken to not imprison end users in a "filter bubble"21 of only data similar to what they have already seen in the past—many interesting discoveries come from detecting and explaining outliers.
If users are to compose and build complex analytical pipelines over Big Data, it is essential they have appropriate high-level primitives to specify their needs.
In spite of the tremendous advances made in computational analysis, there remain many patterns that humans can easily detect but computer algorithms have a difficult time finding. For example, CAPTCHAs exploit precisely this fact to tell human Web users apart from computer programs. Ideally, analytics for Big Data will not be all computational—rather it will be designed explicitly to have a human in the loop. The new subfield of visual analytics is attempting to do this, at least with respect to the modeling and analysis phase in the pipeline. There is similar value to human input at all stages of the analysis pipeline.
In today's complex world, it often takes multiple experts from different domains to really understand what is going on. A Big Data analysis system must support input from multiple human experts, and shared exploration of results. These multiple experts may be separated in space and time when it is too expensive to assemble an entire team together in one room. The data system must accept this distributed expert input, and support their collaboration. Technically, this requires us to consider sharing more than raw datasets; we must also consider how to enable sharing algorithms and artifacts such as experimental results (for example, obtained by applying an algorithm with specific parameter values to a given snapshot of an evolving dataset).
Systems with a rich palette of visualizations, which can be quickly and declaratively created, become important in conveying to the users the results of the queries in ways that are best understood in the particular domain and are at the right level of detail. Whereas early business intelligence systems' users were content with tabular presentations, today's analysts need to pack and present results in powerful visualizations that assist interpretation, and support user collaboration. Furthermore, with a few clicks the user should be able to drill down into each piece of data she sees and understands its provenance. This is particularly important since there is a growing number of people who have data and wish to analyze it.

A popular new method of harnessing human ingenuity to solve problems is through crowdsourcing. Wikipedia, the online encyclopedia, is perhaps the best-known example of crowdsourced data. Social approaches to Big Data analysis hold great promise. As we make a broad range of data-centric artifacts sharable, we open the door to social mechanisms such as rating of artifacts, leader-boards (for example, transparent comparison of the effectiveness of several algorithms on the same datasets), and induced reputations of algorithms and experts.
Back to Top
ConclusionWe have entered an era of Big Data. Many sectors of our economy are now moving to a data-driven decision making model where the core business relies on analysis of large and diverse volumes of data that are continually being produced. This data-driven world has the potential to improve the efficiencies of enterprises and improve the quality of our lives. However, there are a number of challenges that must be addressed to allow us to exploit the full potential of Big Data. This article highlighted key technical challenges that must be addressed, and acknowledge there are other challenges, such as economic, social, and political, that are not covered in this article but must also be addressed. Not all of the technical challenges discussed here arise in all application scenarios. But many do. Also, the solutions to a challenge may not be the same in all situations. But again, there often are enough similarities to support cross-learning. As such, the broad range of challenges described here make good topics for research across many areas of computer science. We have collected some suggestions for further reading at http://db.cs.pitt.edu/bigdata/resources. These are a few dozen papers we have chosen on account of their coverage and importance, rather than a comprehensive bibliography, which would comprise thousands of papers.
Back to Top
AcknowledgmentThis article is based on a white paper5 authored by many prominent researchers, whose contributions we acknowledge. Thanks to Divyakant Agrawal, Philip Bernstein, Elisa Bertino, Susan Davidson, Umeshwar Dayal, Michael Franklin, Laura Haas, Alon Halevy, Sam Madden, Kenneth Ross, Dan Suciu, Shiv Vaithyanathan, and Jennifer Widom.
H.V.J. was funded in part by NSF grants IIS 1017296, IIS 1017149, and IIS 1250880. A.L. was funded in part by NSF IIS-0746696, NSFOIA-1028162, and NSF CBET-1250171. Y.P. was funded in part by NSF grants IIS-1117527, SHB-1237174, DC-0910820, and an Informatica research award. J.M.P. was funded in part by NSF grants III-0963993, IIS-1250886, IIS-1110948, CNS-1218432, and by gift donations from Google, Johnson Controls, Microsoft, Symantec, and Oracle. C.S. was funded in part by NSF grant IIS-1115153, a contract with LA Metro, and unrestricted cash gifts from Microsoft and Oracle.
Any opinions, findings, conclusions or recommendations expressed in this article are solely those of its authors.
Back to Top
References1. Computing Community Consortium. Advancing Discovery in Science and Engineering. Spring 2011.
2. Computing Community Consortium. Advancing Personalized Education. Spring 2011.
3. Computing Community Consortium. Smart Health and Wellbeing. Spring 2011.
4. Computing Community Consortium. A Sustainable Future. Summer 2011.
5. Computer Research Association. Challenges and Opportunities with Big Data. Community white paper available at http://cra.org/ccc/docs/init/bigdatawhitepaper.pdf
6. Dobbie, W. and Fryer, Jr. R.G. Getting Beneath the Veil of Effective Schools: Evidence from New York City. NBER Working Paper No. 17632. Issued Dec. 2011.
7. Economist. Drowning in numbers: Digital data will flood the planet—and help us understand it better. (Nov 18, 2011); http://www.economist.com/blogs/dailychart/2011/11/big-data-0
8. Flood, M., Jagadish, H.V., Kyle, A., Olken, F. and Raschid, L. Using data for systemic financial risk management. In Proc. 5th Biennial Conf. Innovative Data Systems Research (Jan. 2011).
9. Forbes. Data-driven: Improving business and society through data. (Feb. 10, 2012);http://www.forbes.com/special-report/data-driven.html
10. Gartner Group. Pattern-Based Strategy: Getting Value from Big Data. (July 2011 press release);http://www.gartner.com/it/page.jsp?id=1731916
11. González, M.C., Hidalgo, C.A. and Barabási, A-L. Understanding individual human mobility patterns.Nature 453, (June 5, 2008), 779–782.
12. Hey, T., Tansley, S. and Tolle, K., eds. The Fourth Paradigm: Data-Intensive Scientific Discovery. Microsoft Research, 2009.
13. Kahn, S.D. On the future of genomic data. Science 331, 6018 (Feb. 11, 2011), 728–729.
14. Lazar, D. et al. Computational social science. Science 323, 5915 (Feb. 6, 2009), 721–723.
15. Lohr, A. The age of Big Data. New York Times (Feb. 11, 2012);http://www.nytimes.com/2012/02/12/sunday-review/big-datas-impact-in-the-world.html
16. Lohr, S. How Big Data became so big. New York Times (Aug. 11, 2012);http://www.nytimes.com/2012/08/12/business/how-big-data-became-so-big-unboxed.html
17. Manyika, J. et al. Big Data: The next frontier for innovation, competition, and productivity. McKinsey Global Institute. May 2011.
18. National Science and Technology Council. Materials Genome Initiative for Global Competitiveness. June 2011.
19. Noguchi, Y. Following the Breadcrumbs to Big Data Gold. National Public Radio (Nov. 29, 2011);http://www.npr.org/2011/11/29/142521910/the-digital-breadcrumbs-that-lead-to-big-data
20. Noguchi, Y. The Search for Analysts to Make Sense of Big Data. National Public Radio, (Nov. 30, 2011);http://www.npr.org/2011/11/30/142893065/the-search-for-analysts-to-make-sense-of-big-data
21. Pariser, E. The Filter Bubble: What the Internet Is Hiding From You. Penguin Press, May 2011.
22. PCAST Report. Designing a Digital Future: Federally Funded Research and Development in Networking and Information Technology (Dec. 2010);http://www.whitehouse.gov/sites/default/files/microsites/ostp/pcast-nitrd-report-2010.pdf
23. SDSS-III: Massive Spectroscopic Surveys of the Distant Universe, the Milky Way Galaxy, and Extra-Solar Planetary Systems (Jan. 2008); http://www.sdss3.org/collaboration/description.pdf/
Back to Top
AuthorsH. V. Jagadish ([email protected]) is the Bernard A Galler Collegiate Professor of Electrical Engineering and Computer Science at the University of Michigan, Ann Arbor.
Johannes Gehrke ([email protected]) is the Tisch University Professor of the Department of Computer Sciences a Cornell University, Ithaca, NY.
Alexandros Labrinidis ([email protected]) is an associate professor in the Department of Computer Science at the University of Pittsburgh and co-director of the Advanced Data Management Technologies Laboratory.
Yannis Papakonstantinou ([email protected]) is a Professor of Computer Science and Engineering at the University of California, San Diego.
Jignesh M. Patel ([email protected]) is a professor of computer science at the University of Wisconsin, Madison.
Raghu Ramakrishnan ([email protected]) is a Technical Fellow and CTO of Information Services at Microsoft, Redmond, WA.
Cyrus Shahabi ([email protected]) is a professor of computer science and electrical engineering and the director of the Information Laboratory at the University of Southern California as well as director of the NSF's Integrated Media Systems Center.
Back to Top
Figures Figure 1. Next-gen sequence data size compared to SPECint.
Figure 1. Next-gen sequence data size compared to SPECint.
 Figure 2. The Big Data analysis pipeline. Major steps in the analysis of Big Data are shown in the top half of the figure. Note the possible feedback loops at all stages. The bottom half of the figure shows Big Data characteristics that make these steps challenging.
Figure 2. The Big Data analysis pipeline. Major steps in the analysis of Big Data are shown in the top half of the figure. Note the possible feedback loops at all stages. The bottom half of the figure shows Big Data characteristics that make these steps challenging.
Back to Top
Sidebar: Case StudySince fall 2010, as part of a contract with Los Angeles Metropolitan Transportation Authority (LA-Metro), researchers at the University of Southern California's (USC) Integrated Media Systems Center (IMSC) have been given access to high-resolution spatiotemporal transportation data from the LA County road network. This data arrives at 46 megabytes per minute and over 15 terabytes have been collected so far. IMSC researchers have developed an end-to-end system called TransDec (for Transportation Decision-making) to acquire, store, analyze and visualize these datasets (see the accompanying figure). Here, we discuss various components of TransDec corresponding to the Big Data flow depicted in Figure 2.
Acquisition: The current system acquires the following datasets in real time:
- Traffic loop-detectors: About 8,900 sensors located on the highways and arterial streets collect traffic parameters such as occupancy, volume, and speed at the rate of one reading/sensor/min.
- Bus and rail: Includes information from about 2,036 busses and 35 trains operating in 145 different routes in Los Angeles County. The sensor data contain geospatial location of each bus every two minutes, next-stop information relative to current location, and delay information relative to predefined timetables.
- Ramp meters and CMS: 1851 ramp meters regulate the flow of traffic entering into highways according to current traffic conditions, and 160 Changeable Message Signs (CMS) to give travelers information about road conditions such as delays, accidents, and roadwork zones. The update rate of each ramp meter and CMS sensor is 75 seconds.
- Event: Detailed free-text format information (for example, number of casualties, ambulance arrival time) about special events such as collisions, traffic hazards, and so on acquired from three different agencies.
Cleaning: Data-cleaning algorithms remove redundant XML headers, detect and remove redundant sensor readings, and so on in real time using Microsoft's StreamInsight, resulting in reducing the 46MB/minute input data to 25MB/minute. The result is then dumped as simple tables into the Microsoft Azure cloud platform.
Aggregation/Representation: Data are aggregated and indexed into a set of tables in Oracle 11g (indexed in space and time with an R-tree and B-tree). For example, the data are aggregated to create sketches for supporting a predefined set of spatial and temporal queries (for example, average hourly speed of a segment of north-bond I-110).
Analysis: Several machine-learning techniques are applied, to generate accurate traffic patterns/models for various road segments of LA County at different times of the day (for example, rush hour), different days of the week (for example, weekends) and different seasons. Historical accident data is used to classify new accidents to predict clearance time and the length of induced traffic backlog.
Interpretation: Many things can go wrong in a complex system, giving rise to bogus results. For example, the failures of various (independent) system components can go unnoticed, resulting in loss of data. Similarly, the data format was sometimes changed by one organization without informing a downstream organization, resulting in erroneous parsing. To address such problems, several monitoring scripts have been developed, along with mechanisms to obtain user confirmation and correction.
 TransDec.
TransDec.
2014 ACM 0001-0782/14/07
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and full citation on the first page. Copyright for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or fee. Request permission to publish from [email protected] or fax (212) 869-0481.
The Digital Library is published by the Association for Computing Machinery. Copyright 2014 ACM, Inc.
http://cacm.acm.org/magazines/2014/7/176204-big-data-and-its-technical-challenges/fulltext
作者: admin 时间: 2014-7-5 09:33
【案例】
五月 7, 2014 by 马金馨
数据新闻工作坊教学感想
由华媒基金会组织、IREX资助监督的“数据新闻工作坊”,是目前大陆唯一一个长期举办、面向全国跨领域招募的数据新闻培训。每一期培训招收来自全国的20名学员,包括记者、编辑、程序员、设计师等。每期会有特定的主题——第一期培训在广州举办,主题为财经;第二期培训在北京举办,主题为环境。
讲师有固定的两位——Jonathan Stray和我。Jonathan是美国人,程序员出身,在转行新闻前曾经写过七八年的代码。2010年去了美联社任Interactive Technology Editor,后来得到一笔资金开发了文本分析软件Overview,现在在哥伦比亚大学作访问学者,同时教授Computational Journalism。我则陆续从事过南华早报的社交媒体编辑、国际记者网的中文主编、路透社数据新闻产品助理等职,从2011年底开始做数据新闻和信息可视化方面的培训。
工作坊学员的组成非常多元,有来自21世纪经济报道、南方周末、东方早报、凤凰周刊等市场化媒体的记者编辑,有重庆晨报、新疆都市消费晨报、甘肃经济日报等地方媒体的采编人员,也不乏新华社、中国日报等官方背景的同行,亦有新浪、腾讯、凤凰网等门户的信息图编辑/产品经理,甚至有百度的工程师和传统媒体转型出来的创业者。在招募时会侧重不同背景的平衡,设计师、程序员、管理人员都很受青睐。两次入选学员的具体信息可以参见华媒基金会网站:第一期,第二期。
五天的工作坊采取脱产封闭式学习,课程紧凑,被学员戏称为地狱式培训。内容包括数据搜集与挖掘、数据清理与理解、基础统计学、基础HTML/ CSS/ JavaScript代码、设计原理、地图可视化等(以及针对程序员的D3应用和针对需要回机构分享的Train-the-Trainers)。授课形式除了传统讲课之外,结合了工具实操、学员分享、小组项目等。每天朝九晚五的课程之后,许多学员还继续为了小组项目连夜奋战——当然到最后一天,曾经一行代码都没写过的人可以在小伙伴们的协助下一起完成一个酷炫的动态新闻选题,成就感应该爆棚吧。当然亦有吃喝玩乐的环节,这里掠过不表。
 两期工作坊部分学员合影
两期工作坊部分学员合影
作为讲师,既和学员直接交流互动,又和两边的组织方接洽参与项目设计,有些感受颇深:
- 数据新闻在大陆的发展前景不可小觑。财新团队已经出产几个不错的数据新闻产品(例如诺贝尔可视化),南方都市报在尝试打破各团队的壁垒以理顺工作流程,各门户的原信息图栏目都在走交互方向(例如腾讯的外交发言人),央视的大数据栏目借助其雄厚的财力和背景在寻找各种可大手笔操作的选题,21世纪下有NID实验室出产数据产品(马航事件时的手机端尝试很受关注),东早的新媒体项目亦在紧锣密鼓的招募人才以备发展。我个人也知道几家尚未公开开始数据新闻尝试的机构也在打量和筹划。如果说2013年下半年是数据新闻在大陆媒体开始被认识和萌芽的阶段,那么2014年到2015年会是蓬勃发展、优胜劣汰的黄金时期。
- 大陆的数据新闻与欧美顶尖媒体的操作差距颇大,但是会走一条“中国特色”的道路。资金方面倒不是大问题——东早的“澎湃”APP前期投入就3个亿,这放到世界级媒体也令人咂舌。机构壁垒的问题也其实是个全球化的问题,记者编辑与程序员设计师沟通不畅也是放之全球皆准,否则就没有Hacks/Hackers之类的活动什么市场了。所谓中国特色,更多是在于选题的方向和工具的选择(很多国际化工具大陆用不了,你懂的),最重要的则是对创新的认可与对失败的接纳程度。
- 对于个人记者编辑来说,一个被问的最多的问题就是:要学到什么程度?第二多的问题就是:上哪儿去学?对第一个问题,如果无论是机构还是资源的原因,已经无法向全能型选手发展,那么就做一个什么都懂一些、但是有一技之长的人——至少,要懂得如何和程序员、设计师好好沟通与协作。对第二个问题,很多在线的学习资源很多,只是很多都是英文的。中文里氢请关注数据新闻网!或者就,报名参加下一期工作坊咯!
(数据新闻工作坊下一期将于七月下旬举办,报名信息请关注华媒基金会网站)
http://djchina.org/2014/05/07/data-journalism-workshop/
作者: admin 时间: 2014-7-8 23:54
【数据】
媒体人王晖军
//@央视小丸子:新闻与数据结合将是未来新闻变革的必经之路。
◆◆
@清华史安斌
美国网站推出的“数据新闻教学”系列文章,新闻学院教授分享开设数字新闻课程的经验。现在新闻系的学生再也不能说“我因为不愿意上数学课才来学新闻”,同样道理,“如果大数据或全数据不能变成具有公共性的新闻和应用性的资讯,那么就成了坏数据”,新闻与数据的结合势在必行http://t.cn/RveBaki
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
作者: admin 时间: 2014-7-12 10:12
【案例】
祝建华:数据新闻的前世今生
2014年07月10日19:21 新浪传媒
祝建华:数据新闻的前世今生
2014第五届中国传媒领袖大讲堂于7月5日至19日在上海交通大学举办。本届大讲堂邀请50多位传媒领军人物,一线编辑、记者、主持人和著名专家学者,为来自海内外160余所高校的350余名学子讲授传媒业改革创新的经验与教训,帮助学子们了解传媒业界和学界的最新发展动态,深化对传媒业和新闻传播学科的认识。以下为香港城市大学媒体与传播学系教授祝建华7月7日上午在第五届中国传媒领袖大讲堂上的演讲。
近几年内地逐渐兴起了对大数据的讨论,大数据以及数据新闻成为了传媒学界关注的热点。对此,祝建华采用了对比讨论、图标展示、举例说明等形式鲜明直观地向学员们介绍了大数据以及数据新闻的相关知识。
随着时代的进步,传统的数据统计来源如政府的统计机构、经济金融、天文地理、传统媒体、交通运输等已经落后,而与之相对应的新型数据来源正日益丰富,如互联网、移动网、智能家居、物联网、生物工程等,造成数据量呈现出几何增长的态势。
为使学员们能够能好的体会到数据统计方式的变迁,祝建华向同学们讲述了自己早年在上海工作时以日记卡记录的形式对电视的收视率进行统计的经历。同时还与学员们共同分享了利用大数据进行现实预测的故事,例如百度大数据对语文高考题的预测和眼下的世界杯结果预测等,帮助同学更好地理解大数据的价值。
在详细讲述了大数据的相关知识后,祝建华又利用图示向学员们展示了数据新闻的演化路径。从精确新闻的出现,到电脑辅助新闻的兴起,发展到数据库新闻以及数据驱动新闻,直至目前的可视化新闻。对数据新闻的这一演化路径,祝建华特别强调,演化的过程并不是替代而是一种增量关系,数据新闻早于互联网和大数据。同时,祝建华还对精确新闻与电脑辅助报道进行了精确的对比分析,并对可视化新闻进行了四大分类说明,即可视化作为新闻主体、可视化作为新闻主题、可视化作为新闻导语、可视化作为新闻插图等。(王欣)
http://news.sina.com.cn/m/news/roll/2014-07-10/192130501044.shtml
作者: admin 时间: 2014-7-19 10:03
【案例】
数据化管理
【Excel如何隐藏数据】不会隐藏数据的人就不会用Excel建模。用Excel建模一定要学会隐藏数据。需要隐藏的包括不方便给使用者看的数据,数据源区域的数据,辅助计算过程中的数据,计算逻辑,影响模板美观的数据等... #数据化管理:洞悉零售及电子商务运营# http://t.cn/RPwkSds
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(11)[/url]| [url=]轉發(17)[/url]| [url=]收藏[/url]| [url=]評論(3)[/url]
23分鐘前 來自分享按钮
作者: admin 时间: 2014-7-20 10:41
【案例】
刘洪的围脖
观厕所见文明,从便溺知发展!
◆◆
@喻国明
全世界在野地里拉屎的人口密集度。大数据研究的又一应用实例。
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(5)[/url]| 轉發(14) | 評論(5)
5分鐘前來自iPhone 5s
[url=]
[/url]| [url=]轉發[/url]| [url=]收藏[/url]| [url=]評論[/url]
2分鐘前 來自iPad客户端
作者: admin 时间: 2014-8-14 17:16
【案例】
传媒老王
漂亮的内衣是女人的一份秘密,可这个“里子”里的秘密在大数据时代被揭开了一丝神秘面纱。昨天,时隔三年,淘宝文胸数据报告再度来袭,对比2014年6月14日~7月13日与2011年同期数据,淘宝数据透露,三年里,尽管B罩杯仍是女性的主流胸围,但A罩杯少了,C罩杯多了。
[url=](38)[/url]
[url=](15)[/url]| [url=]轉發(67)[/url]| [url=]取消收藏[/url]| [url=]評論(28)[/url]
8月9日11 : 08來自微博 weibo.com
作者: admin 时间: 2014-8-18 15:50
【案例】
朴抱一
高级黑啊。深圳新闻网报道说:本周末福田、深圳湾口岸不仅再现旅客爆棚,而且刷新各自单日客流最高纪录,深圳湾口岸达到14.5万人次,而福田口岸则飙升至18.9万人次,导致其不得不推迟到晚上11时关闸。。这些人参加“爱国爱港”的“反占中”游行了吗?
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(2)[/url]| [url=]轉發(3)[/url]| [url=]收藏[/url]| [url=]評論(1)[/url]
6分鐘前 來自微博 weibo.com
作者: admin 时间: 2014-8-22 21:11
本帖最后由 admin 于 2014-8-22 21:14 编辑
【案例】如何用数据讲故事?
2014-08-22 王晓枫 新京报传媒研究
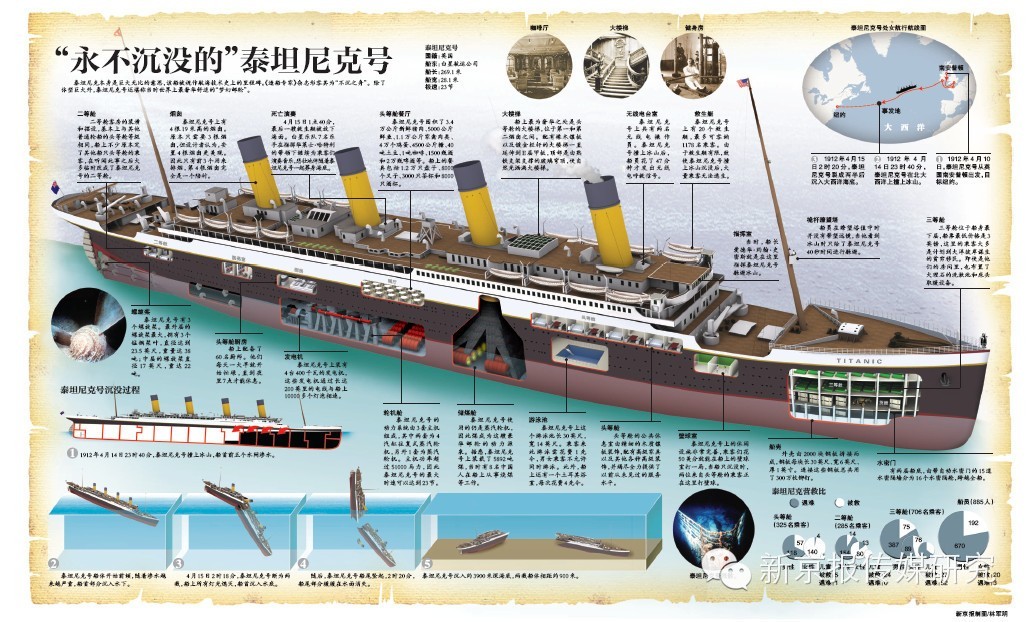
编者按:
如何用数据讲一个好故事?
王晓枫认为,一名优秀的数据新问采编人员,首先应该具备传统新闻的素养,要有一定的新闻敏感。同时,还要擅于数据的分析与梳理,并知道如何结合有价值的数据来编织出一个读者爱看的好故事。
朋友们好,今天我们为大家推送的第一篇文章,来自于新京报国际新闻编辑王晓枫,相信通过这篇文章,我们或许能够找到一些操作数据新闻的方法。
什么是数据新闻,这是一个新的概念吗?数据新闻(Data-driven journalism)并不是新概念。事实上,英国《卫报》的首个数据新闻报道可以追溯到1821年,如今这份数据图表可以从《卫报》的网站上下载。
简单来说,数据新闻就是利用真实有效的数据辅证和讲述新闻故事,越来越多中国媒体开始涉足数据新闻,特别是长微博制图广受受众欢迎,计算机技术使网络形式的数据新闻总是能在形式上比传统媒体占据优势。在这种情况下,传统媒体如何发挥自己在数据新闻上的优势呢?
针对数据新闻的形式,《新京报》开辟了《新图纸》栏目,意在通过整版数据制图向读者讲述一个新闻故事。虽然数据新闻被认为是带有新媒体色彩的新闻,但如何做好一个数据新闻,依然少不了传统新闻素养,即要把传统的新闻敏感、讲故事的能力和精编的数据结合起来。

什么是数据新闻中的新闻敏感?
虽然数据逐渐在新闻报道中发挥越来越重要的作用,但不能因此被数据奴役,一味根据数据来制作新闻。一个好的数据新闻最重要的还是要有新闻卖点,纵观国内外优秀数据新闻制图无不要依托重大新闻事件,这样才能吸引读者阅读的兴趣,脱离了新闻性,再好的数据制图也只能是一份研究报告。正如《卫报》数据新闻编辑Simon Rogers所说:
“数据新闻不是图形或可视化效果,而是用最好的方式去讲述故事,只是有时故事是用可视化效果或地图来讲述。”
在依托新闻事实的基础上,好的数据新闻当然需要数据本身的支持。在数据新闻的制作过程中,虽然最吸引眼球的是可视化效果,但核心工作却是收集数据、分析数据。伯明翰城市大学教授保罗·布拉德肖用倒金字塔来表示数据新闻制作过程,包括数据汇编(compile)、数据清理(clean)、了解数据(context)和数据整合(combine)等四个部分。数据处理的最终目的是为了完成数据的可视化并实现有效传播。
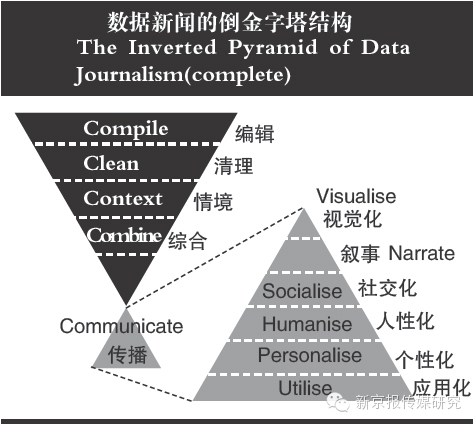
在这个环节中,不仅是内容编辑要提供精编数据,也同样要求制图美编充分读懂数据。国外媒体专门设置了数据新闻记者,这个角色既要拥有数据分析能力,也又要具有新闻采访能力和制图技能。
近年来,在国外主流媒体中涌现出一批知名数据新闻记者,许多重大新闻事件中的精良的制图均是出自他们之手,例如,《卫报》的Simon Rogers、纽约时报的Amanda Cox,以及我本人最推崇的意大利创意制图师Francesco Franchi。作为一种发展趋势,中国媒体也将逐步设置数据新闻记者,这对数字新闻制作者提出了更高的要求,即要拥有多方面技能——新闻、统计、计算机。
如何搜集整理数据?
确定主题后,数据新闻最重要的当属搜集数据,一份好的数据资料必须具备准确、翔实、易读等特点。《卫报》数据新闻编辑、数据博客负责人Simon Rogers在《数据新闻分解步骤:在你见到的数据背后我们都做了什么》一文中这样描述数据搜集的过程,一方面处理数据,另一方面不断检验、质询数据的可信度与价值,最后通过多种手段与渠道发布完成的报道。
搜集数据的第一个要点是从多渠道获得数据,海量数据是数据新闻报道的基础。可以从以下渠道获取资料,这一方面包括由媒体自行调查或抓取的一手数据,一些国外大型媒体拥有数据分析团队,因此可获得比较独家数据。除了一手数据,二手数据也是一个宝库,许多数据新闻报道的数据来源都是公开的,可从政府、企业、研究机构等数据库中获取,例如,中国国家统计局网站、知名调查机构等。美国著名咨询机构皮尤公司人员曾对笔者表示,该公司网站提供的数据能让你比一般研究人员掌握更专业数据。

在得到数据后,如何处理浩如烟海的原始数据?未经处理的数据,一方面由于繁杂量大很难被读者消化,另一方面由于原始数据复杂凌乱,读者很难从中发现问题。将这些枯燥杂乱的数据整理为简明易懂的、可为新闻故事服务的数据,这是数据新闻整理过程中,最耗时耗力的工作。
其他信源一样,在处理数据时也要不忘验证,要保持怀疑精神,要核查数据来源是否可靠、时效性如何等问题。 2011年度普利策调查性报道奖得主佩奇·约翰强调,所有的数据必须有来源,并经过交叉验证。
由于现在越来越多的数据新闻产品上线,如何在同类产品中展露头角,就需要高质量的数据作保障,因此数据新闻制作者要学会使用数据分析软件,以便更好地理解数据背后的含义,让数据新闻更具针对性和独家性。
数据新闻可视化如何操作?
在得到高质量的数据后,数据新闻将如何使没有生命、枯燥的数据变得艺术化起来,那就需要生动活泼的图形来实现可读性。《数据新闻手册》一书中指出,将人们能见到表象化东西之外的数据搜集、筛选、生成可视化的图表,是一件被认为是越来越有价值的工作。
在众多花哨和复杂的数据制图中如何才能更胜一筹,《新图纸》在过去一年中经历了重大变革,由最初追求制图复杂转变为去繁求简,这个过程并不意味着制图质量下降,而是制作更纯粹的数据新闻,对数据和制图表现形式的要求更高。一个好的数据新闻作品在形式上应该避免以下四点误区:
第一,过于注重形式而忽略内容,切勿用过多图画让新闻作品变成“幼儿园作品”。目前很多制图作品风格卡通化,追求画面花哨,但却忽视了要传达的数据信息本身,数据新闻的本质仍是数据和新闻事实,制图形式只是载体,不能舍本逐末。“图表垃圾”和多余的设计元素可能会给制图效果带来负面影响。
第二,不追求过分花哨,也并不意味着要没有创意地简单化制图。哈佛大学工程与应用科学学院博士生Michelle Borkin对可视化制图进行研究,他发现简单的条形图和饼状图很难被受众记住,“所有条形图看起来都一样。每一张条形图设计都相似,而在布局和结构上变化更丰富的制图更容易让人们记住。”
第三,在制作数据新闻过程中,很容易会犯面面俱到的错误,制图者试图为读者传达事无巨细的信息,因此在整张制图中安排过多信息,造成没有视觉中心点,使读者产生阅读疲劳。网络长微薄由于从上到下的阅读顺序和数据排列方式一般不存在这个问题,容易存在这个问题的是通过整版报纸展现的制图,《新图纸》在制作过程中逐渐避免这个问题,力求简洁明快突出最重要信息。
第四,制图在追求标新利益的同时会衍生出一个问题就是过于复杂,虽然新颖的设计形式给读者留下深刻的印象,但如果无法让人理解,就难以达到令人满意的效果。笔者在英国留学时,导师是这样定义硕士论文的,即让毫不了解这个话题的人可无障碍读懂,而并非充斥无法理解的学术语言。同样对于数据新闻来说,让读者看一遍就能理解这个新闻事件才是最重要的目的。
鉴于以上四点误区,在绘制数据新闻时应该秉持以下要点,首先,要让读者在阅读数据新闻时,眼睛去理解,但是大脑去休息,每一个优秀的数据新闻都应该直接和读者的眼睛对话,一目了然是核心追求。
其次,要简化再简化,不要试图将全部信息集中在一个表格中了,比这更重要的是,让读者一眼看透图片传递的信息。
最后,在选择制图形式上,还要具体问题具体分析,要根据题材和读者选择风格,设计风格决定了会吸引哪一类读者,应该指向明确。例如,财经类数据新闻目标受众多是有专业背景人士,因此,设计风格不妨简洁商务;如果是政策解读或社会类新闻制图,目标受众多是普通读者,设计不妨活泼诱人。
尽管数据新闻往往借助新媒体技术来制作与呈现,但这并不意味着传统平面媒体对此无所作为,《新京报》非常注重传统媒体与新技术的结合,成功实现数据新闻在网络与报纸两个平台间的转化。在这个过程中新闻编辑和美编要解决这样的难题,即如何发挥出平面媒体的优势与特点,扬长避短地让数据新闻在平面上活起来。另一方面,在制作数据新闻时,网络也可吸收平面媒体优势,例如在制作地图类数据新闻时,可选择手绘形式,会给人耳目一新的感觉。
数据新闻报道是一个综合、系统的过程,它需要新的思维方式与多种能力的支撑,处理数据和设计、制作、发布信息图表的能力对于新闻从业者的挑战尤为明显。
http://mp.weixin.qq.com/s?__biz=MzA3Mzg3MDczOA==&mid=200389474&idx=1&sn=f32e58599279ba6710c8ea9f5b81d91b&key=b67e4e539844e2e5e23b0578152d321f79550a98133389cbf9055ae73aeef66d8d9bc05600b02c5b0a92c20d874d9b87&ascene=7&uin=Mjk2NDAyMjQyMw%3D%3D&pass_ticket=4jRkIchQnPTlSyhLZ%2BdorjAQ8jUGktTO87JAwkDDEx8nTKe1enodf8eFoD4YFjXc
作者: admin 时间: 2014-8-23 11:08
【案例】数据化管理
有意思的故事,数据分析只是手段,回归业务场景是必须,如果还能产生价值就更牛了。
◆◆
@互联网分析沙龙
如何成为一个牛逼的数据分析师?http://t.cn/RP1y498
[url=]
收起[/url]|[url=]
查看大圖[/url]|[url=]
向左轉[/url]|[url=]
向右轉[/url]
[url=]
(15)[/url]| 轉發(70) | 評論
27分鐘前來自互联网分析沙龙
[url=]
(13)[/url]| [url=]轉發(27)[/url]| [url=]收藏[/url]| [url=]評論(4)[/url]
22分鐘前 來自iPhone 5s | [url=]檢舉[/url]
作者: admin 时间: 2014-8-30 08:28
【案例】
全球油价排行:中国位列中下游 委内瑞拉几乎免费2014-08-29 18:32:33 来源: 东方早报(上海) 有38214人参与
分享到
和世界其他国家地区相比,中国的油价是高还是低?
8月27日,中石化官方微博“石化实说”发布了来自全球汽油价格网的数据(globalpetrolprices.com),结论是中国油价在全球处于中等水平。
中石化是中国最大的炼油企业,其经常因为油价上涨问题而被诟病。事实上,中国油价的定价权并不在企业手中,油价的涨跌掌握在发改委手中,目前,由一套复杂的定价公式加以调控。
8月25日,在全球汽油价格网统计的161个国家中,中国以8.11元/升排在全球油价第83位。美国的油价为5.96元/升。
挪威以15.67元/升的价格,成为全球油价最高国家。
而委内瑞拉的平均油价仅为0.06元/升,全球最低。在委内瑞拉,政府甚至会补贴汽油价格,因此委内瑞拉的人民,只要买的起车,油价根本不在考虑范围内。

注:加*国家的数据来自官方最新汽油价格数据;没有*国家则用旧的数据为基准。汇率参照8月27日美元兑人民币汇率,以8月25日国际石油价格计算。
据该网站计算,全球8月汽油平均价格1.31美元/升,折合8.04元人民币/升。通常来说,富裕国家的油价高,贫穷国家的油价低;石油净出口国家的油价低。但有个明显的例外,美国是一个经济发展水平高的国家,同时也是石油净进口国,但它的油价却很低。
出现这样的“奇观”,一个主要原因是,美国税收在汽油价格中占比仅为11%;相形之下,英国、德国占比为58%,韩国则占49%。
中国从2009年起,取消了公路养路费等6项收费,但汽油价格中的税收占比仍然高达三成,包括增值税、消费税(燃油税)、城建税等费用。若减去政府对汽油、柴油所征收的税费,中国的油价与美国大致相同。
这里提一句,在石油净进口国中,中国油价排在美国之后,是全球第二低的国家。
最后,再普及一点,许多国家对柴油和汽油征收不同的税收。例如,在美国,联邦政府对汽油征收18.4美分/加仑(1加仑约为3.78升)消费税,柴油征收24.4美分/加仑的消费税。相反,大多数的欧洲国家,对柴油征收的消费税低于汽油。
http://money.163.com/14/0829/18/A4R9I5L6002524SO.html
作者: admin 时间: 2014-9-1 18:19
【案例】@财经网
【2014年中纪委抢了42次头条】29日,白云、白恩培、任润厚这3名省部级官员被查,加上23日落马两名山西部级官员,一周内,5名省部级官员上了腐败清单。今年以来,在中纪委公布的腐败官员中,有42人被媒体高度关注 ,其中七八两月达到了22人,突显中央反腐力度持续加强。@法制晚报 http://t.cn/RhZrjEJ
[url=](137)[/url]
[url=](134)[/url]| 轉發(119) | 評論(84)
8月30日19 : 18來自微博 weibo.com
作者: admin 时间: 2014-9-12 21:06
【案例】
沈浩老师
回复@小仙滴嗨皮尼斯:纯文科不知有多纯(蠢) ,至少研究和传播大数据时代应没问题。困难在于大数据挖掘和分析技术有障碍,一旦突破就更牛,高智商的技能人往往为低智商高智慧的人打工!顺便说:俺培养的都是文科生,部分在大数据挖掘很有心得,很多在技术上比老师都牛ǜ
,至少研究和传播大数据时代应没问题。困难在于大数据挖掘和分析技术有障碍,一旦突破就更牛,高智商的技能人往往为低智商高智慧的人打工!顺便说:俺培养的都是文科生,部分在大数据挖掘很有心得,很多在技术上比老师都牛ǜ
◆◆
@广院时光
中国传媒大学2014级本科新生军训纪实(二)
[url=](5)[/url]| 轉發(26) | 評論(6)
今天 19:07來自微博 weibo.com
| [url=]轉發[/url]| [url=]收藏[/url]| [url=]評論[/url]
4分鐘前 來自iPad客户端 | [url=]檢舉[/url]

还有3条对原微博的转发

沈浩老师:
回复@dede-de-悦莹:没有 //@dede-de-悦莹:请问老师,研究生入学有没有军训呀? //@沈浩老师:
//@沈浩老师: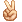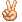 //@田维义:转发微博
//@田维义:转发微博
◆◆
@广院时光 中国传媒大学2014级本科新生军训纪实(二)
[url=](1)[/url]| [url=]轉發(1)[/url]| [url=]收藏[/url]| [url=]評論(2)[/url]
19分鐘前 來自iPad客户端 | [url=]檢舉[/url]
沈浩老师:
//@田维义:转发微博
◆◆
@广院时光 中国传媒大学2014级本科新生军训纪实(二)
[url=](4)[/url]| [url=]轉發(3)[/url]| [url=]收藏[/url]| [url=]評論(4)[/url]
38分鐘前 來自iPhone 5s | [url=]檢舉[/url]

田维义:
转发微博
◆◆
@广院时光 中国传媒大学2014级本科新生军训纪实(二)
[url=](4)[/url]| [url=]轉發(9)[/url]| [url=]收藏[/url]| [url=]評論(1)[/url]
40分鐘前 來自iPad客户端 | [url=]檢舉[/url]
作者: admin 时间: 2014-9-14 09:40
【案例】
调查称网络新闻从业者月平均收入约四千元
2014年09月13日23:28 人民网 我有话说
人民网广州9月13日电(杨杰利 蔡珊珊 实习生陈颜梅) 13日下午,《中国新闻业年度观察报告2014》首发仪式在广州中山大学举行。该研究报告显示,受访的网络新闻从业者月平均收入约4000元,仅4.6%的从业者月收入在10001元以上;全国网络新闻从业者以女性为主,并呈现出非常明显的年轻化、高学历特征。
据了解,《中国新闻业年度观察报2014》是由中山大学传播与设计学院主办,人民日报出版社出版。其中,复旦大学周葆华副教授等发表的《中国网络新闻从业者生存状况调查报告》,对 60家网站的1631位网络新闻从业者进行在线问卷调查,于2013年11-12月间进行。
调查发现,全国网络新闻从业者以女性为主,比例达到59.5%,男性为40.5%,并呈现出非常明显的年轻化、高学历特征,平均年龄为29.1岁,95.1%以上拥有本科以上学历,近四成接受过专业的新闻传播教育,但六成多来自其他专业。
在收入方面,全国网络新闻从业者月总收入平均水平在4000元左右,其中36.1%的网络新闻从业者月收入为2001~4000元,32.7%为4001~6000元,22.5%为6001~10000元,另外有4.6%的从业者月收入在10001元以上,4.2%的从业者月薪不足2000元。
此外,报告显示,网络新闻工作者对目前工作的满意度处于百分制的65分水平,最满意的是人际关系,对“工作报酬收入”和“福利待遇”的满意度较低,愿意将网络新闻工作作为终身职业的人只占少数,大多数人考虑在5年之后离开,或是处于待定状态。
报告中还列举了中山大学传播与设计学院院长张志安教授所著《新媒体环境下中国新闻从业者生态调查报告》,通过对对全国5家报业集团(报社) 2109个有效样本的问卷调查,发现,从业者整体年龄结构较轻,平均年龄32岁,约76%的人年龄在35岁以下;男女比例持平,分别为48.5%和51.5%,但与1997年的一项全国新闻工作者调查比较来看,女性新闻从业者比例明显提高,原因可能是近年来在新闻院校就读的女生人数迅速增加,比例明显高于男性。另一方面,报业受到数字化冲击后面临生存压力和危机,而男性对自我实现的追求尤其是物质回报的要求更高,也导致了男性从新闻行业的流失。
(原标题:调查称网络新闻从业者月平均收入约四千元)
http://news.sina.com.cn/c/2014-09-13/232830847562.shtml
作者: admin 时间: 2014-9-28 17:32
【案例】
何镇飚
数据大了,公民权利不能小了 //@肖珺CHINA: //@政见CNPolitics:美国civilrights网站提出了大数据时代下的公民权利五项原则,包括停止高科技监控、增强个人信息控制等,得到了美国众多机构的签名支持。 http://t.cn/RhRitpB
◆◆
@政见CNPolitics
#政见观点#【大数据时代下的公民权利】随着日常生活中的重要决定开始越来越多地取决于电脑数据,关于公民权利的讨论也开始演变为对电脑系统的讨论。《公民权利、大数据与算法的未来》报告集中讨论了大数据与公民权利交集的问题,包括金融、司法审判以及政府数据的收集与使用等。 http://t.cn/Rh82w45
[url=]收起[/url]|[url=]查看大圖[/url]|[url=]向左轉[/url]|[url=]向右轉[/url]
[url=](9)[/url]
[url=](5)[/url]| 轉發(33) | 評論(3)
9月27日20 : 00來自皮皮时光机
| [url=]轉發(3)[/url]| [url=]收藏[/url]| [url=]評論(1)[/url]
26分鐘前 來自iPhone客户端 | [url=]檢舉[/url]

还有1条对原微博的转发

肖珺CHINA:
//@政见CNPolitics:美国civilrights网站提出了大数据时代下的公民权利五项原则,包括停止高科技监控、增强个人信息控制等,得到了美国众多机构的签名支持。 http://t.cn/RhRitpB
◆◆
| [url=]轉發(4)[/url]| [url=]收藏[/url]| [url=]評論[/url]
33分鐘前 來自iPhone客户端 | [url=]檢舉[/url]
作者: admin 时间: 2014-10-11 15:42
【案例】
十月 8, 2014 by 袁竞逐
ONA年度新闻奖项评选结果揭晓:ProPublica成最大赢家
芝加哥当地时间9月27日,2014年网络新闻年会圆满结束。会议评选出了年度网络新闻各奖项,ProPublica一举夺得33个奖项中的5项,成为本次评选最大的赢家。此外,明年起大会新增一个奖项——『詹姆斯·弗雷(James Foley)』新闻奖。该奖项以八月份在叙利亚被杀的环球邮报自由撰稿人詹姆斯·弗雷命名,用以奖励那些在冲突地带报道的记者。
除了卓越『网络新闻(中型)』奖项之外,ProPublica还囊括了『解释性报道(中型)』『特稿(中型)』『专题报道(中型)』『纽哈斯调查报道创新奖(中型)』四个奖项。表现同样抢眼的还有NPR的《Planet Money:一件T恤背后的故事》。该报道以一件T-shirt的制作过程为切入点,用视频、文字、图片、信息图表等方式,展现了背后关联的整个世界,令人感叹原来一件普普通通的T-shirt也大有来头。此文不仅斩获『特稿(大型)』奖,也将『创新视觉报道(大型)』奖揽入怀中。
『佛罗里达大学调查数据新闻奖』是去年新成立的奖项,该奖项颁发给了Milwaukee Journal Sentinel的有关新生儿健康检查的报道和MPR News关于天主教牧师被起诉性侵的报道。
『突发新闻』奖项颁发给了卡尔加里先驱报的《亚伯达水灾》和西雅图时报的《奥斯陆山体滑坡》。奈特公共服务奖的3000美金奖金被迈阿密先驱报的福罗里达儿童虐待调查报告获得,而加内特基金会数字新闻创新科技奖提供的5000美金则花落西北大学奈特实验室研发的Publishers’ Toolbox。其他获奖情况详见获奖名单。
2014网络新闻奖获奖名单
奈特公共服务奖
《无辜丧命》,迈阿密先驱报
卓越网络新闻奖(小型)
publicintegrity.org,公共廉政中心
卓越网络新闻奖(中型)
propublica.org,ProPublica
卓越网络新闻奖(大型)
latimes.com,洛杉矶时报
加内特基金会数字新闻创新科技奖
Publishers’ Toolbox,西北大学奈特实验室(Knight Lab)
突发新闻(小型)
无
突发新闻(中型)
《亚伯达水灾》,卡尔加里先驱报
突发新闻(大型)
《奥斯陆山体滑坡》,西雅图时报
常规新闻/事件报道(小型)
《31天,31种改变》,德克萨斯论坛报
常规新闻/事件报道(中型)
《纽顿枪击:一年之后》,琼斯母亲(Mother Jones)
常规新闻/事件报道(大型)
《2013年国际象棋锦标赛》,VG
解释性报道(小型)
《重建海地》,The Pixel Hunt,欧洲新闻中心,89街(Rue89)
解释性报道(中型)
解释性报道(大型)
《海洋的变化:大西洋的危险转变》,西雅图时报
专题报道(小型)
《德州堕胎辩论》,德克萨斯论坛报
专题报道(中型)
医疗保险专题报道,ProPublica
专题报道(大型)
《支付,直到伤害》,纽约时报
网络评论(小型)
Susie Cagle在Medium的插画评论,Susie Cagle
网络评论(中型)
Sarah Lazarovic,麦克林
网络评论(大型)
Code switch,美国国家公共电台
特稿(小型)
《好生活:那些改变了缅因的运动》, BDN Maine
特稿(中型)
《种族隔离现状》,ProPublica
特稿(大型)
《货币星球:一件T恤背后的故事》,NPR
学生项目(小型)
学生项目(大型)
《News 21:回家》,Carnegie-Knight News21,亚利桑那州立大学沃尔特·克朗凯特新闻与大众传播学院
艾伦纽哈斯调查报道创新奖(小型)
无
艾伦纽哈斯调查报道创新奖(中型)
《药物过量》,ProPublica
艾伦纽哈斯调查报道创新奖(大型)
《逃亡者》,今日美国/ Gannett Digital
杰出创新视觉与数字辅助报道(小型)
《空》,Hollow Interactive
杰出创新视觉与数字辅助报道(中型)
《薄冰:探索胡德山的秘密世界》,俄勒冈公共广播电台
杰出创新视觉与数字辅助报道(大型)并列
佛罗里达大学调查数据新闻奖(小/中型)
《被沉默出卖》,MPR News
佛罗里达大学调查数据新闻奖(大型)
《致命的延迟》,Milwaukee Journal Sentinel
http://djchina.org/2014/10/08/2014oja/
作者: 刘海明 时间: 2014-11-3 08:45
【案例】
中国实际吸毒人员或超1300万 10月份查5.5万余人2014-11-03 00:22:38 来源: 新华网

新华网北京11月2日电 记者2日从公安部获悉,公安部于9月底动员部署全国公安机关开展为期半年的百城禁毒会战,10月1日至29日,全国破获毒品犯罪案件10427起,缴获各类毒品9.14吨,查处吸毒人员55981人次。
公安部部长助理、禁毒局局长刘跃进指出,当前我国毒情形势处于毒品问题加速蔓延期、毒品犯罪多发高发期、毒品治理集中攻坚期。目前,全国登记吸毒人员276万名,按国际惯例估算实际吸毒人员超过1300万,每年消耗的毒品总量近400吨,因毒品而消耗的社会财富超过5000亿元。今年以来,仅福建、广东等14个省份就报告因“毒驾”肇事造成群死群伤,因吸毒致幻当街砍杀路人、冲入学校砍杀学生、杀戮亲友、自杀自残,为筹措毒资流窜多省行窃、多次入室抢劫等重大恶性案件104起。
刘跃进表示,毒品问题严重危害社会治安稳定,严重影响经济发展,严重影响人民群众安全感,严重制约平安中国、法治中国的建设进程。为回应人民群众的呼声,公安部动员部署全国公安机关开展了此次百城禁毒会战。
据介绍,从10月1日至10月29日,全国共抓获毒品犯罪嫌疑人12991名,缴获各类毒品9.14吨,查处吸毒人员55981人次,同比分别上升8.03%、63.72%和52.45%。共破获部级毒品目标案件52起,省级毒品目标案件89起,查封关停严重涉毒娱乐场所43个,抓获涉毒嫌犯364名,缴获各类枪支91支、子弹1236发。
在对制毒犯罪的打击战役中,共破获制毒案件及制毒原料犯罪案件69起,打掉各类制毒厂点72个,缴获各类制毒原料82.25吨。
在对毒品入境内流的堵截战役中,云南、广西等地积极组织开展堵截战役,有效堵截了大批毒品入境内流,会战开展以来,两省区共破获毒品犯罪案件1166起,抓获毒品犯罪嫌疑人1401人,缴获各类毒品2.04吨。
在对吸毒人员的查控战役中,天津、辽宁、山东、江西、宁夏等多个省份积极推行“逢嫌必检”等一系列有效措施,1个月来全国共新发现吸毒人员28288人,强制隔离戒毒19119人,同比分别增加55%和31.61%。
在对毒品集散分销活动的清剿战役中,各地积极深入侦控、打击各类跨省区、跨地市贩毒团伙,共确立部级毒品目标案件62起,打掉涉毒团伙163个。
在对外流贩毒活动的整治战役中,各地积极推动流出地和流入地的联合打击、协同整治行动,贵州省政府领导专门到毕节市纳雍县、大方县、赫章县等毒情重点地区对禁毒工作进行督导,指导外流贩毒整治工作。
在对网络涉毒活动的清理战役中,各地积极拓展、整合互联网涉毒违法犯罪线索,协作开展打击行动。10月4日,湖南、广东公安机关联合破获“2013-501”号公安部目标案件,抓获犯罪嫌疑人10名,缴获盐酸曲马多32.68万粒,摧毁一个长期通过互联网跨省非法贩卖盐酸曲马多的网络贩毒团伙。
http://news.163.com/14/1103/00/AA39DTJ00001124J.html
作者: 刘海明 时间: 2014-11-7 23:40
【案例】
数据挖掘与数据分析
中国为何这么重视APEC?我们怎样做才能不拖APEC后腿...

作者: admin 时间: 2014-11-8 09:07
【案例】
美媒:俄能灭800万中国军队
2014-11-07 09:15:23 来源: 环球时报-环球网 有15862人参与
美国《国家利益》网站11月3日发表《外交政策》和“战争无趣”网站撰稿人迈克尔·佩克的一篇文章,题为《亚洲最强的五支陆军》,摘要如下:
亚洲哪些国家的陆军堪称地区最佳?这是一个很难回答的问题。“最佳”陆军是说它作战技能最熟练还是装备最丰富?抑或是最符合本国需要?
但正是这样的疑问才让亚洲的情况显得更有吸引力。亚洲有各种各样的精悍陆军,但其精悍体现在不同方面。以下列举的是亚洲最强的五支陆军:
中国陆军规模庞大
有人说,中国军队是纸老虎,但如果你有800磅重,就算是一只纸老虎也能打败敌人。中国人民解放军陆军现估计拥有160万现役官兵和9000辆坦克,是世界上规模最大的常备军。
对中国的邻国和潜在敌人来说,很不幸的是,中国陆军的数量又是有质量支撑的。中国许多武器都是自己制造的,包括坦克、步兵战车和火炮。也许其质量并不总是最好的,但即使中国99式坦克不如M1A1“艾布拉姆斯”坦克,或者中国官兵不如美国海军陆战队训练有素、领导有方,那又有什么关系呢?只要中国以4到5个人对付1个敌人,同时拥有适当的军事技术,就算不是最先进的,也足以占据优势地位。
中国陆军规模庞大,在与邻国如越南或俄罗斯打传统陆战时享有优势,但对抗日本的能力更多取决于海空军实力。但不管怎样,单纯从规模来看,实力排在第一位的仍是中国陆军。
苏联遗产是俄优势
把俄罗斯归为亚洲国家听起来很古怪。但看地图就知道,俄罗斯有多少领土位于乌拉尔山以东。俄罗斯在亚洲的军事历史也很悠久。1904至1905年,沙俄曾在战争中输给日本,但1945年其最终击败日本,上世纪60年代又与中国发生了一系列边境冲突。
俄陆军规模远不及中国,仅有80万现役人员和3000多辆坦克。但俄罗斯保留了苏联时代设计先进、强大的武器的大部分技能,包括配有“阿雷纳”主动防护系统的T-80坦克、“旋风”多管火箭发射器、“科尔涅特”反坦克导弹,以及“黑鲨”武装直升机。中国购买俄罗斯武器,而俄罗斯不买中国武器。
莫斯科还具备其他强大的地面作战能力,比如其陆军拥有多个空降师及特种部队。
目前俄罗斯和中国似乎很友好,两国在2001年的友好协议中放弃针对彼此的领土声索。尽管如此,一些中国人认为,俄罗斯趁中国衰弱时掠夺了中国的领土。随着中国越来越强势,俄罗斯民族主义日益升温,有朝一日中俄之间爆发武装冲突并非不可想象。
俄罗斯在亚洲军事力量的实际问题是距离。西伯利亚远离俄军队和工业实力的中心。正如莫斯科在日俄战争中发现,西伯利亚大铁路是增援和补给位于几乎世界另一边的军队的漫长而脆弱的生命线。当莫斯科在东欧进入准战争状态的情况下,它还能向远东派遣多少军事力量?
有一个老笑话,说俄罗斯与中国开战,第一天消灭100万中国军队,第二天消灭200万,第三天消灭500万,第四天它投降了。
印度强军近乎疯狂
和中国一样,印度似乎是大有前途的亚洲军事强国。印度拥有一支庞大的陆军,现役官兵110万人,坦克3500多辆。1965年和1971年,印度与夙敌巴基斯坦之间爆发了两场机械化战争。1962年,印度和中国发生小规模冲突,1999年又与巴基斯坦短暂交火。
印度一直在疯狂购买军备,包括俄罗斯苏-30战斗机和法国“阵风”战斗机,以及俄罗斯二手航母。它还自主研制了“阿琼”坦克。
韩军不再是受气包
韩国陆军拥有约56万现役官兵,2300辆坦克。这支庞大的部队得到了本土军工业的支持,例如现代集团生产的K1主战坦克、155毫米榴弹炮、多管火箭发射器以及弹道导弹等。
韩国陆军以训练艰苦和纪律严明著称,尽管这并非一流陆军的先决条件。1950年,韩国陆军是一个受气包。今天,敢和它较劲的只有朝鲜。
朝鲜陆军无人敢惹
把一支忍饥挨饿的部队列入最强陆军名单,无疑很勉强。然而,朝鲜陆军拥有近100万官兵、4000多辆坦克以及超过1.3万门火炮和多管火箭发射器。该国粮食和石油可能短缺,但武器和弹药充足。
朝鲜装备日益老化,但仍足以给韩国造成破坏。更重要的是,平壤陆军的实力足以令谋求朝鲜政权更替的入侵者遭受重大伤亡。朝鲜陆军可能不是大象,但它就像豪猪一样,除非万不得已,你肯定不想惹它。(编译/汪强)
http://j.news.163.com/docs/99/20 ... 1MTO.html#newsindex
作者: admin 时间: 2014-11-8 11:54
【案例】
大漠零清
同意。中国统计数字
@风雨下黄山-黄生的博
人民币紧跟美元升值,但出口增长这么猛,贸易顺差这么大,非常理,不合逻辑,这背后有蹊跷!中国10月出口超预期,贸易顺差454亿美元大涨46%。10月份我国进出口总值3683.3亿美元,增长8.4%。其中出口2068.7亿美元,增长11.6%;进口1614.6亿美元,增长4.6%;贸易顺差454.1亿美元,扩大46.3%。
39分鐘前 来自 iPhone 5s
14分鐘前 来自 小米手机3
作者: 刘海明 时间: 2014-11-12 11:20
【案例】数据挖掘与数据分析
【京东移动端11.11大促下单占比超40% 下单量是去年同期8倍】11月11日,京东和拍拍网共售出超过35,186,616件实物商品,全天订单量超过1400万单,交易额是去年的两倍以上,移动端下单量占比超过40%,下单量是去年同期的8倍。其中,京东微信购物入口和手机QQ购物入口销售火爆,达到10月份日均水平的20倍
19分鐘前 来自 微博 weibo.com
[url=]收藏[/url]
[url=]轉發 7[/url]
[url=]評論 7[/url]
[url=]
7[/url]
作者: 刘海明 时间: 2014-11-14 13:22
【案例】
贪官贪多少可以上头条?
河北秦皇岛市北戴河区供水总公司总经理马超群7日被通报其家中被搜出现金约1.2亿元,黄金37公斤,房产手续68套。继魏鹏远之后,又一个让读者咂舌的贪官。

网友跟贴
1,678人跟贴 | 42,440人参与
http://news.163.com/special/toutiaotanguan/
作者: 刘海明 时间: 2014-11-14 17:54
【案例】@密苏里孙志刚
在每隔两年的2014年小选夜里,《纽约时报》的图表和互动新闻部推出了一系列经过精心策划的(与选举和选举结果有关)图表。当被问到在愈来愈激烈的媒体之间的竞争下,媒体应该如何在展现内容方面具有独特性时,它的负责人回答:1 满足公众/用户的基本需求;和2 让公众/用户获得难以从其它渠道获得的信息。
作者: 刘海明 时间: 2014-11-15 09:36
【案例】
检验一个男人是不是喜欢你,可以盯着他看10秒,看他会不会吻过来,检验女人是不是喜欢你,可以盯着她看10秒,看她会不会笑出来,做这个实验完全没成功,5秒不到就发生了以下对话:
女:“你看我干什么?”
男:“看你杂啦?你不看我你怎么知道我看你?”
女:“你看你个SB样?再看我喊人揍死你!”
一—总结,70%的斗殴事件的原因就是“只是因为在人群中多看了你一眼。”
http://www.haha.mx/joke/1525312
作者: 刘海明 时间: 2014-11-15 11:57
【案例】
肖锋
//@侯虹斌: 所以一个只有夸奖没有“抹黑”的国家,该是什么样的国家? //@应天澜:当一个国家所谓“选举”得票率超过七成时,那这个国家和专制很接近,得票率到达八成或以上时,可以说这里就是专制社会,当得票率接近百分百时,则毫无疑问,这是个独裁国家。
@草民杜楠
在朝鲜,不支持金家就自动失去了当人民的资格,成了人民公敌,然后让你消失,所以三胖可以充满自信的讲,金家执政是人民的选择,因为人民只有两个选项,生或死,不信,任何一家民调机构去朝鲜搞民调,三胖的支持率都会百分之百。
今天 09:15 来自 微博 weibo.com
22分鐘前 来自 360安全浏览器
作者: 刘海明 时间: 2014-11-18 17:52
【案例】
数据挖掘与数据分析
【数据分析的五大思维】讲讲数据分析: 数据分析的五大思维方式首先,我们要知道,什么叫数据分析。其实从数据到信息的这个过程,就是数据分析。数据本身并没有什么价值,有价值的是我们从数据中提取出来的信息。数据分析的五大思维:对比、拆分、降维、增维、假设。

25分鐘前 来自 iPhone客户端
- [url=]收藏[/url]
- [url=]轉發 21[/url]
- [url=]評論 1[/url]
- [url=]11[/url]
作者: admin 时间: 2014-11-18 18:34
【案例】喻国明:大数据新闻传播是什么 2014-11-17 [url=]中国报业[/url]


大数据新闻传播不同于传统新闻报道那样的简单数字交代,而是展示了一种从宏观与中观的层面对社会某一方面的趋势、动态和结构性的把握。大数据方法在新闻传播时间中的初级应用,是借助类似百度指数等各类数据采集和分析工具去挖掘散落在社会文本“碎片”中的具有新闻价值的资讯描述和意义表达。传统的新闻采集数据的方式更多的是通过线人、采访这种形态,而大数据方法为媒体工作者提供了一个全新的专业工具,帮助大家去挖掘新闻。
大数据方法视野下的新闻传播创新包含这样两个层次的内涵:首先,它是新闻形态的一种创新,包括可视化信息、人性化的嵌入。其次,它是一种全新意义上的内容创新,即通过碎片化的数据及文本的挖掘技术,实现了新形态的“减少和消除不确定性”的新闻内容。
大数据在新闻传播领域的实际应用
目前利用大数据资源的实际社会成效、有实际影响力的产品依然屈指可数。数据源的代表性和价值、良好的供给与需求的合作以及有广泛影响力的平台,是大数据应用获得成功的两条重要因素。
大数据可以实现一种在兴味盎然的“新闻游戏化”的参与中完成的传播读解和消费的过程。例如《华盛顿邮报》关于奥巴马就职典礼的报道,其网站中贴出了千兆像素的巨幅图片展示奥巴马宣誓就职场景,可以清晰地放大每一个局部,让每个参与者“找到”自己或自己的熟人。还有获得美国新闻奖的2013年的雪崩报道,以及阿拉伯之春立体四维报道西亚北非17国的情形,都是运用最新大数据的技术手段改革新闻报道的典型案例。
近期较为成功的大数据报道的案例,就是央视《新闻联播》在2014年春节期间播出的11集“据说”春运和春节。数据说春运和春节的成功有几大因素,其中包括新闻形式上的可视化的突破、新闻内容上的数据化和故事化的画面表达,呈现出“大数据小故事”。
大数据已经是一种客观存在。只不过相当长一段时间,人们缺少有效整合这些数据的技术和手段,并且人们对大数据的使用成本很高。互联网的OTT突破了原来的局限,解决了信息不对称的问题。其中的关键是大数据拥有方的合作与开放。“据说春运”节目的合作方的是百度公司,百度作为最大的中文搜索平台,每天要处理60亿次相关的搜索请求,其海量的数据能够生动翔实地反映中国网民具体的需求、兴趣点,搜索者本人的个人特点,等等。实际上,百度已经可以被视为中国最大的内容提供者。
现阶段大数据方法在新闻传播创新中的难点与关键
大数据方法在新闻传播创新中的难点与关键,现阶段主要集中在大数据方法与新闻传播价值逻辑之间的矛盾,以及大数据的数据源的开放等问题。
1.大数据与新闻的价值逻辑之间的矛盾
大数据与新闻报道之间存在着几对矛盾。首先,事实之间的相关关系在新闻传播中却进行因果关系的解读所构成的矛盾。大数据的核心特色是强调伴随性指标的相关关系,大数据方法甚至于公开拒绝因果关系的认识逻辑。但新闻的传统解读却是具有强烈的因果逻辑的。如果在新闻报道的呈现中不把因果关系考虑进去,不但与人们的认识逻辑相悖,而且也容易滋长解读上的随意性和偶然性,这样便使数据对于新闻报道来说失去了核心意义。其次,大数据的内在逻辑与新闻表达的逻辑在某种程度上是相悖的。因为大数据强调的是信息结构化,抛开故事中心,“去故事化”,这就和传统报道中的故事化诉求产生了矛盾。如何将结构化的数据表现出人类生活的温度和质感,是大数据在应用于新闻传播过程中的一项极为重要的课题。另外,大数据方法与新闻传播所要求的精确性之间也是存在矛盾的,新闻要讲究精确性,而大数据方法却是以模糊性的呈现和把握为特点的。
2.数据源的开放问题
在人人都在说大数据的时代,数据源的开放便非常重要了。互联网本身是由开放精神主导的。如果我们无从得到权威的数据源的话,大数据方法就是一句空话。因此,大数据时代,Google也好,百度也好,必须要有开放的心态。很多媒体在前两年打造自己的微博,看起来是一个交流的平台,但是完全忽略了一个核心原则——只有开放和实现彼此连接,才是具有真正交流价值的平台。就现实而言,有质量的大数据源常常掌握在政府及大公司手中,如何开放这种大数据源的使用,事关社会的发展和人民生活的福祉,必须从制度和机制上给予保障。在这方面,美国政府的数据开放政策不但为政府开放数据源起到了一种很好的参照作用,对于大公司所掌握的数据源的开放也有着重要的借鉴意义。如果掌握着数据的公司或政府将数据源封闭在自己的圈子里,数据的巨大社会价值和商业价值就无法实现。实践表明,对于掌握着数据源的大公司和政府而言,数据放开会使政府和公司得到的比贡献出去的更多。
大数据方法在未来发展中的“行动路线图”是怎样的呢?首先,大数据分析在方法论上需要解决的问题在于:如何透过多层次、多维度的数据集实现对于某一个人、某一件事或某一种社会状态的现实态势的聚焦,即真相再现;其中的难点就在于,我们需要洞察哪些维度是描述一个人、一件事以及一种社会状态的最为关键的维度,这些维度之间的关联方式又是怎样的,等等。其次,如何在时间序列上离散的、貌似各不相关的数据集合中,找到一种或多种与人的活动、事件的发展以及社会的运作有机联系的连续性数据的分析逻辑。其中的难点就在于,我们对于离散的、貌似各不相关数据如何进行属性标签化的分类。概言之,不同类属的数据集的功能聚合模型(用于特定的分析对象)以及数据的标签化技术,是大数据分析的技术关键。
其次,从表现角度来说,嵌入是关键词。我认为,大数据呈现的结果和结论,与人的需求、人的行为、人的认识逻辑需要有一种相适应的嵌入。尤其是在大数据刚刚进入社会生活领域的时候,一定要顺势而为,跟人的需求相关,跟人的认识行为逻辑相关,这样人们就比较容易去解读它,然后去把握它,去消费它,去使用它。比如,与新闻媒介相结合的时候,新闻媒介自身的传播逻辑、传播规则、传播样式,新闻媒介在传播过程的需求点上可以嵌入当中的哪些大数据的服务。这要有更多的数据专家去解读。
最后,与现有的可视化技术发展相联系。日常生活中一些重大的新闻如果能够运用大数据来报道,其深度会大大强化,也能够给人以更强的动感和说服力,并且帮助人们比较准确地把握未来。在这个意义上,大数据与新闻的结合,将是新闻竞争的巨大技术驱动力。
概言之,大数据方法是需要社会规则创新和高智力投入的一项伟大的认识与实践范式。
作者:喻国明(中国人民大学新闻学院教授)
本文原载于:《新闻传播的大数据时代》中国人民大学出版社
http://mp.weixin.qq.com/s?__biz=MzA4NzUxMzYwMw==&mid=202611186&idx=4&sn=2c4f384f488f5f5cf137c3f64633c5f9&key=62355daf7efec1af047074700d047667fe454518a12189e86ab60ca195f3be661232cefd507741072a53b55411aace68&ascene=7&uin=Mjk2NDAyMjQyMw%3D%3D&devicetype=android-15&version=26000036&pass_ticket=jI72tsc%2Bmf8e0U%2F1y%2BwtSxJMB%2FrYogWGJtMLwiq%2FkBrxJTzqC2kQwtN0%2F0qEC%2F0a
作者: admin 时间: 2014-12-19 18:23
【案例】

[size=1.4]厨子与剑客 10:07 / 19
只会写稿的记者Out了?哥大新闻学院开设大数据和编程课程
数据和算法正在改变着各个行业,重新塑造我们的生活。现在起,讲故事也该靠数据了。据
recode的消息,哥伦比亚大学新开设了一个名为
Lede项目的新闻学硕士学位项目。完成的学生将获得一个数据新闻学位。
这是新闻教学领域的一次大胆尝试。参加这个项目的记者们将学习如何编程,如何处理数据图表等技能。当然,所有的数据分析和处理技能都将以社会学和人文科学为背景。目的是让学生们为将来开展数字统计驱动型的媒体业务做好准备。此前美国已经出现了这样的媒体,比如:
FiveThirtyEight,
the Upshot。
在首期课程中,学生们分析了白宫的客人名单,尝试用数据分析的方式来判断财富是不是这些人能够成为白宫访客的影响因素,他们还分析了到访行为对随后发生的事件是否存在影响。还有同学分析了视频游戏平台上的聊天记录中体现的群体性特征。发现男生玩游戏的时候,人们的评论内容主要是针对游戏本身,而女生玩游戏的时候,评论的对象却会变成游戏者。
有没有觉得很有趣?不过
学费不便宜。10 个月的课程,学费接近 6 万美元,加上食宿大约需要 10 万美元,堪比商学院开销。
在大胆尝试的过程中,哥伦比亚大学的新闻学教授 Mark Hansen 和 Jonathan Soma 也表示出一些担心。他们认为目前的主流媒体可能认识不到这些学生的价值。很担心他们会成为新闻媒体中的码农。不过,对数据改变新闻的趋势他们表示很有信心。
或许这正体现了哥大新闻学院一直以来敢于实践的务实风格。就像哈佛商学院以案例教学而享誉商学界一样,在新闻教学领域,哥大一直以重实践的教学内容而与众不同。它的创始人约瑟夫渠利策在建院前曾表达过自己的新闻教育观点。
“我的想法是将新闻作为一种崇高的知识分子的职业,用实践的方法鼓励、教育现在、将来的从业人员。”
哥大新闻学院一直以来正是依靠秉承这种理念在美国新闻学排名中位列榜首。
作为一个数据乐观派,我真希望在不远的将来,依靠数据得到的洞察,能在普利策奖中占有一席之地。对了,哥大新闻学院还肩负着每年新闻界桂冠——普利策奖评选的任务。
http://www.36kr.com/p/217982.html
作者: admin 时间: 2014-12-26 20:24
【案例】
@廉政公署V
中国最搞笑的地方在于,油价、电价、医药价等物价调节不归物价局管,而归全球独一无二的发改委管,那还要物价局干吗!发改委死扛不降价,以税代降,油价 140 美元时,每升 7 块多,现在50多美元,怎么还6 块多?国家日哄老百姓的招数真是日新月异!建议为坚守油价的发改委申报本年度敢感动中国好衙门!
作者: 殷玉鑫 时间: 2015-4-23 21:45
【案例】八张图告诉你移动互联网对传媒业的影响
移动互联风潮席卷全球每一个角落,而颇为敏感的传媒业首当其冲。过去十年间,传统媒体已经深深陷入了“不改变,无生路”的魔咒中,一大批传统媒体纷纷倒下。但欣欣向荣的是那些诞生于网络的新兴媒体,它们的活力与朝气似乎让人觉得“未来是你们的”。
移动互联网时代已经到来

传统媒体现状:日薄西山,不是在转型,就是在转型的路上

媒体发展趋势:移动互联网下的新兴媒体


传统媒体衰落的原因:互联网时代导致话语霸权的丧失

视频网站对电视的冲击

移动互联时代对原有广告规则的改变

传统纸媒在移动阅读面前溃不成军

总结
一方面是传统媒体的衰亡,一方面又是新兴媒体的崛起。与其说是互联网冲击了传媒业,倒不如说互联网是传媒业进化的契机。毋庸置疑,传媒行业将在移动互联网的渗透下,重塑成一个我们难以想象的新模式。
http://www.neweyeshot.cn/archives/17634
作者: 殷玉鑫 时间: 2015-5-2 00:08
本帖最后由 殷玉鑫 于 2015-5-2 00:11 编辑
【案例】财新是怎么玩数据可视化的
一、数据新闻之我见
可视化的概念应用在新闻领域,就是数据新闻(DataJournalism)。可视化技术,将数据展现为直观的图形,以帮助理解和记忆。信息传播的可视化有三个主要分支:科学可视化、信息可视化和可视化分析。
——科学可视化,主要用于处理科学数据,如地理信息、医疗数据等,以自然科学领域为主。我们日常接触到的地图、气象图、CT等都属于典型的科学可视化。
]——信息可视化,主要用于处理抽象数据,如金融交易、社交网络和文本数据。路上看到的交通标志牌、Excel中的饼图、柱形图、折线图之类,都是我们每天都可能接触到的信息可视化作品。
——可视化分析,以可视交互界面为基础进行分析推理,综合图形学、数据挖掘和人机交互等技术。简单理解,看K线图分析股价涨跌背后的规律应该是最常见的可视化分析。
可视化概念应用在新闻领域中,就是数据新闻(DataJournalism)。数据新闻的主要表现方式包括静态信息图和互动图表。静态信息图由编辑和设计师合作完成,展示在纸面或屏幕上。在以前,信息图的制作靠手绘,现在靠设计软件,信息图往往突破版面的框架,内容比文字丰富和生动,在这个读图时代比以前更受欢迎。互动图表完全依赖互联网,因此它到这几年才随着互联网的普及而盛行。互动图表由编辑、设计师和程序员合作,通过编程在网页上实现数据可视化,再借助互联网,通过电脑或手机传播。用户通过操作电脑或手机,可以增加或筛选展示的内容,或进行可视化分析。
静态信息图和互动图表最大的区别,在于后者需要程序员介入。设计师不能再天马行空地设计图案,必须考虑程序员的编程能力和程序的限制。
二、财新传媒的数据新闻探索
]数据可视化在报道呈现中有两种利用方式:辅助理解和用图表讲故事。辅助理解类似于插图或配图,是将可视化作为文字报道的辅助手段,这也是常见的方式。用图表讲故事是不借助文字报道,独立用图表展示一个完整的故事,或引导用户接受一个接论。
以《青岛中石化管理爆炸》为例,它的核心是将爆炸现场拍摄的照片按拍摄位置还原到谷歌地图上,使用户获得身临其境的感受。在新闻的开始,先依次用几个画面,将地图逐步缩小,让用户逐步了解山东、青岛及发生爆炸的黄岛区的具体位置,配合文字描述,将事件时间、地点、起因等背景做完整的交待。
数据挖掘与可视化分析关系密切,通过将数据图形化,展示原本被忽略甚至无法发现的特征。
以《三公消费龙虎榜》为例,我们将2010年以来官方公布的90多个中央级单位的三公消费数据录入数据库,加以图形化和排序,使用户了解什么是三公消费、每个部门的支出和组成如何、人均支出如何等等。它是一个数据库,可以将枯燥的数据变得生动易懂。它不讲故事也不给结论,每个用户可以发现不同的内容。
媒体抄袭报道的事情时有发生,网络文字报道抄袭尤为严重。要解决这个问题,当然需要媒体需要自律,同时,以数据新闻形式发布新闻也有助版权保护。互动图表网页以代码支撑,可以加密。盗版需要程序员加工和适配,远比复制文字复杂。此外,每个程序员都有自己一套编程习惯,风格各异,代码的辨识度非常高,是否抄袭,非常容易辨别。
媒体都苦恼请不到好的技术人员。优秀的技术人员通常会选择在互联网、IT公司工作,或者自己创业,很少会选择到媒体工作,除非媒体能让他们在专业领域里有最大的发挥。数据新闻各个环节,包括数据挖掘、分析及可视化,都需要技术人员深度参与;加上这个领域高速发展,程序员参与数据新闻制作的过程中,能接触前沿的技术,对自身专业发展极有帮助。
三、如何建数据新闻
财新可视化实验室是一个虚拟部门,团队由三种人组成:编辑、设计师和程序员,三方是合作和互动的关系。实验室并行多个项目,每个项目按需要抽调人手组成项目组,有时还会与记者合作。
数据新闻团队由三种人组成:编辑、设计师和程序员。财新可视化实验室10名成员分布编辑部门、设计部门和技术部门。实验室并行多个项目,每个项目按需要抽调人手组成项目组,有时还会临时与不同记者合作。
传统的生产流程中,采编人员、设计师和程序员是上下游的关系。采编人员生产出稿件,然后由设计师配图和排版,再通过程序员发布出去。数据新闻要求新闻生产流程做出根本的变化,需要团队在各个环节不间断地讨论与合作。例如设计人员根据采编人员提供的素材设计图形,同时与程序员沟通,如果开发成本太高或周期太长的话要修改设计方案。在方案设计的过程中,程序员很可能反过来要求记者补充数据。一旦方案确定,设计、开发、文案同步进行。所以三方是合作和互动的关系,设计师和程序员在整个新闻制作流程中的参与度非常高。
最理想的数据新闻人选既懂新闻、又懂设计、又懂编程。但实际上,由于文理分科、高校课程设置等原因,国内找不到三项全能的复合型人材,因此只能通过团队合作来实现。庆幸的是,现在个别高校已意识到这些问题,尝试开设数据新闻实验班,对学生做综合培养。
财新开发互动图表作品,主要工具有HTML5、CSS3和JavaScript。用HTML5绘制图形和动画,用CSS3实现排版,用JavaScript处理交互和动画。学会以上技术,可视化制作门槛会迅速降低。新闻工作者都应该掌握以上三种工具。除了代码技术以外,每个数据新闻记者都必须熟练使用Excel。记者可以利用Excel清理及组合数据,也可以自定义算法,对数据进行统计分析。
四、作品个案分析
案例 1
青岛中石化管道爆炸事故
——财新记者实拍图集
2013年11月22日10时25分,山东青岛,位于黄岛区的斋堂岛街突然发生一场惊天爆炸,造成62人死亡、136人受伤。这是一次极罕见且后果严重的城市灾难,居民在厂房工作、街头下棋、买菜、行走、开车时被炸死。调查结果表明事故原因是中石化工东黄输油管道泄漏,原油进入市政排水暗渠,在形成密闭空间的暗渠内油气积聚遇火花发生爆炸。
财新记者在事件发生后第一时间赶赴现场,与后方三十余名工作人员组成联合报道组,分布在青岛、北京、上海、广州等地,24小时关注事件进展,运用新技术手段协同工作。该系列报道大篇幅多角度完整呈现了事件的始末,深入挖掘了事件根源。
图注:将爆炸现场拍摄的照片按拍摄位置还原到谷歌地图上,配合文字描述,将事件时间、地点、起因等背景做完整的交待,使用户获得身临其境的感受。
图集充分利用前方记者获取的采访信息,通过引导及交互两个界面,以数据新闻的方式呈现了事态进展,尤其是以卫星定位技术,将前线记者所拍照片标注于地图上,让读者更容易理解各爆炸点的地理位置与爆炸时间,帮助用户建立对事件起因、经过、影响等的直观感受,见证了财新团队利用移动互联网技术和新媒体手段报道重大突发事件的突出能力。
当时报道团队有30多个人,三位记者在青岛,其他人分别在北京、上海、广州等地。团队当时以微信群聊实现遥距协作,效率非常高。前方记者在赶路,看到情况就发送微信语音,后方即时打字成稿,经编辑校对、核实后发布。记者也可以用微信分享地理位置,后方团队对照地图,帮他们指路。这次报道也改变了报道流程:以后的重大报道,必须有技术人员参与其中,给予技术支持。这个报道时效性要求非常高,从实验室决定要做到写完代码,只有12个小时;从决定要做到最终上线,只花了24个小时。作品的装饰性元素很少,但很实用。上线当天,财新网(caixin.com)访问量创下记录。
报道链接:http://datanews.caixin.com/2013-11-24/100608929.html
案例 2
手机端作品:财小新带你摇车号
手机端发布信息受众广、易传播,尤其现在大家都习惯用朋友圈,分享内容非常便捷。实验室的制作原则就是移动优先,每个作品,我们都要希望分别在手机、PC各做一个版本;但如果时间不足、资源不够,我们会首先选择制作手机作品。PC和手机的操作方式不一样。用户在电脑上用鼠标可以作出精确的操作;在手机上,操作方式就不一样,用户可以单击、双击、放大、缩小、滑动、摇一摇、或者是通过音频驱动,加上不同的开放接口,例如调用音频、拍录视频等,这些因素都影响产品呈现的形式。

这个手机端作品在2014年六月份推出,是一个典型的把新闻转变成交互游戏的例子。北京交通拥堵为控制市内车辆数量,实施购车摇号。去年六月份的车牌摇号命中率是137:1,这个比例不易理解。现在每年有6次摇号,按当月命中率来算,运气好的话,大概12年就能摇中。
但并不是很多人懂得这样算,所以我们就把这条算题,变成一个游戏,用户可以试试手气。这个项目制作只需半天时间。发布时,我们做了个朋友圈传播测试:当天我们两、三个人首先在朋友圈上分享这个作品,不加其他推广。结果第一天录得访问量3000多次,第二天有5000多次,第三天录得30多万次,第四天更高达50多万次,第一个星期的总访问量是达到150万次。我们也没有预计到作品有这样的效果,这给我们的一个启发:新闻可以做成交互游戏,我们要有意识利用手机的特点做出不同的尝试。
报道链接:http://datanews.caixin.com/page/car_lottery/
[案例 3
天猫双十一 狂欢大起底

图注:用HTML5和数据可视化进行品牌传播。由合作方提供数据,实验室对数据进行分析和提炼,并提供可视化技术支持。
该作品用HTML5和数据可视化进行品牌传播,两天获得20万访问量。由合作方提供数据,实验室对数据进行分析和提炼,并提供可视化技术支持。
作者|黄志敏 陈嘉慧
来源|传媒评论
作者: 殷玉鑫 时间: 2015-6-26 22:34
【案例】BBC如何做医保大数据新闻 且得了新闻大奖
 2
|
|
作为老牌传统媒体的代表,BBC居然在今年网络新闻奖的评选中一枝独秀,独揽五项大奖,可让小编真心佩服。除BBC外,有哪些媒体及其作品脱颖而出,得到了评审团的青睐?
编译/ 郝思斯
网络新闻奖揭晓:BBC、半岛成大赢家
在六月十日于伦敦举办的The Drum's Online Media Awards上,各大媒体机构对包括"年度杰出数字团队"、"最佳众筹/公民新闻奖"和"年度突发新闻奖"在内的一系列奖项展开了激烈的竞争。老牌媒体BBC一枝独秀,独揽五项大奖。半岛英文台和Vice紧随其后,各拿三项大奖。路透社凭借"For Water’s Edge"捧走了"评审团大奖",今日美国则靠"Fugitives Next Door"抱走了"最佳行动/调查报道奖"。
BBC的"NHS(英国国民健康保险制度)之冬"项目通过收集普通市民冬日就诊的具体数据(如等待时间、就诊时间等),以估测NHS在疾病高发、事故频繁的冬季的应对表现,获得了"最佳众筹/公民新闻奖"。值得一提的是,这一奖项的四个提名项目皆来自BBC。
今年的新奖项——"最佳媒体播客奖"同样颁给了BBC的The Ouch Talk Show。这个周播的音频节目主要围绕"失能"这一话题进行一些轻松愉快的访谈和讨论。
除此之外,BBC新闻在线还将"全国/全球最佳新闻网站"、"最佳视频新闻"和"最佳推特新闻"三项大奖囊入怀中。
 2
|
|
紧随BBC之后的赢家Vice因伊斯兰国家主题的纪录片获得了今年的"大赛冠军奖"。Vice News Europe 的制作总监Yonni Usiskin称这些奖项"确实是对我们去年开办Vice News时付出的肯定",Vice拥有一个"满是年轻而才华横溢的记者、电影人和作家的团队"。
"我们见证了这几年来观众们关注点的改变,网络上的劣质新闻内容已经不能让他们满意。所以我们要求网络视频的质量能达到提供给HBO的电视节目的质量水平,我们也正在以同样高的标准来制作专题片。"
半岛电视台英文台因"巴勒斯坦混响"项目赢得了今年的"年度杰出数字团队奖"和"最佳技术创新奖","瑜伽者肖像"项目则为他们带来了"最佳摄影奖"。
通过交互式页面呈现的"巴勒斯坦混响"项目于2014年上线,用纪录片、地图、时间轴和小测验等形式综合呈现了被占领的巴勒斯坦地区。项目团队在制作过程中使用了一个叫做Hyperaudio的工具,可以很好地将文字、视频等内容组合起来,形成交互式的页面。
所有奖项都于当晚在伦敦举行的颁奖典礼上颁发,获奖者除了各大新闻机构外,大会同样颁出了几个有分量的个人奖:来自Vice UK的Alex Miller和国际商务时报英文版的Anthony Cuthbertson分获"年度网络编辑奖"和"年度网络作家奖"。
至2015年,网络新闻奖已成功举办五届。今年的大会评审团由二十四位来自全英各大媒体的资深记者、编辑和高校新闻学院的教授、学者组成,共评出二十九个奖项,较2014年增加了三个。除The Drum 网站外,大会主办单位包括IOMART集团、英国联合社、全国记者联盟、编辑社区、英国新闻评论、新闻公报等机构。
BBC
NHS之冬
每一个冬天,NHS都必须面对额外的压力——包括让我们生病的诺瓦克病毒和流感,或是可能让意外事故频发的坏天气。BBC试图近距离观察病人、医务人员和政府部门是如何度过冬季这几个月的。当寒潮第一次袭击英国时,BBC开始推进"NHS之冬"项目,用以检验NHS在寒冬的考验下究竟表现如何。他们通过BBC的网站及Facebook、Twitter等社交媒体向普通市民收集就诊的数据:花多长时间预约、花多长时间候诊、平均就诊时间,以及具体就诊时的经历、感受等。同时,他们还向工作在一线的医生护士收集数据资料,试图从内部了解NHS在冬日的运作状况。
 1
|
"NHS之冬的Facebook页面。 [url=][保存到相册][/url] |
这一项目推出后,引起了市民们较大的参与热情。每周,BBC都会将公开收集的数据分类整理、制作成可视化的数据新闻,所涉及的数据上至枢纽型的医疗机构,下至街边小诊所。BBC负责报道医疗健康新闻的记者Nick Triggle每周都会对数据进行分析和评论。
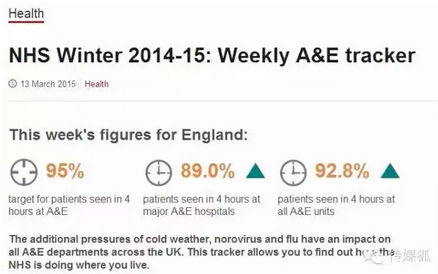 1
|
BBC每周会对收集的数据进行整理,制作成可视化的新闻页面。 [url=][保存到相册][/url] |
"NHS之冬"通过数据从现实层面证明了随着冬天的到来,疾病和意外事故确实越来越多,相伴而来的对于医疗服务的需求亦与日俱增:NHS正面对着充满挑战的严冬。
半岛台
巴勒斯坦混响
"巴勒斯坦混响"是半岛电视台英文频道于2014年11月全新上线的大型交互式页面,汇集了一系列关于被占领的巴勒斯坦地区的纪录片、地图、时间轴、小测验、资料库等的内容。页面的中心是"混合"功能,用户可以从中查找17个交互式纪录片页面中的所有内容,在社交媒体上分享自己感兴趣的信息,或是自己"重组"页面中的视频素材,用以讲述新的故事。
 1
|
“巴勒斯坦混响”的首页。 [url=][保存到相册][/url] |
这个项目让用户能够让用户看到半岛英文台制作的关于巴勒斯坦地区的纪录片,交互式的地图和时间线则试图让用户能更深入地将巴以问题置于真实情境中理解。
项目的导演、高级制作人Rawan Al-Damen称,这些纪录片是从焦点影业近十年来关于巴勒斯坦的纪录片中精心挑选出来的。他们通过这种方式"解放"了纪录片,不再局限于过去电视上播放时固定形式、固定时长度的刻板模式中。
通过对影片关键词如"加沙""阿拉法特""内塔尼亚胡"的搜索,用户可以很容易找到包含相关内容的所有画面,你可以一键通过社交媒体分享这些内容,如果有兴趣,还可以通过页面嵌入的编辑工具来自己重新对内容进行编辑组合。
"巴勒斯坦混响"使用了最新的HTML5视频技术,加上涉猎广泛、极具观赏价值的纪录片内容,让观众切切实实融入至团队讲述的故事中。整个制作团队都在不断努力尝试使用新的表现方式来讲故事,得奖既是对他们所做内容,亦是对他们勇于尝试创新表达方式的肯定。
来源:搜狐传媒
http://media.sohu.com/20150624/n415528234.shtml
作者: 殷玉鑫 时间: 2015-6-28 23:06
【案例】财新数据新闻主编谈数据新闻
黄晨:工学学士、经济学硕士,2010年初加入财新,先后负责数据库产品、数字说栏目的策划和采编。2013年10月加入财新数据可视化实验室,参与众多可视化作品的策划工作。
移动端给数据新闻带来了哪些创新与挑战?数据新闻的前景如何?制约国内数据新闻发展的因素有哪些?如何培养数据新闻人才?财新的数据新闻团队如何运作?且看本公号对财新网数据新闻主编黄晨的专访。
1 移动端给数据新闻带来的创新与挑战
创新
移动端给数据新闻带来的创新包括两点:一个是html5在移动端的广泛使用,另一个是通过朋友圈推广的传播途径,这是在PC端没有的,有了移动端随手就会把自己看到喜欢的东西转发。
其实h5本身并不是一个新的技术,h5是html5,是一个协议,我们在pc端上有很多设计都是用h5实现的。但h5之前的问题是对不同的浏览器兼容情况非常差,这会导致工程师会做很多工作,使一个网页适配不同的浏览器,当浏览器的市场份额不是特别集中地时候,没有办法去侧重某一个,必须去做兼容性的工作,所以工程师的成本非常高。但是到了手机上,浏览器非常集中,只要把苹果和安卓两种系统浏览器兼容适配好就行。
h5不仅应用于数据新闻,比如h5也可以做邀请函。但数据新闻借助h5的普及和应用在微信手机端上传播,现在朋友圈转发是h5推广的主要路径。
挑战
相比创新,挑战更多。
通过扫码的方式PC端内容可以导到移动端看,但是PC端没有一个很有效的链接,把移动端的内容有效的返回到PC端。这个信息流是单向的,所以现在大家更依赖移动端。
我觉得对数据新闻来说最大的挑战是取舍的问题,设计者可能完全要重构。因为数据新闻有很大量的数据来支撑,如果数据不够大,用文字就可以说清楚,没有必要认为数据新闻这个东西很时髦,所以什么东西都扣在这个壳子里。其实文字在PC端和移动端变化不大,只是一个排版的变化,但是数据新闻必须有大量的数据在支撑,放弃的结果就是数据新闻呈现得不够,有的时候会非常的扭曲。
其次,从交互角度看,层级深的东西在移动端难以呈现。比如说你看到我们的《三公消费龙虎榜》,一进去是一个矩形的图,你肯定会去点击它,发现它弹出新的信息,再去点击标签,会发现它进入二级页面,这就是层级。交互类的产品层级多一点会比较好玩,因为用户会觉得有粘性多看一下。而像三公消费这样层级深的东西在移动端就没法呈现。用户不太喜欢在移动端交互,容易点选选不中,之前的观看经历可能影响使用习惯。
再次,篇幅也是很大的挑战。移动端的兴起加剧了传播的碎片化,导致用户现在很没有耐心去阅读一篇长文章,大家都喜欢在朋友圈看那种一两千字的鸡汤文,配很多图片,加一点点缀的图。所以现在做的比较多的都是一图看懂。碎片化的挑战,导致篇幅要压缩,去年我们还认为15页以内是较好的,现在认为是七八页,再长大家就会没有耐心看。
2 数据新闻的前景
《卫报》开创了数据新闻的先河,纽约时报的《雪崩》重新定义了数据新闻,大家觉得这东西太好了太酷炫了,所以一窝蜂地去做数据新闻,但是不是想好了呢?这很难说。很多媒体觉得数据新闻比较时髦就去做,但是也许未来又会出现一种更流行的报道方式。
数据新闻不能拘泥于数字新闻,图片、视频、音频都是数据,我认为未来数据新闻应当定义为多媒体新闻。《雪崩》是一个必须要学的案例,它是一个多媒体新闻,里面有信息图、动画、视频等,搭载了许多不同的题材。这让事件陈述得更加立体,而仅用文字是很难说清的。
目前信息图是常见的数据新闻形态,它的体量有限,因此应集中反应一些数字型数值型的内容。而目前流行的一图读懂作品中很多是靠把大量的文字码放在一张图片里,构思上存在较大的同质化现象。各种信息图栏目和信息图泛滥,容易导致大家的审美疲劳。我认为经典的东西应该是绵长的,而这种迅速火起来的东西很快就会衰落。
3 制约国内数据新闻发展的因素
制约国内数据新闻发展的最主要因素是观念。根本来说,中国人的数据素养比较缺失,包括孔孟文化,中医文化这些内容都要自己去悟,连科举考试也不考数学。
新闻行业从业者大部分是文科生,文科生会有很多的方面的优势,因为新闻是文字的传达。但是在新的时代下,对技术,对数理结构的理解,会使文科生发现自身知识结构的欠缺。
在美国其实也是这样,美国纸媒也受到网媒很大的挑战,白发苍苍的老记者有很好的文字功底,但是他们用的最好的东西就是word,所以没法去跟其他环节来配合。还是需要一个比较年轻的记者,将他们的报道翻译成和技术设计人员合作的内容。
在财新我就承担这种责任,如周永康的稿子是一个六万字的纯文本文件,要让六万字变成一个数据结构的呈现,就必须有人在中间做翻译工作。当时我做的就是这种翻译的工作。我是学理工科的,虽然不会写代码,但基本明白工程师的逻辑,这种逻辑训练得益于理工科的学科训练,而中国目前大多数媒体从业者仍然是文科生,向技术难度较高的行业拥抱的时候,理工科教育的缺失会导致一些困难的出现。
我们招人的时候,发现他说我会写稿子也会写一点代码,就会让我们觉得眼前一亮。公司里不会真的让你去写代码,我们会招专业的程序员,因为效率比你高很多。国内记者目前没用既能做设计又可以写代码的。
4 数据新闻人才的培养
我认为学校应开设一些导论概论方面的课程让学生了解这个领域。学生应该知道将来如何和工程师交流,能够理解别人需要你提供什么。你只要能明白这些,实践没有那么强,都没问题。一个受过专业训练的人,可能在写作的时候就会一次性形成一个能被下一步调用的东西,这会非常节省时间。
我认为培养数据新闻人才,学校只是打一个基础。融合培养就业面会更大,因为以后互联网媒体或者说传统媒体对新媒体的需求越来越高的时候,你掌握多一门技能肯定更具竞争力。
培养数据新闻人才,除了新闻通识以外,还应该涉及设计部分。因为设计能够让你对色彩、构图有一些基本认知,包括网页设计,因为网页设计有一些固定的内在规律,比如说提交一份表单,注册,注册页面里面有很多设计的规律在里面,只不过用的很舒服的时候意识不到,但是如果用到一个非常不舒服的表单的时候,你就会想怎么这么难用啊。难用和好用之间是有科学在里面的,科学是可以在学校里面有一个基础的培养的。潮流会变,但是怎么获得好的交互性,怎么让用户用得舒服,这些理念是不会变的,这种理念是可以在学校里面培养的。
哪怕在学校里学到的东西已经过时,但是你拥有了一些基本的设计理念。不用害怕技术会过时,最关键的是脑子里要有概念,并愿意在实践中不断学习提升。
5 财新的数据新闻团队
每个项目都是一个博弈的过程,也是试错的过程。
文字、设计、技术三方面要紧密合作,这不是一个串联的过程,不是每个人只干完自己的然后扔给下一个人。它是一个网状作业模式,而非流水线作业,这是非常颠覆的。
过去传统的文字记者,只要去办公室开会报一下选题就可以,下周开始自己写稿子,然后编辑开始催稿,把邮件发回去。除非是一个非常大的稿子,一般同事之间很少七八个人一起协作。可以不需要见面,大家在网上邮件沟通就行。
但是我们不行,我们每个项目一开始都要一起碰,我们的工位离得很近,经常走过去就要沟通,要去谈,去讲。你每天必须到办公室来,必须坐班,必须要沟通。对于互联网公司来说,远程合作和远程办公效率是非常低下的。
胡舒立本人对新媒体态度很积极,她推动财新网建立起一个相对与其他的媒体比较强的技术团队,如果没有技术团队的话新媒体是根本没法开展的。得益于这种顶层设计,我们才建立起相对其他纸媒同行来说还不错的技术团队,有了技术才能谈其他的。
有些知名报社称自己内部管技术的部门为网络部。但是一个互联网公司不会有一个部门叫网络部的,因为这个公司就是一个互联网的公司,网络部干的是什么工作呢?把自己一周的报纸每一天发一点儿,发到网上去,这还是一个比较陈旧的纸媒思维。
来源: RUC新闻坊(公众号)
http://www.mediaob.com/viewpoint/2015/0628/1982.html
作者: 殷玉鑫 时间: 2015-7-13 21:13
【案例】美国如何运用媒体大数据
上世纪90年代中期,SGI公司首席科学家John Mashey率先使用“大数据”一词,意思为使用与分析大型数据,随后大数据一词在各行各业渐渐传播开来,并在近几年逐步渗透到人们的日常生活中。那么,在美国,大数据是如何使用的?
社交媒体大数据:政府舆情观测站
美国政府通过新媒体打击中东恐怖分子,通过YouTube开设一系列节目,来阐述美国政府对中东恐怖分子的政策、方针,向全球各地的人传播其观念。
美国的政府事务管理部门每天都通过推特进行用户分析,来观测舆情的变化,与用户相连,并可以接收用户的反馈,与用户互动等。这样,在国家治理方面,社交媒体与大数据就会使得国家与百姓之间的联系更加紧密。
此外,美国政府还利用社交媒体和大数据建立社会网络,在纽约,政府利用推特建立了许多社会行业相互连接的社会网络,连接了包括汽车、房产、地铁、零售等各行各业。这个时候,政府就可以通过整个网络进行分析预测,探究各个行业可能出现的问题并及时给出相应的策略,服务美国人民。
在社会救助层面,大数据也有其独特的优势。当龙卷风袭击新泽西的时候,当地的居民通过社交媒体传递给外面他们最需要什么救援的信息。政府通过对大数据进行分析,明确了什么是最需要的救援物资,哪个地区需要哪种物资等,极大地提高了救援的效率。
数据新闻课程:教育变革突破口
大数据如此重要,培育大数据人才便成了各个国家新闻教育的一个重点发展方向。骑士基金会2月发布的名为《向上与超越:初探新闻教育未来》的报告中称,如今,辨别和掌握市场趋势与媒介技术,并能将其与新闻生产快速融合的技能对于新闻教育至关重要,且其重要性不亚于对美联社体和倒金字塔结构的掌握,但美国的新闻传播学院反应过于缓慢,目光短浅。
尽管报告指责了新闻传播学院的反应,但这并不代表美国的大学毫无作为。目前,许多新闻传播院校已开设了数据新闻课程。尽管这些课程的名称不尽相同,但其核心都是培养学生的数据分析和报道呈现的能力。例如纽约大学开设的“小数据新闻”“数据分析和数据可视化”课程;加利福尼亚大学伯克利分校开设的“数据可视化”课程专门请业界大咖进行传授,花费不菲;哥伦比亚大学更是在统计系和新闻系都开设了数据新闻的课程,让除了新闻学之外的其他人才在学生时代就大量接触数据新闻,为大数据的多元化发展提供保障。
作者: 赵鸿宇 王佳明 王迪
来源:中国新闻出版网
http://media.sohu.com/20150708/n416361840.shtml
作者: admin 时间: 2015-7-25 09:29
【案例】
英美中日印:记者到底能赚多少钱?
2015-07-24 00:58
阅读
6322
文|图 雷曼的兔子
“当这个国家不在最佳状态时,记者是启迪人们灵感的一群人。”英国前首相丘吉尔如是说。在政界崭露头角之前,他曾经做过随军记者,对这种职业有深刻的体验。如今,在信息时代,不管在哪里“启迪人们灵感的这群人”也都面临着种种挑战:网络和社交媒体的冲击,收入和社会地位的双重下降,每况愈下的社会信任度……那么问题来了,在这种背景下,各国记者到底能赚多少钱呢?
美国
美国佐治亚大学对2012年美国新闻和大众传媒专业毕业生市场调查显示,新闻专业毕业生平均年薪为3.2万美元(约19万人民币)。据美国大学与就业协会统计,2012年美国所有毕业生的平均年薪为4.27万美元(约26万人民币),这一平均标准比新闻和大众传媒毕业生高出1万多美元(约6万人民币)。为贴补支出,近年来很多新闻和大众传媒专业毕业生都在寻求自由撰稿人等差事。根据薪酬调查公司Payscale在2015年3月份最新发布的数据,美国记者的收入中位数仅3.8万美元(约23.6万人民币),而一名木匠的收入中位数是4.1万美元(约25万人民币)。
美国求职网站Career Cast评出的2015年十大最差职业中,记者以工作任务重,压力大,收入低,升迁前景不好,登上了十大最差工作的“宝座”,进入十差之列的还有摄影记者和播音员,也跟新闻记者有关。
其实,美国记者对未来收入的期望值也不高:5-10年工作经验的记者,期望的年薪中位数是4.2万美元(约26万人民币)。Payscale的数据也显示,全美记者的年薪范围大概在2.2万到7万美元之间(约13万到43万人民币)。在有“西方报业老大”之誉的《纽约时报》做记者,入职年薪是7.5万美金(约46万人民币),待遇之优厚居全美各报之首,比默多克在美国的旗舰报纸《纽约邮报》(NewYork Post)的记者收入高一倍,是美国收入最高的中文报纸《世界日报》的3倍,更是《侨报》等大部分中文报纸的5倍。
根据职业点评与招聘网站Glassdoor的数据,截止2015年6月15日,美国记者的平均年薪为53199美元(约33万人民币),纽约记者的年薪略高一些,平均年薪为56890美元(约35万人民币)。
英国
小编独家消息,在英国《每日邮报》(DailyMail)做记者,起步年薪为18000英镑(约17万人民币)。这样的工资在伦敦生活真是捉襟见肘。而根据英国全国记者联盟的统计,英国记者年平均工资约为2.45万英镑(约23万人民币),这让很多普通人家的子女因考虑收入问题被迫放弃新闻行业。
根据英国国家记者培训理事会(National
Council for
the Training ofJournalists)在2013年公布的调查结果,在一家普通报社工作的记者,年平均工资为22250英镑(约21万人民币),而且地方报纸和全国报纸的记者收入差距很大。实习记者平均每年12000到15000英镑(约11万到14万人民币)。年龄在24岁以下的记者平均工资为17500英镑(约17万人民币)。在英国做记者,工资和工作年限有比较大的关系。拥有五年工作经验的记者,年薪平均为25000英镑(约24万人民币),而从业十年或者更久的资深记者,年薪可达35000到40000英镑(约34万到38万人民币)。
这份调查还指出,不同媒体的记者也有不同的平均薪资水平:
另一方面,从事新闻行业的英国人里有94%是白种人,65%的新媒体人来自“中产家庭”。每周工作时间平均50到60小时,平均每周工作39.4小时,比英国平均工作时间多33.1%。男性新闻工作者平均比女性赚得多,男性平均年薪为35000英镑(约34万人民币),女性则有27500英镑(约26万人民币)。
日本
说起日本的新闻工作者,他们的工作内容和工作量可以用“激务”来形容,所以他们的收入也是与之成正比。其次,日本新闻记者的收入也与年龄有关,综合下来日本新闻记者的工资远远高于一般的工薪阶层。
处于高收入圈的《朝日新闻》,25至30岁的记者的年收入为1000万日元(约50万人民币),30~40岁的为1200万日元(约60万人民币),40~50岁的则为1300万至1400万日元(约65万至70万人民币)。《朝日新闻》、《读卖新闻》和《日本经济新闻》的工资大致相等,《每日新闻》和《产经新闻》为其一半左右,共同社则为8至9成水平。
但因为日本经济持续不景气,虽然记者的工资有所下降,但比起其他工薪阶层,其收入之高还是另其他行业望洋兴叹。
印度
作为新兴市场之一,印度记者的收入总体来说不算高,而且差距巨大。根据职业评价网站payscals在今年7月1日发布的数据,印度记者的最低年薪为118089卢比(约1.1万人民币),最高年薪高达912901卢比(约8.9万人民币),加上各种奖金,一年到头赚的最多的记者有943592卢比(约9.2万人民币),几乎是收入最少记者的9倍。
中国
根据《2014中国新闻业年度观察报告》,中国新闻记者的平均年龄为32岁,男女比例基本持平,平均年薪为8.4万人民币,九成以上的记者月收入低于10000元,其中47.7%的人月收入在5000元以下,44.3%的人月收入在5001-10000元之间,只有7%的人月收入在10001-15000元之间,而月收入15001元以上的记者只有1%。
对于网络记者,他们平均月收入为4000元,40.3%的从业者月薪低于4000元。这部分人中女性占了多数,呈现出非常明显的年轻化、高学历特征,平均年龄为29.1岁,95.1%以上拥有本科以上学历。近四成接受过专业的新闻传播教育,但六成多来自其他专业。看完了以上这些,小编汇总一下以上5个国家记者年薪情况。
究竟要不要当记者,以及要去哪里成为名“记”,名利双收,相信大家都有自己的判断啦。
【本刊原创,未经《华闻周刊》授权请勿转载】
http://card.weibo.com/article/h5/s?from=groupmessage&isappinstalled=0#cid=1001643867932701640751&vid=1652355141&extparam=&from=&wm=0&ip=183.159.75.20
作者: 殷玉鑫 时间: 2015-7-26 20:14
【案例】王琼:数据新闻不是你想的那样
数据新闻一定要用大数据?数据新闻一定要可视化?数据新闻建立在隐私挖掘上?三个答案任何一个你选了,是,都有必要看完全文。
文/翁逸骎
王琼:武汉大学新闻与传播学院广播电视新闻系教师,武汉大学镝次元数据传媒实验室筹建人。武汉大学镝次元数据传媒实验室筹建于2014年10月,尽管核心团队只有15人,但已经完成了数个微信刷屏的产品,最近的一次是与搜狐传媒合作的"毕业生去向调查"。
珞珈山下镝次元
传媒狐:能首先介绍一下"武大镝次元数据传媒实验室"吗?
王琼:武汉大学镝次元数据传媒实验室(Dy Data MediaLab, DDML)是一个以"数据新闻"为核心,融合新闻学、信息学、统计学、计算机科学、艺术设计、管理学等学科的跨领域创新性研究团体。
传媒狐:为什么叫"镝次元"?
王琼:镝是一种银白色的金属,可以提供高感光照明。我们的口号是"镝次元,用数据洞察世界,行在光明处"。希望做的事情能提供一个平台,以数据的角度和方式解读世界、透视社会。
传媒狐:实验室的人员构成是怎样的?
王琼:核心的团队15人左右。还有一些合作方,比如武汉大学师生和顾问。比如美国IRE(Investigative Reporters and Editors调查记者与编辑协会)的学术顾问 David Herzog,还有一位华人统计学家胡善庆老师,他是美国"百人会"的华盛顿地区的主席,是我们的统计科学顾问。所以我们也有这些社会合作的资源为我们提供智囊的支持。具体的执行就是以本校师生为主。
传媒狐:现在除了作品还有哪些研究方面的工作?
王琼:试验室的工作分为理论研究和业务实践两个部分。理论研究的成果主要是在学术期刊或会议发表,一般成果周期比较长。业务实践则有三部分内容:微信公众号(大数据新闻 id: datajouranlism)、在线沙龙和一些实验性作品的研发。微信公众号发布我们撰写或从国外获得版权编译的关于数据新闻前沿的文章。每两周一次会组织一次围绕数据新闻的在线沙龙,嘉宾是来自国内外的数据新闻领域比较前沿的学者和从业者,这个沙龙也得到了武汉大学新闻与传播学试验教学基地项目的资助。在国际合作方面,我们欧洲新闻中心合作有出版物。有一本叫《Verification Handbook》的手册,讲的是在数据时代如何核实新闻的真实性,这本手册我们已经和他们合作翻译完成了,正在处理后续的事宜。同时也会做一些实验性的新闻作品,大概一个月一个。希望在形式上、内容上有一些创新性。
数据新闻得按规矩来
传媒狐:有人说,大数据卖的就是隐私,在隐私和研究(报道)之间,如何平衡?如何保护数据的安全?
王琼:不论是数据新闻还是传统新闻,都是要尊重隐私的,并不会因为进入数据时代而有所变化,数据新闻也是要尊重个人隐私的。数据新闻的更大的意义是从数据中发现规律,或者是反常规的个例,而不是在挖掘个人隐私。数据新闻应该建立在基本的新闻伦理和道德基础之上。
传媒狐:对于现有的大数据交易(大数据交易平台、贵阳大数据交易中心)有怎样的看法?
王琼:很多媒体、机构和个人并不具备处理大数据的能力。大数据的概念首先需要搞清楚,体量非常大的数据才是大数据。大数据里面可能会挖出很多有价值的东西,但不是必须掌握大数据才能做数据新闻。
传媒狐:在做大数据新闻的时候,如何把新闻的时效性和长期的大数据分析联系起来?
王琼:这个其实是一个问题,很多大数据不在媒体手中,而是在科技公司手中,所以只能通过与科技公司合作,结合自己的长处——对新闻价值的判断、叙事框架的选择,沿着这个角度去寻找,不能漫无目的地在大数据当中找新闻。
可视化?只是工具而已
传媒狐:数据新闻和可视化新闻有什么关系?H5技术对数据新闻是否有帮助?
王琼:数据新闻不一定要把数据进行可视化。可视化其实是给我们提供了一种复杂叙事的可能性,在相对比较小的篇幅当中可以传播很多层结构的、复杂的、体量比较大的信息。所以可视化只是一个工具。H5和数据新闻没什么太大的关系,普通的新闻也可以通过H5来制作。现在的报道中常常用到很多大体量的数据,所以会需要用可视化的技术。
传媒狐:有没有观盲目使用可视化的现象?
王琼:从去年到今年早些时候还是有一些这样的现象的,大家把注意力过度放在可视化上。现在情况已经慢慢在好转。可视化作为新闻表现手段的选择之一,大家对它的使用已经越来越理性了。
狐sir推荐——做数据新闻的人啊,这6条得看一眼
1.学会获取数据——数据库啊……各个组织机构公司的报告啊……不行的话可以发邮件打电话或者跑到人家门口去要嘛!
2.学会筛选数据——处理过的数据虽然简洁,但自己处理的数据能让数据更贴近你的报道。
3.学会描述数据——数据是死的,表达方式是活的,你可以用文字用图片用视频用……切记,用最合适的方式!
4.仔细——首先,要保证数据的准确性。如果核对完发现数据还是有问题?恭喜你找到新闻了!
5.记得分享数据——你有个一个苹果,我有一个苹果,换一换还是只有一个苹果。你有一堆数据,我有一堆数据,交换并且处理以后 = 新的信息和可能的新闻点。
6.底线——如果数据涉及隐私,请妥善保护,这不仅是数据新闻的要求,也是新闻的要求,也是做人的基本准则。
来源:搜狐传媒 作者:翁逸骎
http://media.sohu.com/20150723/n417351979.shtml
作者: 张译允 时间: 2015-9-14 23:17
本帖最后由 张译允 于 2015-9-14 23:19 编辑
【案例】学业导航|【干货】数据新闻大咖带你探索数据可视化

沈浩:“数据新闻是从数据发现事实的报道,它的核心是可视化。”
[中国传媒大学教授、调查统计研究所所长、大数据挖掘与社会计算实验室主任]
file:///http://mmbiz.qpic.cn/mmbiz/d1pz3kwyiaanjmskbicx1hbnhtqrqgutakmibsalpsxqicgufjul2oakldceob0b71dsfbzv45jxeqwc100ibp5cwqw/640?wx_fmt=jpeg&tp=webp&wxfrom=5&wx_lazy=1
沈浩老师认为,人是一种视觉动物,可以感知世界,除了上帝,所有人都得用数据说话。并且形式大于内容,在你有内容有思想的前提下,数据可视化就成为了一种数据分析、一种叙事手段和一种批判思维,它可以指导人们更加清晰、准确、快捷地了解这个世界。
So,
现在让我们来看一些数据
file:///http://mmbiz.qpic.cn/mmbiz/d1pz3kwyiaanjmskbicx1hbnhtqrqgutaksbvfukyymcjc0yo1ab2ojoxwaiciapfo7upoysqsgynp5icskgi2eu70g/640?wx_fmt=jpeg&tp=webp&wxfrom=5&wx_lazy=1
告诉我,第一时间你都看出了什么。是不是跟小编一样满眼都是文字,根本不知道它们在表达些什么?
那么,如果把它换成一张图,是不是就清楚了很多?
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
图片来源:网易新闻
瞧,这就是可视化的魅力。
可视分析—让数据触手可及袁晓如:“可视化不是漂亮的图片,它首先是具有功能性的。脱离功能性,可视化无从谈起。”
[北京大学研究员、信息学院信息科学中心副主任]
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
可视化其实是对事物建立心理模型的过程,是完完全全发生在人脑的认知过程,人们观察数据,进而在大脑里形成图形,从而降低了用户认识对象的壁垒,使用户更好地认知外在世界。
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
人们得到所需要的数据,经过可视化处理后转化为直观、易懂的图片,使受众能快速了解你所需要传达的信息的过程,就是可视化。
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
图片来源:中国新闻网
乍一看,这张布满了橙红色和蓝色光点的地图像是城市夜景图,但实际上,它是一张体现社交网络使用状况的地图。其中橙红色光点代表图片分享网站“Flickr”的用户分布;蓝色光点则表示社交网站“推特”用户分布。白色光点则表示同时使用这两种网站的用户分布情况。
一个数据新闻的诞生黄志敏:“科学可视化、信息可视化、可视化分析。”
[财新传媒首席技术官、财新数据可视化实验室负责人]
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
黄志敏讲师认为,科学可视化、信息可视化和可视化分析,这三个称为可视化,把可视化和精确新闻报道结合在一起,并称为数字新闻。
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
BUT!!到底如何用代码呈现图形呢?不会代码的我们,又该如何是好?且听 赵佳峰老师 为你传道授业解惑!
不懂代码,我们如何做新闻赵佳峰:“调试工作是要确保绝大多数用户在各种环境都能顺畅地使用我们的产品。”
[澎湃新闻数据总监]
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
赵老师并不是专业的编码人员,但他认为只有前期准备做得充分,后面的工作才能有条不紊地顺利推行下去。
对于并不会代码制图的我们,赵老师也推荐了几款“大牛”软件。利用它们进行可视图的前期制作,后期再从头到尾、里里外外认真检查一遍,消除细节毛病,才能把一个相对完整的作品呈献给广大用户。
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
媒体变革·技术先行祖明:“媒体的发展史上,技术起到了非常重要的作用。”
[百度ECHARTS产品经理]
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
互联网使媒体的内容形式、载体、传播路径、内容生产者以及内容消费者习惯都发生了很大的变化。我们可以利用数据和WEB技术,提供更具吸引力、可读性的数据新闻产品。
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
图片来源:百度迁徙
百度迁徙则是业界首个以“人群迁徙”为主题的大数据可视化项目。
为什么数据可视化是一个“谎言黄骞:“可视化的本质就是简介,千言万语不如一张图。”
[超图软件统计事业部技术总监]
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
“在这个时代里,我们最不需要数据的展示,而是需要数据的隐藏。”黄骞老师说,“技术的发展,在使用方便的同时,也扩张了我们过度使用技术、表达自我的欲望。”
但到底应该如何缩减我们的表达欲、如何让信息呈现得更加清楚明了、如何提高对话的效率呢?
黄骞老师教会了我们一个万古不变的可视化准则,
即:
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
建立一座和城市一样大的图书馆费俊:“建造一个城市博物馆,一个像城市一样的博物馆,一个没有院墙的博物馆,一个必须去实地感受的博物馆。”
[中央美院教授、某集体交互媒体首席创意总监]
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
初次听到费老师提到的这个设想,小编我也是大吃一惊。
建立一座和城市一样大的博物馆?这简直是不可能完成的事情嘛。
可随着费老师讲解的深入,我发现这个把虚拟世界和实体世界关联在一起的、看似是乌托邦式的庞大工程已经被完成了不少。费俊老师认为,城市博物馆是一个城市记忆的共同体,通过这样的数字手段,可以使它成为公众和个人记忆的一种保存方式。
小编很期待这个APP能尽快上线,这样就可以与大家一起在其中明了我国历史的上下文和它所承载的城市肌理。
用代码与世界对话任远:“人类等于SCIENCE,人类社会发展也将是新技术不断变革的过程。”
[财新数据可视化实验室执行总监]
file:///data:image/png;base64,ivborw0kggoaaaansuheugaaaaeaaaabcaiaaacqd1peaaaagxrfwhrtb2z0d2fyzqbbzg9izsbjbwfnzvjlywr5ccllpaaaaybpvfh0we1momnvbs5hzg9izs54bxaaaaaaadw/ehbhy2tldcbizwdpbj0i77u/iibpzd0ivzvnme1wq2voauh6cmvtek5uy3pryzlkij8+idx4onhtcg1ldgegeg1sbnm6ed0iywrvymu6bnm6bwv0ys8iihg6eg1wdgs9ikfkb2jlifhnucbdb3jliduumc1jmdywidyxljezndc3nywgmjaxmc8wmi8xmi0xnzozmjowmcagicagicagij4gphjkzjpsreygeg1sbnm6cmrmpsjodhrwoi8vd3d3lnczlm9yzy8xotk5lzaylziylxjkzi1zew50yxgtbnmjij4gphjkzjpezxnjcmlwdglvbibyzgy6ywjvdxq9iiigeg1sbnm6eg1wpsjodhrwoi8vbnmuywrvymuuy29tl3hhcc8xljaviib4bwxuczp4bxbntt0iahr0cdovl25zlmfkb2jllmnvbs94yxavms4wl21tlyigeg1sbnm6c3rszwy9imh0dha6ly9ucy5hzg9izs5jb20vegfwlzeumc9zvhlwzs9szxnvdxjjzvjlzimiihhtcdpdcmvhdg9yvg9vbd0iqwrvymugughvdg9zag9wientnsbxaw5kb3dziib4bxbnttpjbnn0yw5jzulepsj4bxauawlkokjdqza1mtvgnke2mjexrtrbrjezodvcm0q0nevfmjfbiib4bxbnttpeb2n1bwvudelepsj4bxauzglkokjdqza1mtywnke2mjexrtrbrjezodvcm0q0nevfmjfbij4gphhtce1nokrlcml2zwrgcm9tihn0umvmomluc3rhbmnlsuq9inhtcc5pawq6qkndmduxnuq2qtyymtffnefgmtm4nuizrdq0ruuymueiihn0umvmomrvy3vtzw50suq9inhtcc5kawq6qkndmduxnuu2qtyymtffnefgmtm4nuizrdq0ruuymueilz4gpc9yzgy6rgvzy3jpchrpb24+idwvcmrmoljerj4gpc94onhtcg1ldge+idw/ehbhy2tldcblbmq9iniipz6p+a6faaaad0leqvr42mj89/y1qiabaawxasgvs/hwaaaaaelftksuqmcc
通过这次的讲座,任远老师已然成为我们的新晋男神。“用创意编程表达自己、探索世界”是任远的座右铭。在他看来,是创意编程的实验让他学会思考问题的本质,并给予他探索未来的激情。
席间,男神播放了几个由他制作的音乐可视化视频和可视化交互游戏,看得小编那叫一个热血沸腾,恨不得立刻投身于创意编程这个有趣而又伟大的行业中。
http://www.longxin.swust.edu.cn/forum.php?mod=post&action=reply&fid=36&tid=6122
作者: 杨静芝 时间: 2015-11-9 22:47
本帖最后由 杨静芝 于 2015-11-9 23:10 编辑
哥伦比亚大学数字新闻专家:新闻消费正经历两种根本性变化
2015-11-09Sarah 等话媒糖
手机和社会化新闻的崛起给新闻业带来巨大冲击,那么现在的新闻业界,谁控制了新闻传播渠道?内容提供商如何应对社交媒体的崛起?社交媒体如何发布新闻?移动新闻、社交新闻与新闻事业的未来怎样?问题太多,怎么破?下面请跟小糖看看哥伦比亚大学新闻学院教授、数字新闻中心主任艾米丽·贝尔如何说。
在全球范围内,新闻消费观正经历着两种根本性的变化。一种是越来越多的人选择手机和移动设备获取新闻;另一种是越来越多的人通过Facebook, YouTube,Snapchat,WhatsApp或者Twitter这样的社交媒体阅读或观看新闻。以上两种变化并不仅仅局限于美国或局部地区,而是正在全球上演。
这些变化的重要性关键在于变化的速度之快,对新闻机构所造成的影响之深刻。十年前,当普通大众有权使用发布工具时,“谁是记者?”这个问题就产生了;而现在,“谁是记者?”被“谁是内容提供商?”所替代。在协议网站Twitter、社交平台Facebook之后又出现了通讯服务应用程序,例如:WhatsApp ( Facebook的旗下软件)和Snapchat。现在新闻机构已经意识到为了吸引读者,尤其是年轻人,他们不得不利用这些平台发布新闻。
这些变化总体来说改变了新闻生产方式。也许最先有这种“新型新闻机构”想法的要数美国新闻聚合网站Buzzfeed,该公司已成功筹得7千多万美元的风险投资基金,并在一个月内迅速成长为一个可以跟许多老牌新闻机构相抗衡的企业。Buzzfeed坚信社交网络将成为主要的新闻发布渠道。它深知社交媒体是如何传播新闻的,更清楚新闻在即时社交网络上的传播模式。在这两方面,Buzzfeed公司具有专业化技能。Buzzfeed不在乎自己的主页是否吸引人,因为它并不期待网民把它作为目标站点来访问,而是让人们通过订阅推送来获取信息。
平台机构将掌控新闻传播渠道Buzzfeed的策略已被许多传统媒体效仿,如果这种策略正确的话,那么控制传播渠道的将不再是新闻发布机构而是新闻传播平台。在2014年路透纪念演讲会上,Emily Bell以一种新的范式阐述了诞生于硅谷的社交媒体公司、新闻内容提供商以及记者之间的新型关系。如今新闻自由被那些并不致力于维护公共话语权和民主建设的公司所控制。虽然现在记者可以接触比以往更多的受众,但是他们却无法决定新闻如何传播。
Facebook并没有把自己看作一个内容提供商,而是仅仅看作一个平台。然而一旦成为世界头条,它便要承担出版方面的责任。最明显的例子就是Facebook借助一种推算法决定应该给用户推送什么新闻。如果Facebook只推朋友和家人推荐的新闻,那么用户可能会错过重大事件。Facebook的新闻推算法是否考虑到其他因素呢,比如新闻事件发生的时间?是否担心过用户传播的新闻是否真实?是否排除了那些带有偏见或误导性的新闻?是否想过给我们先展示视频新闻,再展示文字新闻?这其中的每一个决策都意味着新闻推算法需要重编程序。Facebook可能会把这看作是一个技术问题,但是这些简单的决策同时也是一个编辑问题。
Facebook的影响力不仅仅是作为一个社交平台,事实上它已经革新了整个新闻业。未来,我们将看到更多新闻机构雇用那些只在并且直接在社交网站做报道的记者。到那时,如果雇用更多编辑人员,比如Facebook执行编辑功能的内容管理者,可以给科技公司带来经济利益的话,我们可能会看到社交媒体公司更加有意识地拓展自己的编辑角色。
新闻控制权 or 赢得更多受众:内容提供商如何应对社交媒体的崛起?
智能手机的崛起引发了新闻业的这一发展趋势,这种趋势不会在短期内停止,更不会向着相反的方向发展。新闻机构正纠结于如何回应这一趋势,尤其是在没有任何测量方法和技术解决方案的情况下,而这些方法和技术或许只有硅谷才能创造出来。2015年初,facebook与出版社做了一个实验,即将文章或视频的全部内容都展现出来而不只是提供一个链接。这一实验的理论基础是,外部网站链接会影响新闻传播速度。
更让人感到意外的是,像《纽约时报》这样的老牌新闻媒体竟然也签署协议,成为第一家接受测试的新闻机构(其他一些新闻机构则表示已经了解但拒绝参与,大多数则并没有受邀)。一家如此注重新闻控制权的媒体竟然这么做,由此可见即使你再有个性也会因为受众行为的改变不得不让步,这是每个内容提供商都必须做的一个决定。新闻控制权 or 赢得更多受众,这个抉择对任何本土新闻媒体和跨国传媒来说都是不可避免的。
新闻碎片化削弱了新闻机构讨价还价的能力,但却增强了网络平台的集聚能力。现在唯一的问题就是传统新闻传播模式转变为新型新闻传播模式还要多久?
社交媒体如何发布新闻?社交媒体的内部结构和编码是高度商业机密,这导致社交媒体如何发布新闻这一难题变得更加复杂。谷歌,Facebook和Twitter的盈利方式就是通过提供数据来满足广告主和用户的需求。如果我们能掌握他们的秘诀,他们就会失去竞争优势或者他们的方法会被某些不择手段的第三方copy。
新闻制作和消费方面的数据一旦丢失或被泄露,将会给内容提供商带来商业难题,甚至给大众造成更多问题。欧洲媒介环境处于高度管制状态,即使在美国,商业广播公司也必须经过许可方可经营。相比之下,大部分有影响力的硅谷公司反而没有被美国传媒法规的影响(尽管他们受版权,专利等方面法规的束缚),甚至在欧洲和其他地方极力规避新闻法规。
新闻碎片化意味着我们根本无法确定哪些是新闻媒体,更谈不上监督新闻公正与平等是否得以体现,我们再也不能确定哪些事件是被有意夸大或者故意压制。社交媒体和其它掌控信息渠道的技术公司(例如苹果公司的App Store)已经出乎意料地成为全球新闻传播的主导力量,而我们却还在为如何对待这一新格局抓耳挠腮。
移动新闻、社交新闻与新闻事业的未来在寻找受众上,新闻行业对社交媒体的依赖程度越来越高,新闻内容提供商被迫重新审视自己的商业模式与未来发展战略。如果一家新闻机构想在互联网上吸引大量受众,除了与社交媒体合作以外,别无选择,但这会使新闻业未来的盈利模式与决策权置于软件公司的掌控之下。
Facebook及其他社交媒体是否将成为新闻传播机构?新闻公司是否应该创建属于自己的技术?在提高新闻透明度的过程中,原有的规则秩序能否发挥重要作用?这些都是非常重要的问题。我想,无论如何,至少部分答案是肯定的。
对受众而言,他们有太多理由去支持新的传播环境。实时传播符合大众需求,社交网络极大地扩展了人们获取信息与新闻的权利。但是,当传播渠道被大部分美国社交媒体掌握后,大众到底会受到什么影响,这个问题尚无定论。了解以上趋势的影响不仅是一个重要的商业问题,更是一个重大的政治问题。
又一个新闻发展阶段已经到来。在部分地区和年轻人中,类似WhatsApp这样的通讯服务应用程序比Facebook等社交媒体发展的还要迅速,但是这些社会化平台只是未来传播环境中可能消失的,现在新闻业发展所依赖的助推器。
传统媒体和新媒体必须认清未来,或者趁势发展移动新闻,或者接受现实。十年前,新闻业从纸媒向数字化转型被认为是一个痛苦的过程,而现在却不得不做出更大的调整。那些仍把自己看作一个平台并意图逃避新闻出版责任的社会化平台也意识到这种思想是站不住脚的。
接下来新闻业的重塑将超出我们的想象,对消费者来说,这或许是一个好消息,不过对于大众与民主建设来说,还有待观察。
http://mp.weixin.qq.com/s?__biz=MzAwOTcxNTMyNw==&mid=400410021&idx=1&sn=80e234db570ec8b85b4bb8df468b57ee&scene=2&srcid=1109O3KC7yivFSsJ3jLKFWx5&from=timeline&isappinstalled=0#wechat_redirect
搜索
作者: 张熹 时间: 2016-1-1 22:21
【案例】涂子沛:一切皆因数据!很少有人把大数据讲得如此透彻
2016-01-01 数据观
编者按
2015年11月22日上午,大数据专家、阿里巴巴集团副总裁涂子沛在和君下沉庭院会议室为和君商学院学子作了一场题为《解读互联网+:云、大数据和新的商业模式》的演讲。此次演讲属于和君商学2015年24节气小雪讲座系列,深受听众好评。
涂子沛被公认为“中国大数据第一人”,留美经历使他视野开阔、思维先进。他的第一本著作《大数据》开中国社会大数据之先河,引发社会对大数据战略、数据治国和开放数据的讨论。第二本著作《数据之巅》展现美国数据文化形成、数据技术兴起、数据治国理念深入人心的历史,提出当前信息技术的发展已经让中国获得后发优势。
在这次演讲中,涂子沛提出:传统企业和互联网企业最本质的区别就在于数据化。互联网公司之间的竞争说白了就是数据竞争……种种金句俯拾皆是。总之,在涂子沛的眼中,一切都可以变成数据,一切变化都是因为数据。
在国内外互联网领先公司纷纷“进攻”大数据、云计算时,很多传统企业家还摸不清究竟何为“互联网+”、“大数据”、“云”。
起步已晚,来者可追。看完这篇演讲,是否能给企业“互联网+”改造带来启发?
(以下为整理的深度长文,全文共六大版块;
本次演讲文字整理:和君商学-齐全)
涂子沛:很高兴今天能和大家分享,来到这里看到这么多同学感到很温暖,同学的眼神完全不一样的,我进来就能识别这种眼神。这让我想起十五年前,和大家一样在周末去参加培训。但有点区别,你们参加的是商业培训,我参加的是在职公共管理培训,因为当时我是一名政府官员。现在我还记得国家招收第一届公共管理硕士,手拿招生通告逐条对比报考条件我都符合,非常激动。今天回头看,我想说是:学习改变命运。后来我如愿以偿去中山大学读在职硕士,三年都是周末上课,没有大家幸福,因为南方没有暖气,冬天教室阴冷无比。我当时从来没有想过去美国,更没有想到会著书立说,就想完成硕士课程,做好一名公共管理者得到晋升。就在这个课堂上,我的人生发生了180°转弯。
这个转折源于一件小事。有一天晚上,一位教授打电话给我,他说:“子沛,我明天需要做一个案例分析,你能配合一下我做个PPT吗?”那门课是公共政策分析,我至今记得PPT是分析美国煤矿政策演变。我说可以。这时是周五晚上11点钟,我用了4个小时做到凌晨。第二天我上台给大家做了一个案例分享,结果给这位教授留下了非常深刻的印象,他对我说:“我觉得你应该去美国。”去美国哪里呢?他帮我选好了,是哈佛大学的肯尼迪政府学院。我从来没有想过去美国,这是我第一次听到。从那以后,教授就不停地告诉我:你应该去美国。我当时一心想着去当处长。后来我慢慢发现他给我提供了一个很大的视角,如果去肯尼迪政府学院,整个人生可能完全不同,因为不知道end day会在哪里。刚开始我不相信自己能去哈佛肯尼迪政府学院,教授一直鼓励我。他告诉我他成功地推荐过两个人去哈佛肯尼迪,然后把这两个人请过来跟我吃饭。吃完饭之后,我就发现他们也没有三头六臂,我应该也可以去,之后我整个人生就开始改变了。记得在美国,有一位老师在课堂上问我:“你为什么来美国?”我脱口而出:“全球化自己。”在那个课堂上,这个教授改变了我整个人生。
课前秀
1、学者非必为商 而商者必为学
我想把这句话送给企业界朋友:“学者非必为商,而商者必为学。”做学问的人不一定要从事商业,但是生意做得好的人一定要研究学问,而且是一辈子都在研究。这句话源自《荀子》中“学者非必为仕,而仕者必为学”,原义是读书人不一定都要做官,但为官者必须坚持学习以不负平生所学。如今面对商学院学子,我将此话稍作改动。
商业的成功不仅仅是凭运气、人脉,一样是凭修为、学养,需要研究问题,把握大势。研究问题的能力不是从天而来,而靠后天的修为。培根有一句话说:“人的天性犹如野生的花草,而后天的教育是不断去剪裁。”学习是一个终身的过程,如果你停止学习,其实你就停止进步。我现在最大的毛病就是行政工作很多,但是我还是要求自己,每天要有学习、思考、总结的时间,要不然就没有进步,也做不了一名好的商人。社会越来越尊重企业家,企业家为社会创造财富、提供就业机会和源源不断的动力,成为一位企业家是件很光荣的事情。
2、“互联网+”是超越互联
“互联网+”是一个很热的话题,有很多解释,最主流的解释是说互联网成为基础设施,它可以加外贸、教育、政府、金融……起初互联网最大的含义就是把机器跟机器互联起来,但今天远远不是。说“……+”的时候,我的一个想法是比它多,在超越它。事实上,互联的历史使命早就完成,我们今天在超越互联。
不管用到什么终端设备都能够连接起来,比如QQ上的消息微信上能收到,这是跨平台、跨设备的互联。阿里巴巴的“钉钉”把短信、微信、电话融会贯通到一起,界面和微信很相似。发一条短信给朋友,钉钉会记录朋友是看了还是没看。他看了之后没有采取行动怎么办?就可以“钉”他一下:把这条短信以电话的形式打到他手机上,接通电话,信息以语音的形式播放出来,确保他听到。这就叫“钉”,而且是免费的。
3、阿里巴巴捍卫了国家数据主权
2015年“双十一”交易额达912亿,创造了1秒钟14万笔成交量,我把它称为“数据之巅”(涂子沛曾出版一本书名叫《数据之巅》),全世界没有任何一个地方可以在一天之内累积这么多数据。马云说阿里巴巴表面上是卖东西,实际是在收集数据。网上传阿里巴巴的数据危及到国家安全。阿里巴巴的数据非但没有危及国家安全,反而是在保卫国家的数据安全。
当年阿里巴巴和eBay、亚马逊“打战”,把它们“打”出去。阿里巴巴占了中国业务的80%,而它们在中国市场的份额越来越少。假设当年阿里巴巴没有打赢它们,是它们占了80%,那接下来会发生什么事情?所有中国的消费数据就会累积在eBay、亚马逊上,最了解中国经济发展动态、中国人消费行为的就是奥巴马,不会是习近平。这些消费数据是笔财富,可以分析国民经济特点。从这个意义上来讲,正是阿里巴巴的努力把它们“赶出”了中国,把这些数据留在了中国,所以阿里巴巴是捍卫了国家数据主权。
数据化
数据化是传统企业和互联网企业的本质区别
“数据之巅”蕴藏了多少财富。如今开放生二胎,到底哪里的人会生二胎,想生二胎,统计部门不一定说得清楚。不仅是中国,全世界都一样,统计部门通过一层层行政渠道来收集数据。经济学说我们都是“利益人”,根据自己的利益来驱动来做事情。官员、数据收集者按照他们的想法上报数据,最终的数据和现实相差很远。但是在阿里巴巴的平台上,我们只要看一下哪个地区尿布的增长波动情况就可得知。不仅尿布,奶粉、婴幼儿用品可以形成立体的数据网络,最终得到的结论非常贴近现实。大数据可不是大,大数据是多源。从多个源头的数据去互相印证一个事实,这是“大”。
1、把消费者行为变成数据
如果没有电商,我们能不能创造数据之巅?上午去百货店买一个东西,下午再去,换了一个售货员不认识你。早上去一个柜台买一根项链,下午去另一个柜台买几盒奶粉,售货员也不认识你。在电商平台上,只要你去过一次,任何一笔交易,不仅仅是买,甚至是点击、浏览了一下,就被记录下来,你再来我就知道。随着消费不断的增多,我们看到你的消费规律,分析你的消费行为,进一步预测你需要什么。电商的数据化是把消费者行为变成数据。
2、科学指导备货
阿里巴巴每年为“双十一”要做很多的准备工作,保证平台上的商家能够成功,比如备货,备多了卖不完,第二天要继续打折;备少了,那这个活动就白举行了,人家下单你没东西给别人。“双十一”办了7年,因为这个原因阿里巴巴滋养了一大批电商网站,很多“双十一”卖不出的商品在这些电商平台上继续卖。如果让百货店卖912亿,1秒钟要完成14万笔交易,先别考虑百货店能不能容纳这么多车,它都不知道每个柜台该备多少货。我们通过一系列的数据化手段帮助商家管理库存:通过客户搜索、点击、浏览、开通预定,让商家分析到底该备多少货;通过查阅前几年的销售、价格弹性,商家把握好库存,这背后是一个数据驱动的过程。
3、准确找到客户
前两天我在飞机上看到的一条新闻《上周全国降温秋裤搜索指数暴增6118.8%》。天气变冷了,今年北京下雪特别早。淘宝上搜索秋裤的人上升了6000多个点,我们可以知道是哪些人在搜索,这些人在哪些地方,这代表商机。搜索皮衣的人也在增加,数据分析表明搜索皮衣的人一般都有汽车,我们把这两个现象结合起来去推送信息,提供个性化服务。
准确找到客户这是最难的。经济生活的本质是满足供和需的关系,供和需的关系都是以信息存在的,找到客户很关键。传统企业每晚把电商的数据扒下来分析哪些东西卖得好,卖了多少,然后马上传给自己的库存。小的电商把大的电商数据扒下来,用这个数据指导自己的库存。因为数据越大,趋势判断就越准确。
传统的企业怎么做营销呢?比如某电脑公司组织promotion event(促销活动),通常群发邮件通知营销活动在什么地点、什么时间,但这些都是已经买过它电脑的客户,或者派几个营销员在附件发传单。现在我们在网上找到最近搜索过电脑但是又没有买电脑的人,然后针对他们去做营销。我们做过实验,用传统方法只能卖1台,用我们这种方法可以卖10台,成交量增长10倍。
电商平台之所以能做这些本质原因在于所有的交易都在平台上变成数据了,当它们变成数据之后,事实上它们重现事件和商业行为。这些行为可以被分析,预测。数据表示的过去,但表达的是未来。所以阿里巴巴提了一句话:“一切业务数据化。”要把所有的业务过程变成数据,在数据上形成一个闭环。不仅仅商业业务,行政管理过程也要变成数据,全部变成数据。整个世界都在迈向数据化,我认为传统企业和互联网企业最本质的区别就在于数据化。如果一个企业把一切业务数据化做好了,那他今天就是一个互联网企业。今天的互联网不是“互联”,而是沉淀数据的战略基础设施。阿里巴巴和传统百货之间只有一点区别,就是阿里巴巴沉淀数据而传统百货没有。
什么是数据
今天所讲的数据可不是传统意义上的数据,此数据非彼数据,数据的内涵发生扩大。如果仅仅听故事不是学习,学习是把握事情的本质。只有把一件事情本质把握清楚了,知道它如何定义,你才深刻理解它。
1、数据的内涵发生扩大
“数据”是对客观世界的测量和记录。传统的数据是测量,比如测量气温把它变成数据。今天的数据爆炸不是测量数据的爆炸,是记录数据的爆炸。现在人们离不开手机,打开手机看微信朋友圈发的信息、图片、文字,这些是数据。所以我们不是离不开手机,事实上是离不开数据。
为什么数据的内涵不断扩大?原因在于另一个词——database(数据库)。这是一个外来词。数据库被发明之后,图片、文档、邮件……都存在数据库里。在西方,所有存在数据库里的东西都统称数据,然后才引起数据在中国内涵扩大,所有可以电子化的东西都可叫做数据。
所有的事情都在数据化,随着手机的普及,人人都有能力把自己的生活、所见所得变成数据。这引起很多社会变化,很多社会现象都可以由这个现象来解释。前段时间中央台某主持人由于在饭桌上不当的言论弄得自己很被动。在他说的时候,有人拿出手机录下来,变成数据,然后很快速地传播出去。其实可以推断以前他也经常这么说,但是没人记录变成数据。所以有段时间大家吃饭都把手机先交出来,才能随便说话。优衣库事件是在试衣间里把正在发生的事情变成数据传播出去。
2、我们走在数据的前沿
2015年双十一平台交易有68%是移动端交易,去年是40%多。美国这个比例远远低于中国,过两天就是美国Thanksgiving Day,就这个星期四,Black Friday是他们的shopping day。Black Friday是美国传统的“双十一”,第一个星期一叫电商打折日,所有的平台这两天加起来都不到中国一半。美国手机下单远远低于中国,而且中国的增速是美国的几倍。所以各位你们赶上了很好的时代,我们今天在数据领域面对的问题实际上是全球性问题,是世界前沿的问题。我们不能指望像十几年前美国在前面最先碰到提供解决方案,我们有一个缓冲。
阿里巴巴的上市代表着全世界开始关注中国,开始倾听中国的声音。马云先生前段时间说世界互联网公司第一梯队是四家公司——谷歌、Facebook、阿里巴巴、腾讯。一切关于数据的交易、伦理、风险、道德、隐私,我们碰到的问题跟他们是一样的。
3、数据的外部性使阿里巴巴变成一家金融公司
数据具有外部性。世界是普遍联系的,辩证法告诉我们,是千丝万缕互相关联的,所以可以从A现象推断B现象,数据不在于大,而在于多源。今天的事实就像个水晶体一样,来自四面八方的数据拼凑一个接近事实的画面。
阿里巴巴每卖一样东西平台上就留下一条数据。在2000年的时候,阿里巴巴累积了很多数据,突然发现这些数据可来做其他事情,比如金融。当时平台上有很多卖家,几百万、上千万卖家需要贷款,但是传统银行不给他们贷款,他们贷不到款或者很难贷到。平台上数据记录他们所有的营销情况,知道他们卖了多少,甚至推断他们赚了多少钱,掌握了他们的资质,知道他们是否稳定和波动情况,所以我们可以给他们发放贷款。贷款如何发放?我们开发100多个数据模型,3分钟填报贷款需求,1秒钟决定给不给他贷款。没有人决定就是算法,这个产品推出的时候叫阿里小贷,已经给100多万商家提供贷款。
阿里巴巴凭借数据的外部性从一个电商公司变成一个金融公司。数据之所以有用是因为数据的作用能够超出其最初收集者的目的。收集数据是为了这个目的,但事实上也可以用到其他维度上去,用到哪些维度上,你想都想不到。我们正在把阿里小贷扩大应用,原来是小微企业平台上的卖家,今天支付宝里都有芝麻信用分。芝麻信用分怎么给的?同样的道理,凭借数据。芝麻信用分好不好用?去租车、住酒店不要押金,因为你的信用分高;在机场可走快速通道,因为你的信用分高;去签证,可能资料不用提交,因为你的信用分高。信用在变成财富。
互联网金融就是把数据变成信用。金融领域的信用正在快速地数据化,今天信用就是数据,数据就是信用,跟人有关的一切的数据都可以变成信用。今天阿里巴巴很想和政府合作,政府有大量关于你的数据,如果我们得到这个数据,比如市民卡的数据,数据作为一个参数返回到我们的算法中来,可以给你的信用打个更精确的分。信用在全面的数据化,阿里小贷是中国互联网金融最早的探索。
Kabbage带来的三点启示
1、数据在资产化
几乎在相同的时刻,美国出现发放贷款的公司Kabbage。小微企业找到它要求贷款,Kabbage要求企业“提交”数据,提供企业ERP、财务、UPS账号。Kabbage登录这家公司财务系统的账号,把财务系统全部扫描一遍,判断能不能贷款;登录企业UPS账号,去查发了多少快递,收了多少快递,如果是皮包公司,一年可能只有几封快递。数据成为参数之后决定这家企业资质如何。
UPS是一家快递公司。它收集数据是为了更好地服务客户,方便客户查询跟踪物流信息,但UPS的数据在发挥新的作用。Kabbage即使拿到公司账号去UPS查数据,需要UPS同意授权甚至收费,这是一种商业行为。Kabbage最后是要付钱给UPS,按次、按月、按年我们不知道,但是可以得出结论:数据在资产化,凭借数据可以收费。
2、未来数据必须经用户授权使用
未来数据的使用都要经过用户授权。不要小看这句话,未来的变化、革命都蕴含在这句话里面。数据是由你而产生的,虽然是商业公司投资来收集这个数据,但是你才是这个数据的主体。今天很多公司都没有得到授权,未来是不是有些公司会不堪其重走不下去?今天是数据红利时代,每个人的数据红利被集中起来然后被消耗,但是大家没有意识到我们具有数据红利。数据是有价值的,是可以变现的,很多公司在做数据收集,经过个人授权,出钱购买个人数据。
杭州有家公司叫挖财,通过资金收集数据。用信用卡的人每一天都会受到信用卡的月结单,通过提供优惠券、打折券的方式收集月结单、消费数据。当它收集的足够多时候,就能看到一张更大的图,提供服务和咨询。比如A、B两家银行,A银行如果知道B银行的信用卡发给哪些群体,就知道自己该锁定哪些群体、商业策略。挖财就可以找到A银行,说你想知道B银行的情况吗?我可以告诉你。同样它也可以找到B银行说相同的话。它还可以为个人提供服务,看了个人银行消费情况,可以分析个人消费存在什么样的问题。
美国也有同样的公司,和挖财一样也不是用现金购买,而是提供每年三次免费查看个人信用报告机会。美国每次查信用报告需要70美元。这其实就是数据在资产化,但是要经过个人授权,这是我们未来5到10年即将会看到的变化。
3、为什么要上云?
这个例子还有第三个启示,就是要上云。企业找传统银行要求贷款,银行会派人去这个公司调查。调查本身就是收集数据,看财务报表、了解企业真实运行情况,最后形成一个数据报告,拿回去给银行决策层。银行决策层根据这个报告决定给不给他贷款。在这个过程当中,因为企业知道银行来调查,又想得到贷款,所以会有意无意提供虚假信息,甚至生造一套账本出来。总之,是“先有需求,后有数据”。
阿里巴巴平台上数据早就已经沉淀,企业的每一笔交易、经营情况都沉淀在平台上,然后企业要求贷款,这是“先有数据,后有需求”,而且这些数据是很客观,很真实的,所以阿里巴巴真正牛的地方就是1秒钟发放贷款。1秒钟发放贷款,传统银行永远办不到,传统银行需要几个星期、几个月、几个季度,很难有几天。更牛的是我们的坏账率远远低于传统银行。
数据都在企业本地,意味着Kabbage不能远程登录,要派人去本地查看数据,不能立刻做决定。如果有两套系统,无法保证看到的数据是真实的数据。这就是为什么要上云。云端可以7*24小时随时查看、整合,而且云是第三方,比如用的是微软的ERP、微软的财务报表、SAP系统,在这些第三方的云端,数据的真实性就解决了。
美国大多企业都在云端,而我们不是。云在中国最早的实践一定程度上也在阿里,最早淘宝门店在阿里上,服务器在自己家里。平时生意不好一台服务器就够了,过节的时候生意变好可能需要两台服务器,但为一年之内仅仅的几天买一台服务器又不合算,所以不愿意再买服务器。生意好的时候生意越做不下去,因为服务器崩溃。因此,阿里开发阿里云,商家租阿里云上的服务器。今天生意好分配两台,明天生意不好分配一台;生意好的时候付两台的钱,生意不好的时候付一台的钱。这样商家的数据就上传到云上了。
无论是中国还是美国,最早的云是为了节约成本产生的,小微企业不想买服务器,想租服务器。今天不仅仅是小微企业在上云,大的企业都在上云。云提供灵活性,数据在云上意味着7*24小时是活的数据,是可以融通的数据。在阿里云的平台上有家卖汽车票的公司叫12308,12305是卖火车票的。这家公司雄心很大,想把全国的汽车票放到一个平台上去卖。原来是在江西用自己的服务器,后来迁到阿里云上,前段时间搬到深圳去了。12308所有的基础架构全在云端,可以灵活搬迁。
上云有很多好处:
(1)数据在第三方,数据背书公众、客观、真实;
(2)数据7*24小时,随时可以被别人使用;
(3)异地可以查阅
互联网金融领域的创新核心就是云和大数据。大数据和云计算是一个硬币的两面,云是硬币背面。互联网金融是以云为基础的。
一切皆成数据
1、产业互联、人体互联将导致更大量级的数据爆炸
今天的数据已经铺天盖地,但还不是真正意义上的大数据。产业互联、人体互联将导致更大量级的数据爆炸。2020年,来自传感器的数据将占全部数据的50%。正在发生人体要联网,机器要联网,就是物联网。发微博、微信一天也许只发几条,智能手环每几秒钟就收集的心跳、体温、各种体能指标源源不断地传到云端。这两种爆炸量级完全不一样,即将要看到的爆炸才是超级爆炸,这种爆炸将把人类带入彻底的数据世界,一切皆成数据。
去年回国我看到一条新闻,一个游子在外打工,打电话回家没有人接电话,他很担心,放下手头的工作风尘仆仆赶回家里,一推开家门发现父亲心脏病突发猝死在地上,母亲瘫痪在床上活活饿死,这是个悲剧。如果智能手环戴在人的身上,最早发现这个人离开世界的是云和大数据。
无人驾驶飞机现在引起很多争议。美国最新的立法把它定义为远程遥控飞机,规定必须有一个人在背后遥控这台飞机。为了叫什么名字美国国会争了很久。无人机的nickname(绰号)叫“大黄蜂”,最早是为了执行军事任务,这个名字推到民用领域大家会警觉是不是侵占隐私。今天的企业家改名“无人驾驶飞机”。美国的军方和科学界认为叫“无人驾驶飞机”很愚蠢,就如汽车刚出现的时候叫“无马车”一样站不住脚,所以坚持叫远程遥控飞机。
阿里巴巴今年4月份的时候用无人驾驶飞机在北京送了一次货,亚马逊也在用无人驾驶飞机送货。用无人机送货噱头大过现实,只是展示这门技术,如果全部采用无人机送货将需要很多台无人机带来很多麻烦。佛山专门设立科室采用无人机收集证据,无人机最大的作用是收集数据。以前农场主用无人飞机航拍农场花费昂贵,现在一架无人飞机只要1000美元,农场主可以每天采集数据,软件自动对比,进行精细管理。电线是跨越高山、田野输送到偏远的地方,中国150万人人力检修电线是否老化需要更换,未来无人机飞行拍照即可。无人机的普及会带来空中数据爆炸,贴地十米飞行收集高精度数据,未来会颠覆Google卫星定位地图服务。
2、阿里面临的问题需要大数据来解决
阿里巴巴不是一家没有问题的公司,只是我们遇到的问题是前人没有碰到的问题,需要用技术手段一个一个去解决。平台就像高速公路,高速公路上有冒牌车,人们都要求关闭高速公路,这样不合适。造假折射的是一个社会问题,不是平台的问题。淘宝上造假、侵犯版权问题,可以开发机器识别图片;商品参加活动原来由小二决定,导致小二腐败,现在用数据分析自动分配决定哪些商品可以参加活动,无人工干预保证公平。
阿里巴巴现在服务3亿多客户,有2000多人在负责接电话提供客服,一天有几十万个电话打进来。未来要服务6-10亿客户,按正比算,需要四五千人接电话。目前很多客户在电话服务过程中会遇到“这不是我负责,我给你转到另外一个部门”的情况,经常需要重复讲述问题。之后,我们可以将语音变成文字,在客户说的时候就判断是什么问题,立刻转到负责人员。客户之前说的话全部转成文档调给负责人员,从而高效解决问题。阿里巴巴解决这些问题都离不开大数据。阿里巴巴不仅仅是电商公司、金融公司,还是家大数据公司,它用技术的手段拓宽商业的边界。
3、个性化是建立在源源不断的数据流之上
加拿大蒙特利尔市在2013年为120万市民提供个性化公共交通票价,每个人的票价都不相同,算法根据系统里累积十几年的数据来决定票价。这就是智能,人力无法完成,有数据的支持毫秒之间就可以完成。今天的商家都在推个性化服务,未来的个性化服务是基于数据流的个性化服务。客户源源不断地产生数据,商家根据数据来分析、预测提供服务。
手淘有3.5亿终端用户,要让每个用户打开手机淘宝看到的商品、新闻不一样,让用户看到的都是感兴趣的事物。人都处于信息过窄的局面,不感兴趣的信息根本不会打开,推行个性化服务之后这个效果要好5-10倍。每天打开手机淘宝的人的数量在不断上升,你越个性化,这个数量越上升。
互联网公司之间的竞争说白了就是数据竞争,首先有没有数据,第二点会不会用数据。如果收集不到数据或者数据断了,商家就不知道客户在想什么,要什么,就没有办法提供个性化服务。
4、新经济是以数据为基础的经济
我们面临的新的态势无论是叫知识经济,还是叫互联网经济、智慧经济,笼统地称为新经济,就是以数据为基础的经济。智能就是把重复性、常规性的、人无法完成的工作用机器去完成,智能的基础是把业务先变成数据,然后机器自动地去处理这些数据,用算法完成工作。没有数据,智能就无从谈起。大数据的标识是迈向智能社会,越来越多的工作会由算法代替,算法源于数据。今天所谈的人脸识别、工业制造4.0核心都是数据。目前阿里巴巴的业务还没有全部变成数据,还需要更加努力。
风雨交加、电闪雷鸣、镁光灯下发生的变化存在电影里,真实生活的变化是无声无息、不知不觉在身边发生的,需要细心去观察。我们有幸生在这样的一个时代,见证技术力量改变世界。原来很多社会资源是不可动、僵化的,互联网把越来愈多的社会资源盘活,产生更大的价值。时间、技能、智能、金钱在互联网的平台上可以自由地交换、整合、流动。这种盘活资源的能力是惊人的。
关于Uber网上有很多段子,有个人提前下班叫了Uber,一上车忐忑不安,再一看发现司机是自己的老板,也提前下班开Uber。几个月前我坐过一次Uber,让我大开眼界。一上车司机喋喋不休和我说话,我没有心思听他说话,因为我正在想出差的事情。对话慢慢变成个性化,司机问我:“涂先生,你知道我为什么来开Uber?”我心里想还能为什么呢?你有时间,有一部车,你想赚点外快。我没做声。他接着说:“我只接阿里巴巴门口的单,你到哪里能找到这样的机会可以和阿里巴巴的高管单独接触1个小时。花钱都买不到,可以跟他成为朋友,向他请教问题。”我一想对啊,确实是这样。所以开Uber的人抱着各种各样的目的。不排除有的司机只接女性的单,为了找到自己的另一半。司机可以选择性接单。人们怀着各种各样的目的在互联网上,亚当斯密的《国富论》曾说过,屠夫之所以卖肉,面包师之所以卖面包,都是为了自利,但是会有外利的效应。我们每天所需要的食物和饮料,不是出自屠夫、酿酒师或面包师的恩惠,而是出自他们利己的考虑。每一个人追求自己的利益,往往使他能比在真正出于本意的情况下更有效地促进社会的利益。自利的行为具有外部性,最后保证社会的资源盘得更活。所以亚当斯密说让市场的归市场,让市场自己调节。
互联网+一方面让经济活动的每一个领域信息变得更加对称,供需关系变得更加对称;另一方面,调动更多的资源,让资源流动产生价值。
开放数据
大数据不是矿藏,而是土壤,开放的数据即为土地上的河流,河流流过之处,就会孕育起发达的数据文明。矿藏、黄金是不可再生的,而土壤是再生的。数据可以重复使用,具有外部性。
去年8月份全球很多地方发生了月全食,无数人拿着手机对着月亮去拍照,苹果手机云当晚就收集到几亿张月全食照片。人们拍照时为了交流、分享和晒朋友圈,苹果公司请天文学家来看,天文学家惊呆了,世界上没有任何一个监测系统有这么强大,在同一个时间,在不同的角度、不同的地点把月亮记录下来,这些数据整合起来就有天文研究价值。
1、有些数据要开放
数据是迈向智能社会的土壤,而智能的基础是一切业务数据化。数据如此重要,要让数据流动起来,所以有些数据要开放。前段时间刷屏欧洲面包店公布不同天气情况下不同的销量特点,中国有些面包店也有数据化管理,但是天气情况数据没有开放,因此无法监测两者之间的关系。开放是天气的数据库放到互联网上,面包店老板下载天气数据和自己销售数据以整合,曲线就出来,很容易发现规律得出哪种面包在不同的天气卖得好还是卖得差,可以根据天气调整不同面包的产量。劳动生产率的竞争基本上走到尽头,今天就知识竞争,比的是知识生产率,发现顾客是数据驱动的。
最应该开放数据的是政府。纳税人供养政府,政府用纳税人的钱收集公共数据。天气、土地、人口、科研论文、实验结果这些公共数据都应该开放。数据开放可以盘活对内开放,《数据之巅》第六章详细地阐述了这个话题。今天谈这个话题不是着重与政治权利的问题,而是强调经济发展的问题。数据成为创新最重要的资源,推动知识经济、互联网经济、数据经济向前发展。
2、隐私怎么办?
大数据是柄双刃剑。保护隐私的核心就是保护自己的数据。数据在成为一种权利,数据成为隐私最大的载体。地下数据链条非常发达,快递员撕下快递单或者拍下来提交给另外的公司,可以得到每张都有2分钱的报酬。过去,我们选择记录什么;现在,我们选择不记录什么。
3、中国文化传统是轻逻辑和轻数据
中国是个差不多的民族,不追求精确,轻逻辑,轻数据,我们的文化传统对数据其实是不重视的。黄仁宇先生曾说:“中国仍然是亿万军民不能在数字上管理”,胡适先生也曾说过,中国最有名的先生是“差不多先生”。中国要在大数据时代的全球竞争中胜出,应该把大数据从科技符号提升成为文化符号,在全社会倡导数据文化和思维。《数据之巅》这本书的使命就是把数据从数字符号变成文化符号。
我的两本书《大数据》、《数据之巅》很多导演想把这本书改编成电影,在这个过程当中慢慢催生了我新的想法——做立足新科技、新知识、数据思维的中英双语自媒体,致力在世界上发出中国科技领域的声音。
谢谢大家!
https://mp.weixin.qq.com/s?__biz ... X+OSX+10.10.5+build(14F1505)&version=11020201&pass_ticket=cUIFSH4gnKW7LkRwIvWflw39mZljIjWfDuIESYSLv%2FZA%2FhClbZRpdnxrLVia1Eek
作者: 杨静芝 时间: 2016-3-29 23:00
信息爆炸时代,如何做数据新闻?
2016-03-29 MOOC学院
大数据越来越火,这对新闻行业来说意味着什么?
如何培养对数据的敏感,一眼从数据中看出重点信息?
在这个信息爆炸的时代,谁拥有数据,谁理解了数据,谁就能抢占先机。对于传统的新闻从业者来说,“数据新闻”是一次新的挑战,它改变了记者的工作方式,让记者可以用全新的、令人兴奋的方式报道新闻。
那么,新闻工作者该如何用好数据?来听听数据记者邱悦及数据新闻中文网联合创始人马金馨对数据新闻的独到见解!
讲座时间
4月1日(周五)20:00
分享嘉宾
邱悦,彭博通讯社数据和交互记者,毕业于哥伦比亚大学新闻系,曾先后就职于美国调查性新闻网站ProPublica和Center for Public Integrity,作品曾获ONA,SND等多个奖项,专注数据新闻、可视化设计、经济报道和调查性报道。她同时是数据新闻中文网的编辑和撰稿人。
金馨,《数据新闻基础》慕课课程统筹和讲师,数据新闻中文网(djchina.org)联合创始人、主编,多年来从事数据新闻培训,已培训数百名中国记者。她目前在泰国曼谷,是联合国开发计划署亚洲总部的创新传播与科技顾问。她曾担任汤森路透社数据新闻助理项目经理和香港《南华早报》社交媒体编辑。讲座内容数据新闻的五个W•What:什么是数据新闻?
•Why:为什么要做数据新闻?
•When:它是从何时开始的?
•Who:谁在做数据新闻?
•Where:在什么地方做数据新闻?
报名方式给MOOC学院公众号发送关键词“数据新闻”,按提示操作。
FAQ
Q1:微信沙龙在哪里听课?
A1:开课前,小天使会拉报名者进入分享群,采用微信群聊分享的形式,通过语音、文字等与听者互动。请进群之后修改群名片,格式:姓名+公司/学校Q2:为什么入群要实名认证/绑定银行卡?
A2:这是微信的规定哦,加入500人大群需要实名认证/绑定银行卡。
Q3:为什么我报了名,却没有被拉群?
A3:小天使每天会定期手动拉群,如果还没拉到您,请不要着急,我们一定会拉的!报名在讲座开始前两小时截止,不要太晚来哦。
Q4:入群之后能说话么,发广告吗?
A4:分享开始之前为禁言期,禁止广告与恶意刷屏行为,违者将会被小天使移除群聊。分享后会有导师答疑时间,大家可以提问与导师互动。
https://mp.weixin.qq.com/s?__biz ... DRJaqQTbvvu2IM9U#rd
作者: 万家凝 时间: 2016-8-8 22:23
【案例】
腾讯、网易、搜狐、头条等四大新闻客户端用户画像分析大数据 2016-07-28 15:03:51 [url=]阅读(99)[/url] 评论(1)
声明:本文由入驻搜狐公众平台的作者撰写,除搜狐官方账号外,观点仅代表作者本人,不代表搜狐立场。举报

本文由 易观智库(ID:enfodesk)授权发布,转载请注明。
主要内容中国移动新闻资讯应用市场发展现状
中国移动新闻资讯应用用户特征分析
新闻客户端用户特征差异分析
中国移动新闻资讯应用市场发展现状
新闻资讯领域表现突出,用户渗透率超过五成
从整体移动端各细分领域来看,即时通讯和社交网络的领域渗透率最为突出,分别为94.4%和93.4%;其次以综合视频为首的视频类领域,表现紧跟其后,新闻资讯以54.6%的领域渗透率排名第五。

新闻资讯领域活跃用户表现平稳,12月达到峰值
从千帆对独立APP的用户数据监测来看,新闻资讯领域在2015年的月活跃用户数表现较为平稳,其中在2015年12月份达到全年峰值,月活跃用户数达24735.2万人,环比增长率为3.6%。

12月为新闻资讯用户活跃最强月

8月为新闻资讯用户粘性最强月

中国移动新闻资讯应用用户特征分析
新闻资讯应用更偏重男性用户

中国移动新闻资讯应用用户群以年轻人为主体,在41岁以上人群中亦有相对较广覆盖
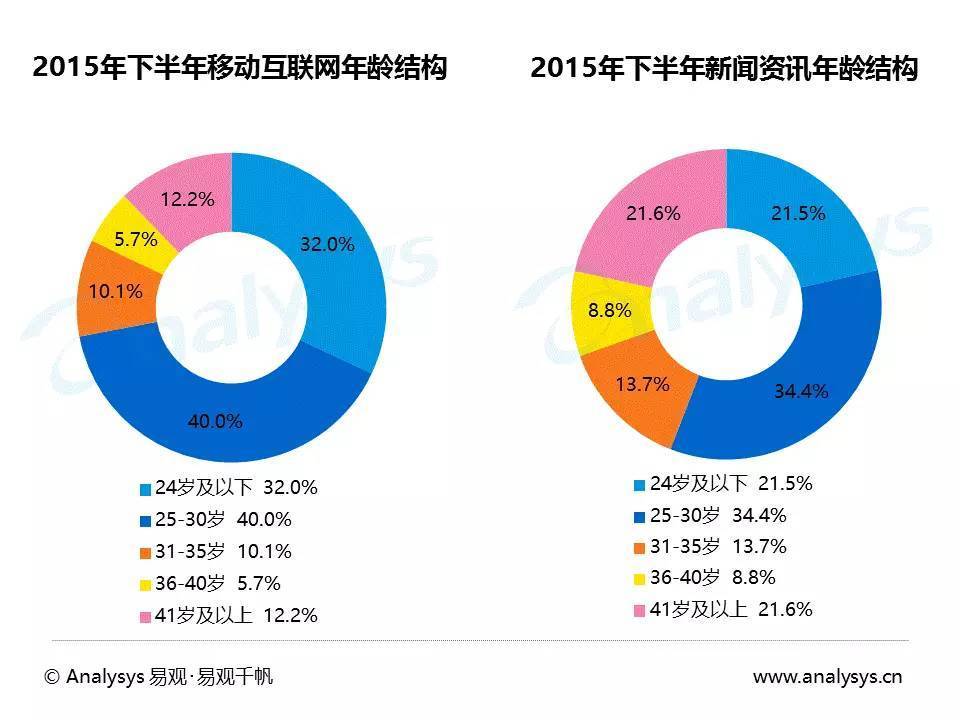
较移动互联网用户分布来看,新闻资讯用户在一线城市和地级市相对覆盖较高

新闻资讯应用用户群相对学历较高,大专及以上学历占比近4成

新闻资讯用户中自由职业者/业主占主导

新闻资讯应用用户群相对收入较高,呈中高收入特征

新闻客户端用户特征差异分析
新闻资讯行业格局稳定

从渗透率看,15年下半年新闻资讯行业格局稳定,腾讯新闻以其强大的用户覆盖率,位列第一,今日头条虽是后起之秀,但势头猛烈,网易新闻位列第四。
月度日均活跃用户数表现为整体稳步增长

月度活跃用户数表现为整体稳步增长,腾讯新闻的用户活跃度相对更好

腾讯新闻用户群性别更加均衡,网易用户群更加年轻化

网易新闻用户在地级市以上城市集中度较高,大专及以上的高学历用户占比亦较高

网易新闻用户白领相对更多,中高收入占比亦更高

今日头条在用户活跃度及粘度表现较好


四大新闻客户端各领域TGI特征值




注:此处的特征值即TGI(目标群体指数),计算方法以腾讯新闻的母婴领域为例,公式为(腾讯新闻用户关注母婴领域的用户占比/新闻资讯领域用户关注母婴领域的用户占比)*100,TGI高于100,表示腾讯新闻用户对母婴领域的关注度高于新闻资讯行业整体水平
各新闻客户端用户特征总结

研究范围及研究内容
研究范围
本报告的主要研究对象网易新闻客户端,同时还研究了新闻资讯行业处于领先地位的几大客户端的用户情况:腾讯新闻、今日头条、搜狐新闻等。
重点研究了网易在移动购物、金融、汽车、医疗健康、旅游、母婴等六大领域的用户特征。
研究内容
本报告的主要研究内容涉及中国新闻资讯市场现状、用户行为和特征分析,典型新闻客户端用户特征分析以及网易新闻客户端相关领域用户分析。
数据来源
数据主要来源为易观千帆2015年的监测数据(其中,网易新闻关键领域用户数据为2016年2月的数据),千帆只对独立APP中的用户数据进行监测统计,不包括APP之外的调用等行为产生的用户数据,截止2016年第1季度易观千帆拥有基于对7.5亿累计装机覆盖、1.5亿移动端月活跃用户的行为监测结果。
本报告中涉及的用户粘性主要依据用户对客户端的平均单日打开频次和平均单日使用时长(单位:分钟)判断。
近期精彩活动(直接点击查看):
http://mt.sohu.com/20160728/n461466462.shtml
作者: 万家凝 时间: 2016-8-23 01:00
【案例】
奥运收视率暴跌 美国最大电视台还能赚钱吗?
2016-08-22 08:16:43 来源: 第一财经日报(上海)举报
643(原标题:奥运收视率暴跌 美国最大电视台还能赚钱)
钱童心
随着奥运会临近尾声,收视率统计也陆续出炉。 据彭博情报机构统计的数据显示,里约奥运会直播收视率在18岁至49岁人群中下滑25%。这印证了美国NBC Universal CEO Steve Burke的猜想:“试想有一天我们醒来的时候,收视率一下子下滑20%,这将是一场噩梦。我的猜测是千禧一代都已经转向了Facebook和Snapchat的平台,他们甚至不知道奥运会已经来到。”

传统收视人群变老
NBC是美国三大电视台之一,也是美国历史最悠久的电视台。虽然事实没有Burke想象的那么糟糕,但是也相差不远了。根据彭博情报机构统计的数据,NBC黄金时段奥运体育赛事的收视率比四年前伦敦奥运会下滑17%,18岁至49岁人群的收视率下滑25%,这也是2000年以来,夏季奥林匹克运动会收视率的首次下滑。同时意味着奥运会的收视人群正在变老,这是广告商所不愿意看到的,广告商更想触及的人群是年轻的千禧一代。

NBC花了120亿美元拿下了到2032年为止的奥运会美国独家转播权,就是为了赌体育直播赛事的影响力。其它的广播公司,包括迪士尼的ESPN、21世纪福克斯、时代华纳和CBS则致力于长期的足球、篮球和橄榄球运动的转播。
奥运收视率的暴跌让过去一个看起来理所应当的事实受到了质疑:是否所有具有影响力的体育赛事直播的受关注程度都会永远保持下去?以奥运会为例,一些专业人士认为,奥运会从来都不是美国收视率最高的体育赛事,但它在全球的影响力不可小觑。资深体育业内人士龚华对第一财经记者表示:“美国人的收视习惯是看职业联赛,对奥运会的热度一向不高,除了一些热门的田径或者游泳比赛收视率可能会高些,但是在中国就不一样了,奥运会仍然是老百姓十分关注的体育赛事。而且在欧洲,奥运会的受关注程度也会随着金牌数的增加而递增。”
让人确信的一点是,很多运动还是会长时间持续风靡下去,比如每年2月美国举行的超级碗吸引着1.12亿的观众,这在整个电视历史上都是收视率排名第三的体育赛事节目。不过也有些运动的收视率一直在下滑。比如美国北卡莱罗纳州校园男篮冠军赛今年的收视率就比去年同期下滑超过37%,但是现场观众人数依然达到了74340人。
电视收视率下滑的一个原因是运动迷的年龄开始增大。根据博客网站Stratechery创始人Ben Thompson的统计,过去10年NFL(美国国家橄榄球联盟)和MLB(美国职业棒球大联盟)赛事直播的收视人群平均年龄分别增加了5岁和7岁。“运 动在年轻一代的人群中没有根深蒂固的概念。”研究机构BTIG Research分析师Brandon Ross表示,“它被其它的娱乐项目,包括电子游戏、电竞和Snapchat这些网络内容所替代了。”
网络吸引“千禧一代”
NBC Sports主席Mark Lazarus表示,NBC希望通过给观众不同的收视选项,从奥运会的投资中盈利。比如今年NBC就进行了长达6000小时的网上直播,并且允许美国新闻聚合网站BuzzFeed运营奥运会的Snapchat频道。
截至到上周二,NBC称NBC Sports的App和网站流媒体直播的独立用户数量达到7800万,比四年前伦敦奥运会上升了24%。电视转播方面,尽管NBC收视率下滑,但仍然好过其竞争对手。“NBC电视转播的收视人群中,18岁至49岁的观众数量比我们三家竞争对手加起来还多。”Lazarus表示,“全球奥运会98%的观众仍然是收看电视转播的,但是我们也考虑到年轻的千禧一代,黄金时段通常是他们自己做主的时间(My time),他们希望以自己的方式观看比赛,这也是为什么我们要不断去适应这些人群的收视行为,让我们的转播渠道更加多样化。”
时代华纳旗下特纳(Turner)CEO John Martin表示:“电视台也需要非常谨慎地去平衡,因为网络的直播会分走一部分原本属于电视的流量。”他进一步说道,网络直播会潜在地稀释线性网络的观看率。“而且或许是因为网上的内容会相对较少,人们最后还是被迫要再回到电视上观看,我不知道这是否会反过来提高电视的收视率。”
NBC Sports的Lazarus对此表示部分赞同,但是他说道:“如果NBC不采取流媒体直播,那些纸媒又会说我们藏着内容不发,所以我们必须要寻求最好的平衡。”PPTV体育首席内容官娄一晨对第一财经记者表示:“奥运会版权在NBC手上,要做网站直播也只能由NBC旗下网站才可以,其它电视台和网站只能播新闻,或者延时。”
今年奥运会期间,央视也在旗下CNTV网站上推出网络奥运直播。对此,龚华表示:“网络对电视的冲击主要反应在广告上面,今年中央台把欧洲杯、奥运会直播都握在手中,没有分销给别家,就是因为在广告方面特别注意保护自己独家的利益。” 他还表示,目前网络直播的质量肯定还是无法和电视比。“这也是为什么像PPTV、乐视这样的企业一直在推广自己的电视机。”
“NBC对网络广告商的要价比电视要高出50%,因为网络的用户更加年轻,是广告商希望触及到的千禧一代群体。”Lazarus表示,“但是我们两个平台的广告都卖得非常好。”NBC方面透露,伦敦奥运会的收入约为1.2亿美金,今年里约奥运会卖出去的广告翻了十倍,超过12亿美金,因此利润也将比四年前高很多。
广告买主Amplify US首席本土投资官Andy Donchin表示:“奥运会的效应还是巨大的,虽然观众的质量可能没有过去高了,但是在这样一个碎片化的媒体时代,奥运的收视人群数量总体还是非常可观的。我们会继续买广告,以触及更多的人群。”
但是由于电视收视率的下滑,NBC不得不送一些免费的广告时间给广告商,以弥补用户开机时间的不足。NBC承诺的收视率是2100万美国家庭的平均开机率,不过截至上周,知情人士数据称,开机率仅为1820万。广告公司Deep Focus创始人Ian Schafer表示:“NBC还有两年时间来找出经济学规律。”韩国平昌冬季奥运会将于两年后举行。
 本文来源:第一财经日报责任编辑:王凤枝_NT2541
本文来源:第一财经日报责任编辑:王凤枝_NT2541
http://tech.163.com/16/0822/08/BV2E2T8D00097U7R.html
作者: 万家凝 时间: 2016-9-11 00:54
【案例】
10个做数据新闻的常见错误,你犯过几个?2016-09-09 09:25 [url=]#新媒体[/url] 0阅读量:( 5)
摘要:当然了,每一次犯错都会帮助你成为一个更好的数据记者。
当然了,每一次犯错都会帮助你成为一个更好的数据记者。

作者:Sean Mussenden
数据新闻记者,马里兰大学数据和图表教授
错误1:高估数据的意义
在点开excel之前,数据新闻记者就应该充分认识到手中数据的局限性,只有知道它不能做什么,才能更准确地发挥它的作用。
“在数据分析这一步,记者会慢慢发现,数据的质量完全取决于收集它的方式,因为数据是死的,而人是会犯错的。”
数据来源的可靠性一定要再三确认,比如在处理有关人口的数据时,自报的种族类别要比第三方的判断更为准确。
如果对某些数据的完成性抱有疑问,那还不如干脆不用,或者向读者解释清楚。另外不足100条的数据也最好别用,因为哪怕一个小小的误差对于这样的数据量都是沉重的打击。
在所有的数据工作中,对事实的核查都是十分重要的,如果得到的结论有悖于常理,一定要反复检查每一个步骤,以确保结论的可信性。

错误2:文件格式傻傻分不清楚
了解文件的大小和类型至关重要,因为它可以帮助你确定使用什么工具来处理。
理想状态下Excel能应付700MB以下的文件(.xlxs),但如果文件太大就要考虑使用Access或者其他数据库应用(.sql)了。
后缀为.csv(comma-separated values)的文件也可以用Excel打开和处理,不过在处理的时候如果添加了多个工作表,那一定要记得保存成(.xlxs)格式,否则你会失去其他几个工作表。而其他的程序像MySQL,在上传时一般会要求你另存为CSV格式。
有的时候数据会以纯文本(.txt)的格式下载,这样的数据是无法以行列处理的,所以最好及时用Excel保存以便以后使用。
PDF是可编辑性最差的格式了,碰到这样的文件你就需要像Tabula这样的转换的工具了,转换出可编辑的行列才能进行之后的步骤。

错误3:忽视第一步——清洗数据
终于完成了各种准备步骤,你大概已经迫不及待地要开始处理了,不过先别慌,准备工作还没完。因为几乎所有跟数据有关的工作都是以数据清洗开始的,Mussenden推荐用在线的平台比如OpenRefine进行这一步,这样可以随时同步以免不必要的差错。
另外在处理的过程中比如筛选关键词、将完整地址切割为结构化数据等等各种方法都可以在https://exceljet.net/formulas这个网站上找到~

错误4:把数据搞得乱七八糟
大多数数据都会按照一定的顺序排列,字母顺序、日期或是其他的顺序。但当你拿到数据的时候,它们的排列顺序对于你接下来的工作来说,往往是不尽如人意的。
这时,充分利用Excel中的排序功能就十分重要了,但是需要注意的是,一旦你搞砸了想恢复之前的状态可没那么容易了。所以避免不必要的麻烦,最好在一开始把每一行编号,这样想回复的时候只要按编号排序即可,妈妈再也不担心我把数据搞乱了!

错误5:假装自己理解字段的含义
无论你的数据有多简单,都别太过自信,字段目录是一定要建立的。这份数据有哪些字段,它们分别是什么属性,包含哪些数据……它可以让你对数据形成全局性的把握。如果拿到一份没有字段目录的数据,别嫌麻烦,找它的提供者问个底儿朝天,别自己还稀里糊涂地就盲目地开始工作。
即使当一切都看起来十分完美,也别掉以轻心,再次认真核查永远都不会错。
“我几乎每次开始处理数据前都会保证充足的沟通,即便对数据已经足够自信,可是往往在沟通之后又会得到新的认识。”

错误6:忘记把每一次改动建立新的副本
数据分析是最有可能一着不慎,前功尽弃的工作,一旦在某个步骤出错一下覆盖了之前的版本,那想退回去可就难啦。所以为了避免这种毁灭性的错误,一定要在每一个阶段建立副本以备不时之需。比如:原始数据.xlsx、6月20日版本.xlsx等等。
永远永远不要修改原始数据,万一找不回来了连重头再来的机会都没有了。

错误7:急功近利 废寝忘食
为什么废寝忘食的工作也有错呢?因为数据分析的工作很难给你再次检查的机会,因此保证高质量的工作才是唯一的选择。劳逸结合,别一味图快,一旦发现问题想快速解决就没那么容易了,甚至还要退回到更早期的版本重新来过。与其纠错的时候着急,还不如慢慢做,高质量地完成。Mussenden的经验是每过一个小时休息十分钟。当然了,你会找到自己的工作节奏的。

错误8:数据分析环节被割裂开来
数据新闻项目的编辑可能并没有坐在数据分析师的对面,他可能也不想盯着Excel表格看,但这不代表编辑可以独立于数据分析环节之外。数据新闻的每一个环节都离不开对主旨和大方向的把握。
优秀的数据新闻记者应该有明确的日程安排,其中既包括他自己的工作,也包括团队里每一个成员的工作安排。这对于团队的协同运行是极为有利的,因为团队合作不只是单个人的加总。

在进行复杂的工作时,Mussenden总是要求学生在项目开始之前列好详细的计划,当他们的工作停滞不前的时候,就可以回顾最初的想法,并及时作出调整。另外,团队内部频繁的会议也可以让所有人保持信息的一致性,随时交流最新的想法。
错误9:把数据可视化留到最后
绝大多数数据新闻的项目都是从最基础的统计量开始的,比如均值、中位数、极值等等,但是算完这些简单的数后,则会一时失去方向。
这个时候尝试做一些简单的可视化,像Excel里自带的一些图表,也许能给进一步的探索找到方向。
“这样的尝试可以看到纯数字无法看到的东西,也会有很大的可能性优化你最终的作品。”

错误10:放着资源不用
即使你是编辑部唯一的数据记者,你也有大量的资源可以使用。很多工作都会有在线的教程和业界自发形成的论坛,在那里会有很多业界的高手分享经验。就拿数据分析来说,Excel论坛(http://www.excelforum.com/)和MySQL论坛(http://forums.mysql.com/)都是不错的选择。

总之今天我们要面对越来越多与数据相关的工作,理解数据的短处并用好它的长处,才能将数据的用处发挥到极致。
本文由百度新闻实验室(id:baidunewslab)独家编译,版权归原作者所有,转载请注明来源。
编译:刘建坤
编辑:邵琦
http://mp.weixin.qq.com/s?__biz=MzA3MDA3MjQ1MQ==&mid=2655615416&idx=1&sn=331eb733af5fd8a47bd6b5ef14be7a27&chksm=857fb854b20831421c8bb3a722a4399cf2eccf967d687bdcb0b0cef0fe5837a8520a17e7be77&scene=1&srcid=0909p8oW4MrE96plQugHh2lD#rd
作者: 万家凝 时间: 2016-11-7 22:37
【案例】
数说社交媒体营销汽车商报2016-11-07 14:34:10[url=]阅读(106)[/url]评论(0)
大多数企业家都知道应该在社交媒体上表现得比较活跃。社交媒体的应用达到了前所未有的高度,各大企业需要在客户经常访问的网络平台上占有一席之地。
而怎样是有效的社交媒体营销,有哪些被社交媒体活动实例印证了的数据?被《时代周刊》评选为营销专家、以企业家和风投投资之间的连接者角色而闻名的John Rampton写了一篇文章。本报摘取了其中最具社交媒体影响力和重要性的数据案例。
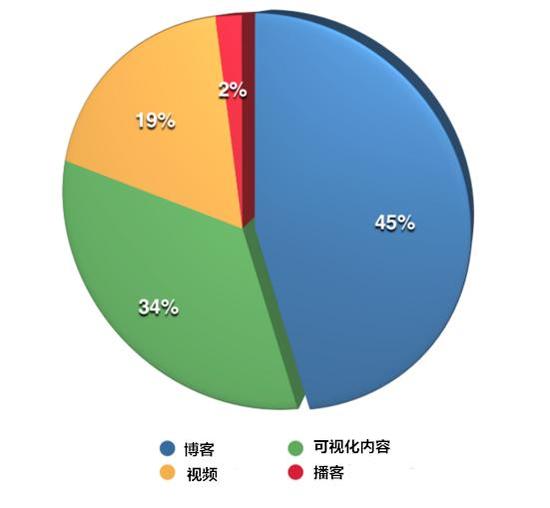
28次
在 Facebook 上很难定义怎样才算得上是很好的互动。然而,根据社交媒体数据分析工具 Social Bakers 提供的研究数据,平均一家企业主(有 0-9999 粉丝的企业 Facebook 账号)每发布一则消息就和粉丝达到约 28 次互动。如果你的公司明显少于 28 次,你可能需要重新审视社交媒体营销策略。
4亿
你以为新入局的社交媒体 Instagram 只是流行一时吗?目前,Instagram 在月度活跃用户的数量上已经超过了 Twitter。在最近的一次统计中,Instagram 用户达到了 4 亿,相比之下 Twitter 只有 3 .2 亿人。
2.4 小时
在全球社交媒体用户中,平均每个用户每天花 2.4 小时参与社交媒体的各种活动。
2.6%
在 Facebook 上发布的贴文触达率很可能处在历史新低。Locowise 的研究数据显示,目前每个 Facebook 主页贴文的平均触达率只有 2.6%。
45%
视觉化内容显然是社交媒体营销的重要组成部分。然而《社交媒体考察者2015年度报告》显示,博客成为最重要的内容推广形式,占比45%,接下来是可视化内容,占比34%,第三才是视频,占比19%。
73%
在所有推广的渠道中,73%的营销人员表示他们正在增加对视觉效果的使用。视频往往能带来高度的互动,最高交互比例达到 13.92%。
500万
迪斯尼主题乐园的视频广告凭借超过 500 万人次点击量,成为 2015年最成功的视频广告。想要借鉴经验吗?幽默和惊喜的元素依然非常管用。
1/3
根据 We Are Social 公司的研究数据,现今活跃的社交媒体用户数量大致等同于 29%的全球人口总量。换句话说,全球近 1/3 的人口活跃在社交媒体上。
http://auto.sohu.com/20161107/n472499874.shtml
作者: 万家凝 时间: 2016-11-12 20:37
【案例】图解:数据揭秘“双十一”

http://china.huanqiu.com/article/2016-11/9669916.html
作者: 万家凝 时间: 2016-12-5 23:26
【案例】
美国主流媒体数据新闻走向原创 2016-12-05 张彧 传媒评论
美国之行,14日求知。
临行前一天,恰逢钱江晚报转型动员大会,钱江晚报总编辑李杲在大会上,为晚报的全面转型升级上了“加急”的标签。在转型的十字路口,图存图兴的导火索已经点燃,留给传统纸媒的时间越来越少,我们没有退路。
如何转型?怎么突破?谁也没有标准答案,但嬗变已在加速——
与一年前不绝于耳的“断崖式下跌”、“纸媒纸没”的四面楚歌不同,同样经历了彷徨失措的美国主流媒体,已把“全球同此凉热”的自怨自艾抛在了身后,而是迅速将目标聚焦在专业性要素力量的重新整合,抓住信息处理的专业要求,重拾传统媒体的传播优势。
在不断完善多端输出、多平台流程再造的同时,我们发现从纽约时报到华尔街日报,再至路透社,在他们的新媒体转型之路上,不约而同地将数据新闻可视化,放到了转型抓手的第一位。
其中,成系统和规模的对大数据的应用、对数据新闻的重视,成为他们的一致选择。
电脑给人类社会带来的革命性颠覆,起源于1和0。我辈之筚路蓝缕,也会自数字始吗?
为何要做数据新闻:因为这片蓝海不容再错过
一个屏幕,一个故事。
密苏里学院的迈克·詹纳教授站在屏幕前,侃侃而谈。
在他的眼中,数据早已超越了阿拉伯数字的范畴,而变成了美国媒体赢得受众抢占高地的“指挥棒”:“数据帮我们产生更好的故事,完成更好的数据可视化作品。更重要的是(数据新闻)帮媒体创造了额外价值,和点击率一起扶摇直上的,还有这家媒体的公信力。这是无形的财富。”
美国流行一句谚语:除了上帝,任何人都必须用数据来说话。
华尔街日报的视频总监乔安娜显然是这句话的奉行者:“五年半前,我刚来到华尔街日报工作,彼时,媒体数字化还是一个新概念,但现在已经成了美国各个媒体的标配化思维。数字化,光有网站还是不够的,所有的采编都在从纯文字化到数字化的转变,包括思维上和行动上,如何在新媒体语境下讲好故事。”
有故事就有内容,有内容就有了扳手腕的资本和底气。这是她的潜台词。
媒体进入移动客户端时代,将是一个“以数据来讲故事”的时代,成熟的数据技术的应用,是工具。关键是数据新闻背后带来的内容独创性。
实际上,数据新闻一直是美国记者的看家本领。
1952年一个叫做德怀特的电视记者,在美国哥伦比亚电视台用电脑预测了大选夜的结果,并预测成功。这是有据可查的第一条数据新闻。
1967年,菲利普·梅尔创造了数据新闻的里程碑,他运用了一些社科工具报道了在底特律的一次骚乱。梅尔分析了底特律社区的人口分布,并分析了骚乱的潜在原因,由于他的报道,底特律自由报获得了普利策新闻奖。
实验研究表明,受众需要看到的是符合他们兴趣的新闻,而不是填鸭式的给予。
而数据新闻就是要同时满足两种需求:人无我有,大众关注。
“现在的趋势是社交媒体带来的信息爆炸,让很多人不再依赖媒体的发布。数据记者的理念应该是:人无我有。提供独家新闻的方式,是需要通过角度来叙述他看到的新闻,而不是仅仅做一个文字的搬运工。”
美国调查性记者和编辑委员会执行主任霍维特觉得数据新闻是一片蓝海。
面对“互联网+”时代,数据应用为我国转型中的传统媒体新闻传播提供了全新的生存土壤。传统主流媒体必须放弃“等一等、缓一缓、看一看”的鸵鸟思维,依托具体数据,开发新产品,抢占新市场,满足受众的新需求,否则,没有立足之地。
图片来源:新闻记者《作为开放新闻的数据新闻》
做自己的船长:
数据库的建立,除了人脉还有想象力
数据新闻需要火种。
如同传统新闻报道中的采访环节,数据新闻生产的第一步在于数据的采集与挖掘。
数据来源是摆在数据新闻拓展路上的第一道坎。“记者光有勇气并不够,还需要数据支撑。”霍维特副教授像赶走一只苍蝇般挥了挥手,他认为数据的获取并不是一个被动等待的过程。
在传统概念中,很多时候数据新闻记者颇受数据供应方的掣肘,许多重要数据掌握在政府或者大企业的手中,而这些机构正是记者所要报道(甚至揭露)的重点对象,当数据要讲的故事与数据持有者的利益发生冲突的时候,记者很难获取自己需要的数据。
标榜自由的美国媒体也有同样的困惑。纽约时报数据团队的领军人Sarah Cohen就认为过分依赖政府数据和公司数据是目前数据新闻普遍存在的问题。
但戴着镣铐未必不能跳舞。如何解决数据来源的问题,美国同行为我们做了两种方向的范例——
1、寻找第二信源,借鉴已经存在的结构类似的数据库,甚至可以向学界求助获得技术支持。
“大家想要一些文件数据,可以通过国际资源库来获得,然后和权威部门的数据对比起来使用。”霍维特副教授,举了一个去年他在巴基斯坦做过的数据新闻为例:
他们的政府对记者并不友好。我们当时成功地在网上发现了一些数据,记者写了两个故事:一个巴基斯坦部分地区没有流动水资源,第二个是关于艾滋病数据的。数据的获取并不顺利,于是我们一方面从当地政府获得数据,另一方面我们从国际卫生组织等机构获得数据。有了两手数据,我们可以做这样的报道:政府告诉我们是这样的,而从另一种渠道获得的信息是这样的。读者对于两种结果,都有阅读权。
巴基斯坦HIV数据报道
在他的实践操作中,大量来自国际组织、第三方机构甚至学界研究的第二信源,已经越来越多地被数据记者所采用。
2、发挥想象力,建立自己的数据库。
在这次访学中,给我留下印象最深的,是美国同行们思考问题、切入选题的角度。《今日美国》的调查性记者Meghan Hoyer就建议数据记者们“做自己的船长”,建立自己的数据库。
这并不是天方夜谭。你看,这是获得过普利策奖的案例,也为多位老师所推崇——
2013年,太阳哨兵报凭这篇数据新闻拿下了年度普利策公共服务奖。事件报道的缘起可追述到2011年,在佛罗里达州劳德代尔堡发生一起恶性交通事故,肇事者为一名退役警察,原因是超速行驶。

2013年太阳哨兵报获得普利策奖的数据新闻
当时记者们在编辑部内进行内部讨论,大家都觉得警车平时经常超速,那么问题来了,如何将这个想法做成一个报道呢,因为警察超速是没有罚单记录的。
最终他们决定自己建立数据库,切入角度很巧妙:美国高速公路大多数免费,少数收费。如果政府专用车,在经过这些收费站时可以直接通过,因为车里有一个装置。像这样一个装置,会记录每一辆警车开过时的行进记录,久而久之形成了一个数据库。记者就向政府部门要到了一定时间内的收费站记录,得到了经过这些收费站的警车的经过时间、路线等等。
之后记者就自己开车经过这些收费站,用智能手机记录了经过这些收费站的距离和时间。再利用自己手上的数据,测算出了警车的速度。
最后得出结论:超过800辆警车都超速,甚至速度超过130迈/小时,但从未收到过罚单。其中有21个人因为警车超速而死亡或重伤。
报道引起了社会大讨论,迫使佛罗里达州警务部门进行内部大整顿。一年之后,当地超速个案从3000多宗下降到400多宗。
数字的力量,简单而有效。
这个例子背后说明了记者数据库的建立带来了独立性。从数据收集、建模分析、可视化呈现到文章写作,独立平台一手包办,对选题的掌控和主导权大大增强。
我不得不说初见这样的新闻调查方式,确实有四两拨千斤之感。
数据的惊艳,来自于讲故事的方式
可视化就像是一场篝火晚会,我们都坐在他周围听故事。——Al Shalloway
数据新闻的表现形式千变万化,没有一定之规。像世界公认的数据新闻“豪门”英国卫报应用最多的形式是数据地图、时间轴以及交互图表,其中数据地图为卫报赢得了最多的喝彩。
而在美国主流媒体中,数据新闻的呈现方式就更为多样:纽约时报的多媒体项目大多喜欢采用的是一拉到底不断更新的长幅专题,既做到了信息要点全覆盖,也表明了自己不愿在追热点新闻上花力气的态度。
与之相反的是华盛顿邮报,它在突发新闻的处理上很有自己的风格:大号字体、鲜明颜色、响应式设计,以及原创的插画。
而美联社的数据新闻则有点类似纽约时报,习惯采用长幅设计,涉及图片、视频、图表和文字的整合,长幅滚动式设计已经成为其标志性的数据新闻表达方式。
惊艳,不仅仅源于数据的展示方式,更多的还是来自于数据报道执行的切入点和数据可视化的运用。
这个案例讲的是美国某地不断升高的海平面。在美国,海洋的减少、海平面上升,是很热的环境话题,很多专家都不相信,这是正在发生的事实。而这个报道关注的正是美国某地不断消失的土地。
这个数据新闻的表现形式很酷炫,但本质上其实都是非常基本的数据。记者在网站上建立了互动图表,可以在海岸线上展示地理位置,利用互动性图片,进行对比,原来和现在这个地方的变化只要动动鼠标就能“动起来”给你看。
这是用照片叠加做出来的效果,很直观,在技术上也不难实现。
第一层的图片,是用航拍器拍的1930年时美国这块地方的样子,绿色是土地,蓝色是海洋。而后几层图片则是卫星图片拍到的近几年的地形地貌。通过时间推移,可以很直观地看出变化。
像这样的卫星图片,在美国在国际上是公开的,甚至于说如果你不会叠加,很简单一一列出就很有直观性了。
更难得的是,地图可以随意缩放,鼠标点击红点后则会弹出窗口,显示时间、地点、演变原因等详细信息。地图特有的冲击力取代了冷冰冰的数据罗列,而其独特的故事性则远比一切文字的煽情更触动人心。
让新闻动起来,融媒转型的优质抓手
这不仅是新闻表达方式的创新,更是吸引年轻受众,创造不同的业界价值的途径。而作为钱江晚报整体转型的当口,我们需要打造自己与众不同的内容深耕品牌,需要在业界拿出独创性的新闻类型。
我们要做的数据新闻,其实不仅仅只局限于传统“数读”,而更像是一种新闻线索资源的深入拆解和动态表达。
在我的理解中,在我们的融媒实验中,这是可以动起来的新闻——
它可以是一次突发热线的动态展示,需要聘请专业美编和视频团队,进行虚拟现实拍摄或360度摄影,而不仅仅局限于原来的2D平面的表达);
它也可以是对新闻话题的深入延展,可以通过图表、数据对比等等手段,用图表的方式来做深度报道;
它还可以是对消息的全新表达,比如现在美国媒体特别流行的“验证新闻”,在大选新闻中,希拉里和特朗普的重要辩论中,任何一个数字或者提法,都会被数据新闻进行核实或深入解读,直接呈现。也就是说一篇1000字新闻它可以有很多个内容模块的再延展。
要实现这一点,就需要建立自己的数据新闻平台,它所需要的,不止是一个有新闻经验的编辑、一个懂读者的设计师、一个能够独立快速写代码的程序员,而是一种全新的新闻生态。
当然,在这个过程中,我们需要建构的数据新闻流程还有很多空白:比如脏数据如何清洗、如何确定数据维度、被动假设与无知假设等,都是最基础核心又往往被忽视的数据素养问题。
此外移动时代的数据新闻还需要因屏幕限制而重新设计表现思路、考虑用户习惯而需要舍弃多重信息等等。
几年后,新闻事实为骨,数据分析为血肉的新闻模式是否会变为如通讯、社论等一样的媒体常态,我们不得而知。
但争夺数据新闻阵地的枪声已然四起,美国媒体进入了刺刀见红的搏杀阶段,而我们也不该再仅仅报以最真切的期待,作为新媒体转型期内容生产的优质抓手,我们更该一跃而入,在这片数据的蓝海中撒点野。
来源:《传媒评论》杂志2016年第11期
http://mp.weixin.qq.com/s?__biz=MjM5MjE2NTA3MQ==&mid=2649882815&idx=1&sn=75486ea190a1f11931995d08407629c7&chksm=beacdd1f89db540992efd8b3f22477f403588ed6bebef22c54c86184ef1a8e957ad30e76cbe0&mpshare=1&scene=23&srcid=1205G9Y3ncdrWlo8qkjNe8Rd#rd
| 欢迎光临 传媒教育网 (http://idealisan.eu.org/) |
Powered by Discuz! X3.2 |







































 Figure 1. Next-gen sequence data size compared to SPECint.
Figure 1. Next-gen sequence data size compared to SPECint. Figure 2. The Big Data analysis pipeline. Major steps in the analysis of Big Data are shown in the top half of the figure. Note the possible feedback loops at all stages. The bottom half of the figure shows Big Data characteristics that make these steps challenging.
Figure 2. The Big Data analysis pipeline. Major steps in the analysis of Big Data are shown in the top half of the figure. Note the possible feedback loops at all stages. The bottom half of the figure shows Big Data characteristics that make these steps challenging.








































